
<стр>Узнайте, как новые компании могут добиться заметности в результатах поиска, генерируемых ИИ, и повысить свои шансы на видимость ИИ.
Спонсором этого поста является No Fluff. Мнения, выраженные в этой статье, принадлежат спонсору.
Когда ChatGPT, Gemini и Perplexity упоминают компанию, эти большие языковые модели (LLM) решают, можно ли ссылаться на эту компанию, а не как долго она существует.
Большинство бизнес-лидеров предполагают одно, когда они не появляются в ответах, генерируемых ИИ:
Мы слишком новички.
<п>На самом деле раннее тестирование на нескольких платформах ИИ предполагает, что происходит нечто иное. Во многих случаях проблема less связана с возрастом компании и в большей степени с тем, как системы ИИ оценивают структуру, повторение и сигналы доверия.
В результатах поиска ИИ могут упоминаться новые бренды.
В этом руководстве
- <ли>1. Почему большинство новых компаний не появляются в результатах поиска ИИ
- 3.6 Схемы, наблюдаемые при раннем тестировании видимости ИИ
- <сильный>Немного сигналов доверия
Мало обратных ссылок, обзоров или прессы, поэтому вы не “смотрите” еще заслуживает доверия. - <сильный>Смешение торговых марок
Подобные или общие торговые марки легче спутать, неправильно атрибутировать или вообще пропустить системам искусственного интеллекта, если сигналы доверия слабы. - <сильный>Непонятное позиционирование
Неясное позиционирование или идеи, которые появляются на веб-сайте компании только один раз, вызывают меньше доверия. - Появилось в <сильных>5% соответствующих ответах ИИ.
- Отображается в <сильных>39 из 150 вопросов.
- Упоминается 74 раз, при этом 42 цитируются упоминания.
- 6% точность цитирования, ~11% указание на собственный сайт бренда.
- Четко определите свой бизнес, используя семантические тройки: Используйте [Тема] → [Предикат] → Формат [Объект] (например, “Бренд
- <сильный>Придерживайтесь общедоступного, широко понятного языка:Возьмите терминологию из широко распространенных источников, таких как Википедия или Викиданные. Если вы описываете свой продукт, используя внутренний жаргон, который не соответствует общепринятому определению категории, вы рискуете быть неправильно классифицированным или упущенным из виду.
- <сильный>Укажите свой авторитет: Определите, почему ваш бренд заслуживает доверия. Какие факты, свидетельства и доказательства подтверждают вас? Напишите 3–5 простых, основанных на фактах утверждений, благодаря которым вы хотите, чтобы вас знали.
- <сильный>Определите свою конкурентную контрпозицию: Четко определите, что отличает вас от других. Охватите конкретную нишу, которой вы владеете (аудитория, проблема, точка зрения или предложение), которая отличает вас от альтернатив.
- <сильный>Составьте карту конкурентной среды: Определите, на какие бренды системы искусственного интеллекта уже ссылаются, вопросы покупателей реально выиграть, и где язык категорий создает путаницу.
- Вопросы покупателя при реверс-инжиниринге: Определите, как покупатели формулируют реальные вопросы, используя анализ ключевых слов и конкурентов (данные инструментов SEO, People Does Ask, Google SERPS и сами запросы к нескольким механизмам искусственного интеллекта)
- Заблокируйте свой набор данных: Создайте фиксированный набор из 150 вопросов, аутентичных для покупателя, в шести кластерах: «Бренд», «Категория», «Проблема», «Сравнение» и «Расширенная семантика».
- Начать тестирование: Запускайте эти подсказки еженедельно в ChatGPT, Gemini и Perplexity, чтобы отслеживать упоминания и рост цитируемости.
- Реализовать схему JSON-LD: Используйте схемы организации, сервиса и часто задаваемых вопросов, чтобы точно сообщить ИИ, кто вы и чем занимаетесь.
- Разверните txt файл: Поместите его в корень своего домена, чтобы предоставить ИИ-сканерам руководство в виде простого текста, сообщающее им, как описать вашу компанию и какие страницы использовать. расставить приоритеты.
- Начните с ответа: Начинайте каждый раздел с прямого, основанного на фактах ответа.
- Семантически разбивать на части:Разделите контент на логические, независимые разделы, которые ИИ может извлечь и повторно использовать, не требуя контекста всей страницы.
- Учитывайте фактор свежести: ИИ предпочитает контент, обновленный в течение последних 60–90 дней. В секторах с высокой конкуренцией, таких как SaaS или финансы, контент должен обновляться каждые три месяца, чтобы оставаться «доверенным». рекомендация.
- Заявите профили каталогов: Выровняйте данные вашей сущности в Crunchbase, G2, LinkedIn и Yelp. Несоответствия между этими профилями являются основной причиной галлюцинаций ИИ.
- Целевые авторитетные упоминания:Обеспечьте себе упоминание в отраслевых публикациях с постоянным откликом на все ваши запросы и/или высоким рейтингом домена.
- Внешнее подкрепление: Для каждой важной страницы вашего сайта стремитесь к как минимум трем намеренным внешним обратным ссылкам из авторитетных источников, чтобы вызвать срабатывание ИИ.
<ли>2. Доказательство того, что новые компании могут появиться в поиске ИИ
<ли>4. Шаги по созданию нового бизнеса для видимого успеха ИИ <ли>5. Главный вывод: расставьте приоритеты в пользу власти как долгосрочной игры
<п>Даже хорошо продуманные продукты с реальным опытом обычно отсутствуют в рекомендациях ИИ. Тем не менее, когда покупатели спрашивают, кому доверять, продолжают появляться одни и те же устаревшие имена.
Почему большинство новых компаний не отображаются в результатах поиска ИИ
Это не случайно.
Системы искусственного интеллекта опираются на существующие данные обучения и видимые цифровые следы, что отдает предпочтение брендам, о которых цитируют уже много лет. Поскольку каждый ответ несет в себе риск, эти системы действуют консервативно.
Они не ищут наиболее оптимизированную страницу; они ищут наиболее <сильную>проверяемую сущность. Если ваш след невелик, непоследователен или плохо поддерживается третьими лицами, ИИ часто заменит вас на конкурента, которому ему легче доверять.
Большинство новых предприятий запускаются с:
<ул> <ли><сильный>Минимальные исторические сигналы
Очень мало онлайн-контента и упоминаний, поэтому ИИ почти не с чем работать.
Вместе они создают ненадежные сигналы.
В генеративном поиске видимость зависит не столько от ранжирования, сколько от рассуждений.
<п>Вот почему большинство новых брендов не оцениваются как «плохие». но слишком неопределённо, чтобы можно было безопасно ссылаться на него.
<стр>Это различие имеет значение. Упоминание со стороны ИИ — это не просто разоблачение; это влияет на то, кого покупатели считают заслуживающими доверия еще до того, как они попадут на веб-сайт. Посетители, привлеченные искусственным интеллектом, часто конвертируются быстрее, чем традиционный органический трафик.
Для новых предприятий отсутствие устаревших сигналов не является «просто недостатком». При правильном обращении это может стать возможностью для установления ясности и доверия быстрее, чем у более старых конкурентов, которые полагаются на устаревший авторитет.
Доказательство того, что новые компании могут появиться в поиске ИИ [Эксперимент]
<п>На удивление мало информации о том, может ли новый или растущий бренд появиться в ответах, генерируемых ИИ. Учитывая, насколько эти системы зависят от сигналов прошлого, легко предположить, что авторитетные компании появляются по умолчанию.
Чтобы проверить это предположение, совершенно новую B2B-компанию отслеживали с момента запуска в рамках 12-недельного эксперимента по видимости результатов поиска с использованием ИИ. Приведенные ниже результаты отражают <сильных>первые шесть недель текущего теста. Компания начинала без предшествующей истории, без обратных ссылок и без освещения в прессе. Настоящий ноль.
Видимость измерялась по 150 запросам в стиле покупателя в ChatGPT, Google AI Reviews и Perplexity, а не определялась на сторонних информационных панелях.
Используя еженедельные GEO-спринты, сосредоточенные на технических основах, контенте, ориентированном на ответы, и усиливающих сигналах, таких как социальные сети, видео и ранние обратные ссылки, цель заключалась в том, чтобы увидеть, насколько далеко <сильный>лучший практический метод GEO может продвинуть по-настоящему новый бренд.
В течение шести недель развивающийся бизнес добился следующих результатов:
<ул>
6 закономерностей, наблюдаемых при раннем тестировании видимости ИИ
В течение первых шести недель шесть закономерностей последовательно влияли на то, был ли бренд включен, заменен конкурентом или полностью исключен из ответов, генерируемых ИИ:
Шаблон 1: Структура важнее темы

Изображение создано No Fluff, февраль 2026 г.
Блуждающий контент (даже если он был продуманным или «надежным») постоянно отставал от восприятия ИИ. Страницы, которые были выбраны, были более плотными: они сразу отвечали на вопрос, разбивали содержание на четкие этапы и придерживались одной идеи за раз.
Шаблон 2: Социальный “Усилитель” Эффект <п>ИИ с большей вероятностью будет цитировать источники, которым он уже доверяет. В первые две недели большинство упоминаний приходилось на посты бренда в LinkedIn и Medium, а не на его веб-сайт. Для нового бренда публикация ключевых идей first на авторитетных платформах, включая LinkedIn или Medium, часто вызывает срабатывание ИИ до того, как тот же контент будет проиндексирован на вашем собственном веб-сайте.
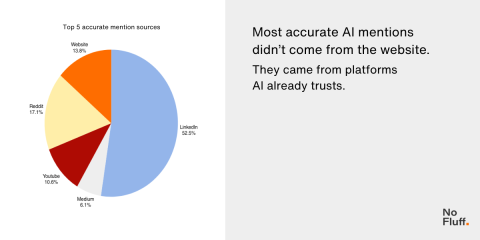
Изображение создано No Fluff, февраль 2026 г.
Шаблон 3: Галлюцинации часто являются провалами сигнала

Изображение создано No Fluff, февраль 2026 год
Когда системы искусственного интеллекта неправильно идентифицируют новый бренд или путают его с конкурентами, причиной обычно являются слабые, медленные или противоречивые сигналы. Когда страницы не загружаются примерно в течение 5–15 секунд, системы искусственного интеллекта выдают более широкое «разветвление». запросы и собирать ответы из смежных или неправильных источников. После улучшения скорости сайта, надежности сканирования и ясности сущности доля ответов, в которых правильно ссылался на собственный домен этой компании, увеличилась, а количество ошибочных упоминаний снизилось.
Шаблон 4: 3-недельное окно индексирования
<п>Первый прием ИИ из нового домена может произойти в течение трех-четырех недель. В этом эксперименте первая страница была обнаружена на 27-й день. После этого первоначального открытия последующие страницы открывались быстрее, с наименьшей задержкой около восьми дней.
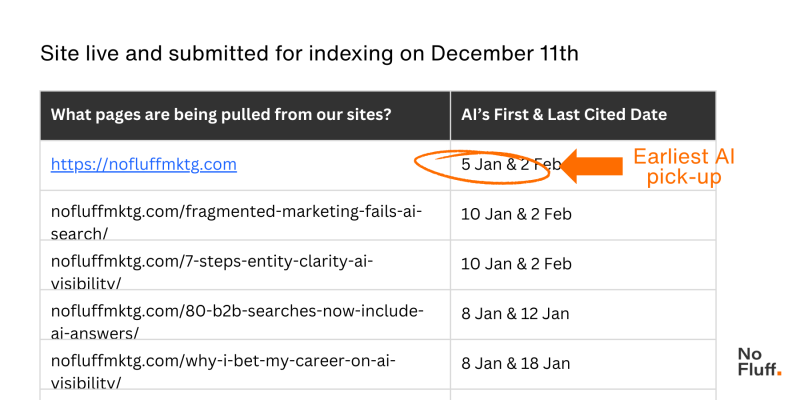
Изображение создано No Fluff, февраль 2026 г.
Раннее включение не было обусловлено объемом контента. Это было обусловлено структурой: надежная схема, согласованные метаданные, чистый, доступный для сканирования сайт и машиночитаемые файлы, такие как llms.txt.
.
Шаблон 5: Сначала выиграйте объяснительный раунд
<п>Новые бренды, как правило, не начинают с победы в условиях жесткой конкуренции на этапе принятия решений, таких как «лучший» или «лучший». или “top” списках, если только предложение не является действительно уникальным или неконкурентным. Прежде чем бренд действительно сможет попасть в шорт-лист, сначала он должен быть использован в качестве основного источника для определения или образовательных вопросов.
В первые 45 дней целью была не сравнительная видимость, а признание и доверие: заставить системы искусственного интеллекта ассоциировать бренд с правильными темами и источниками. Ранний успех лучше всего измеряется частотой цитирования или тем, как часто бренд используется в качестве основного источника по определенной теме.
Шаблон 6: Устранение незавершенного разрыва в доверии (самое важное)
<п>Даже при наличии хорошо структурированного сайта и качественного контента брендам сложно получить рекомендации без внешней проверки. Начальные этапы этого эксперимента показали, что ответы ИИ по умолчанию относились к знакомым доменам и заменяли новые бренды конкурентами, у которых были более четкие упоминания третьих сторон. Это подтверждает важность прессы и авторитетного освещения на ранних этапах. Ожидание “добавления позже” только замедляет доверие.
5 шагов по созданию нового бизнеса для видимого успеха ИИ
К настоящему моменту вывод ясен: видимость ИИ не происходит автоматически, когда сайт работает или запущено несколько кампаний. Хорошая новость в том, что на это можно влиять сознательно. Приведенные ниже шаги отражают последовательность действий, которая последовательно привела новый бренд от нулевой видимости к цитированию в ответах, генерируемых ИИ. Вместо того, чтобы рассматривать видимость ИИ как побочный эффект SEO, этот подход рассматривает его как операционную проблему: как сделать так, чтобы системы ИИ могли легко распознавать, проверять и повторно использовать бренд.
Шаг 1. Составьте карту сущности вашего бренда
Прежде чем создавать сайт, вы должны определить свой бренд так, чтобы его понимали машины. ChatGPT, Gemini и Perplexity не читают ваш сайт так, как это делают люди. Они соединяют факты, имена и отношения в сущности, которые определяют, кто вы есть. Если эти связи отсутствуют или непоследовательны, ваш бренд просто не появится (независимо от того, сколько контента вы публикуете).
<ул>
Шаг 2. Разработайте набор подсказок для эталонного теста
<п>Вы не можете полагаться на традиционные инструменты SEO, предназначенные для отслеживания видимости ИИ. Большинство полагаются на предполагаемые данные или моделирование, а не на реальные подсказки.
<ул>
Шаг 3: Сделайте бренд машиночитаемым
Сделайте свой сайт машиночитаемым, чтобы роботы ИИ не пропускали ваш контент. Системы искусственного интеллекта не заботятся об эстетике вашего сайта; их волнует, насколько легко они смогут анализировать ваши данные. Если ваши технические сигналы слабы или противоречивы, ИИ будет галлюцинировать или подменять ваш бренд конкурентом.
<ул>
<ли><сильный>Устраните проблемы со сканированием: Убедитесь, что ваш сайт полностью доступен для сканирования через robots.txt и что никакой контент не скрыт в закрытых PDF-файлах или изображениях. Самое главное — проверьте скорость сайта с помощью PageSpeed Insights. Модели не терпеливо ждут медленных страниц!
Шаг 4: Публикация “Retrival-Ready” Контент
Напишите для нетерпеливого аналитика (ИИ-бота). Начните с подсказок с высокой эффективностью, вопросов с реальным намерением покупателя, на которые ИИ уже отвечает, но только с использованием небольшого и слабого набора источников, что облегчает влияние на них до того, как доверие полностью закрепится.
<ул>
Шаг 5: Заработайте внешнюю проверку
Системы искусственного интеллекта сверяют утверждения вашего сайта с остальной частью сети.
<ул>
Самый важный вывод: расставьте приоритеты в отношении полномочий как долгосрочной игры
Для новых брендов ограничивающим фактором в поиске с помощью ИИ является не оптимизация. Это авторитет.
Системы искусственного интеллекта с большей вероятностью сначала выявят незнакомые компании, давая пояснительные ответы с низким уровнем риска, а не в «лучших» случаях. “сверху” или подсказки для сравнения. Чистый сайт и хорошее SEO помогают бренду быть узнаваемым, но получить рекомендацию — это другое препятствие.
На практике ранний прогресс заключается в уменьшении неопределенности. Когда бренд постоянно появляется в сторонних статьях, обзорах или других независимых источниках, его становится легче объяснить и безопаснее ссылаться на него. Без этой внешней проверки рекомендации останавливаются, независимо от того, насколько хорош контент или как быстро загружается сайт.
Этот анализ охватывает первый этап 90-дневного тестирования, изучающего, как новый B2B-бренд становится видимым в результатах поиска, генерируемых искусственным интеллектом. Текущие результаты и окончательные результаты будут опубликованы как выводы эксперимента.
ПРОСМОТРИТЕ ПОЛНЫЙ 90-ДНЕВНЫЙ ЭКСПЕРИМЕНТ <стр>Авторы изображений
Рекомендуемое изображение: Изображение No Fluff. Используется с разрешения.
<стр>Изображения в публикации: изображения No Fluff. Используется с разрешения.


