
<п> <п> <п> <п> <п> <п> <п>
Узнайте, почему Googlebot больше не является единственным доминирующим сканером, поскольку ChatGPT-User OpenAI лидирует в веб-запросах.
Спонсором этого поста является Alli AI. Мнения, выраженные в этой статье, принадлежат спонсору.
Все полагают, что Googlebot является доминирующим сканером, посещающим их сайт. Теперь это предположение неверно.
Мы проанализировали 24 411 048 запросов прокси на более чем 78 000 страницах на 69 веб-сайтах клиентов на платформе поддержки сканеров Alli AI за 55-дневный период (с января по март 2026 г.). Сканер ChatGPT-User OpenAI сделал в 3,6 раза больше запросов, чем робот Googlebot, в нашей выборке данных. И это даже не считая GPTBot, отдельного обучающего сканера OpenAI.
Наши выводы & Ваши следующие шаги
- 1. Вывод 1. Поисковые роботы с искусственным интеллектом теперь опережают Google в 3,6 раза и более. ChatGPT лидирует
- 2. Вывод 2: OpenAI использует 2 сканера (и большинство сайтов не видят разницы)
- 3. Вывод 3. Краулеры с искусственным интеллектом работают быстрее и эффективнее. Более надежны, но их объем увеличивается
- 4. Вывод 4. Робот Googlebot видит другую (худшую) версию вашего сайта
- 5. Отраслевые отчеты подтверждают, что в 2025 году объем сканирования с помощью ИИ вырастет в 15 раз
- 6. Ваша новая стратегия SEO: как провести аудит, очистить и улучшить; Оптимизация для роботов-ИИ
- 7. Методология
- 8. О Алли AI
<сильный>Примечание по методологии:Идентификация сканера использовала сопоставление строк пользовательского агента, сверенное с опубликованными диапазонами IP-адресов. Метрики запросов измеряются на уровне прокси/CDN. Набор данных охватывает 69 веб-сайтов различных отраслей и размеров, преимущественно на базе WordPress. Полная методология подробно описана в конце.
Вывод 1: краулеры с искусственным интеллектом теперь опережают Google в 3,6 раза &amp;amp;amp;amp;amp;amp;amp;amp;amp; ChatGPT лидирует
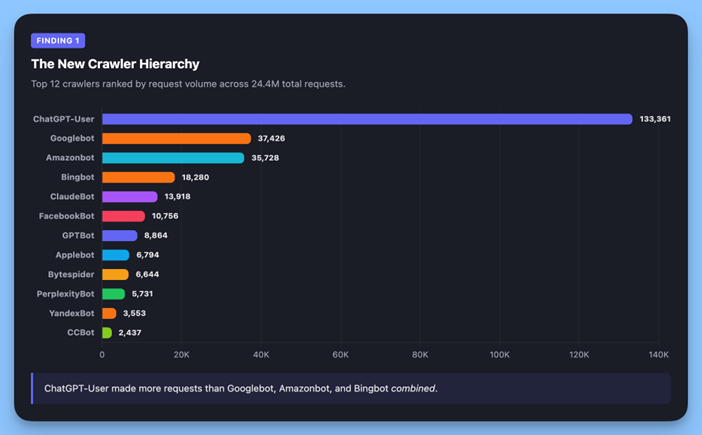
Изображение создано Alli AI, апрель 2026 г. <п>Когда мы ранжировали каждого идентифицированного краулера по объему запросов, результаты были однозначными:
<ширина стола="462"> <тело> <тр>
<тр>
<тр>
<тр>
<тр>
<тр>
<тр>
<тр>
<тр>
<тр>
<тр>
ChatGPT-Пользователь сделал больше запросов, чем Googlebot, Amazonbot и Bingbot вместе взятые.
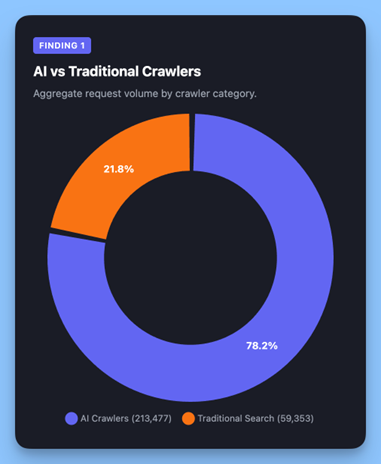
Изображение создано Alli AI, апрель 2026.
Сгруппированные по назначению сканеры, связанные с искусственным интеллектом (ChatGPT-User, GPTBot, ClaudeBot, Amazonbot, Applebot, Bytespider, PerplexityBot, CCBot), выполнили 213 477 запросов по сравнению с 59,353 для традиционные поисковые роботы (Googlebot, Bingbot, YandexBot). Поисковые роботы с искусственным интеллектом теперь делают в 3,6 раза больше запросов в нашей сети, чем традиционные поисковые роботы.
Вывод 2: OpenAI использует 2 сканера (и большинство сайтов не понимают разницы)
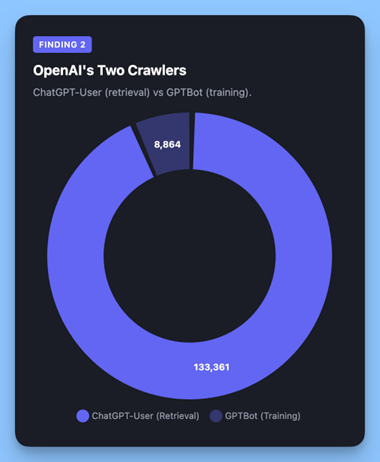
Изображение создано Alli AI, апрель 2026.
OpenAI использует два разных сканера с совершенно разными целями.
ChatGPT-User — поисковый сканер. Он извлекает страницы в режиме реального времени, когда пользователи задают ChatGPT вопросы, требующие актуальной веб-информации. Это определяет, будет ли ваш контент отображаться в ответах ChatGPT.
GPTBot — обучающий сканер. Он собирает данные для улучшения моделей OpenAI. Многие сайты блокируют GPTBot через robots.txt, но не через ChatGPT-User, или наоборот, не понимая конкретных последствий каждого из них.
<п>В совокупности сканеры OpenAI выполнили 142 225 запросов: <сильный>3,8-кратный объем Googlebot.
Директивы robots.txt отдельные:
Пользовательский агент: GPTBot # Обучение сканера — питает модели OpenAI Пользовательский агент: ChatGPT-User # Поисковый робот — извлекает страницы для ответов ChatGPT
Вывод 3: краулеры с искусственным интеллектом работают быстрее и amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp; Более надежны, но их объем увеличивается
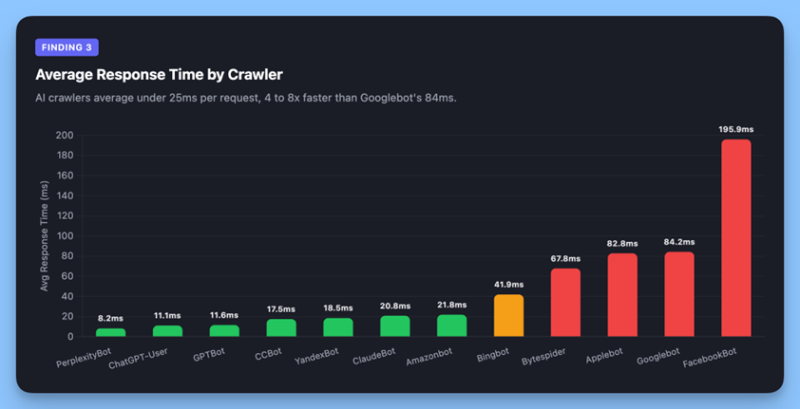
Изображение создано Alli AI, апрель 2026 г.
Сканеры с искусственным интеллектом значительно более эффективны в каждом запросе:
<ширина стола="410"> <тело> <тр>
<тр>
<тр>
<тр>
<тр>
<тр>
<п>Две вероятные причины. Во-первых, поисковые роботы с искусственным интеллектом извлекают определенные страницы в ответ на запросы пользователей, а не исчерпывающе изучают архитектуру сайта. Они знают, чего хотят, берут это и уходят. Во-вторых, хотя все сканеры в нашей инфраструктуре получают предварительно обработанные ответы, более широкий шаблон сканирования Googlebot означает, что он запрашивает более широкий диапазон URL-адресов, включая устаревшие пути из карт сайта и собственный устаревший индекс, что увеличивает задержку из-за цепочек перенаправления и обработки ошибок, которых полностью избегают поисковые сканеры.
Но есть одна загвоздка: хотя каждый отдельный запрос невелик, сам объем означает, что совокупная нагрузка на сервер значительна. Пользователь ChatGPT в 11 мс × 133 361 запрос — это по-прежнему реальные затраты на инфраструктуру, просто они распределяются иначе, чем меньшее количество и более тяжелых запросов робота Google.
Вывод 4: робот Google видит другую (худшую) версию вашего сайта
Изображение создано Alli AI, апрель 2026 г.
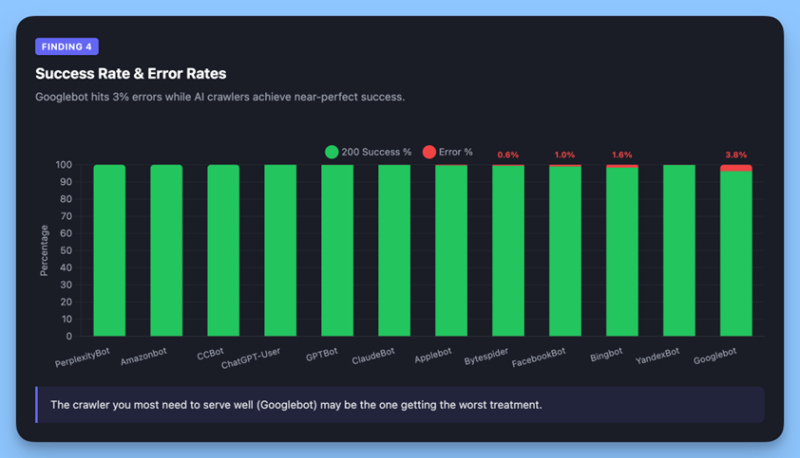
Уровень успеха робота Googlebot в 96,3% по сравнению с почти идеальными показателями для сканеров с искусственным интеллектом показывает важную структурную разницу.
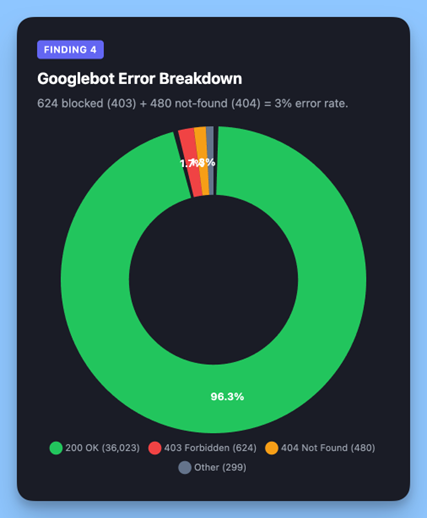
<п>Робот Googlebot получил 624 заблокированных ответа (403) и 480 не найденных ошибок (404), что составляет 3% его запросов. Между тем, пользователь ChatGPT добился успеха на 99,99%. PerplexityBot показал идеальные 100%.
.
Изображение создано Alli AI, апрель 2026 г.
Почему такой разрыв? Наиболее вероятным объяснением является возраст индекса и поведение сканирования, а не неправильная конфигурация сайта.
<п>Робот Googlebot поддерживает огромный устаревший индекс, созданный за годы непрерывного сканирования. Он регулярно повторно запрашивает уже известные ему URL-адреса — включая страницы, которые впоследствии были удалены (404) или реструктурированы (403). Это нормальное поведение для поисковой системы, поддерживающей индекс такого масштаба, но это означает, что значительный процент запросов робота Google направлен на URL-адреса, которые больше не существуют.
гусеничные роботы с искусственным интеллектом не несут такого багажа. ChatGPT-User извлекает определенные страницы в ответ на запросы пользователей в режиме реального времени, ориентируясь на контент, который в данный момент актуален и связан с ним. Это структурное преимущество, которое обеспечивает почти идеальные показатели успеха.
Отраслевые отчеты подтверждают, что в 2025 году сканирование искусственного интеллекта выросло в 15 раз
<п>Эти результаты согласуются с более широкими отраслевыми тенденциями. Анализ Cloudflare за 2025 год показал, что количество запросов ChatGPT-User выросло на 2,825% в годовом исчислении, при этом AI “user action” объем сканирования увеличится более чем в 15 раз в течение 2025 года. Компания Akamai назвала OpenAI крупнейшим оператором ботов с искусственным интеллектом, на долю которого приходится 42,4% всех запросов к ботам с искусственным интеллектом. Анализ сайта nextjs.org, проведенный Vercel, подтвердил, что ни один из основных сканеров искусственного интеллекта в настоящее время не обрабатывает JavaScript.
Наши данные показывают, что это пересечение, возможно, уже происходит на уровне объекта для объектов, которые активно обеспечивают доступ к ИИ-сканеру.
Ваша новая стратегия SEO: как проводить аудит, очищать и amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;AMP; Оптимизировать для краулеров с искусственным интеллектом
1. Проверьте свой файл robots.txt на наличие роботов-ИИ сегодня
Большинство файлов robots.txt были написаны для роботов Google. Как минимум, используйте явные директивы для ChatGPT-User, GPTBot, ClaudeBot, Amazonbot, PerplexityBot, Applebot, Bytespider, CCBot и Google-Extended.
<п>Наша рекомендация: Большинству компаний выгодно разрешить использование обоих поисковых сканеров (ChatGPT-User, PerplexityBot, ClaudeBot) и обучающих сканеров (GPTBot, CCBot, Bytespider), обучающие данные — это то, что рассказывает этим моделям о вашем бренде, продуктах и опыте. Блокировка обучающих сканеров сегодня означает, что модели ИИ узнают о вас меньше завтра, что снижает ваши шансы на то, что вас будут цитировать в ответах, сгенерированных ИИ.
Исключение: если у вас есть контент, который вам особенно необходимо защитить от обучения модели (собственные исследования, закрытый контент), используйте детальные правила запрета для этих путей, а не общие блоки.
2. Очистите устаревшие URL-адреса в консоли поиска Google
<п>Наши данные показывают, что Googlebot достигает 3% ошибок, в основном 403 и 404, в то время как роботы с искусственным интеллектом достигают почти идеальных показателей успеха. Этот пробел, вероятно, отражает повторное сканирование устаревших URL-адресов, которые больше не существуют, роботом Googlebot. Но эти неудачные запросы по-прежнему расходуют краулинговый бюджет.
<стр>Проверьте статистику сканирования GSC на наличие повторяющихся ошибок 404 и 403. Настройте правильные перенаправления для реструктурированных URL-адресов и отправьте обновленные карты сайта.
3. Рассматривайте доступность ИИ-сканера как отдельный канал SEO
Рейтинг в ответах ChatGPT, результатах Perplexity и ответах Клода становится отдельным каналом видимости. Если ваш контент недоступен для этих сканеров, особенно если вы используете платформы с большим количеством JavaScript, вы невидимы для поиска AI.
<п>Мы опубликовали интерактивную информационную панель, показывающую, как распределяется трафик сканеров ИИ на реальном сайте: какие платформы посещают, как часто и их долю в общем трафике; если хочешь увидеть, как это выглядит на практике.
4. Планируйте объем, а не только вес индивидуального запроса
ИИ-сканеры отправляют легкие, быстрые запросы, но отправляют их много. На одного только пользователя ChatGPT пришлось более 133 000 запросов за 55 дней. Совокупная нагрузка на сервер от сканеров AI теперь, вероятно, превышает нагрузку на ваш робот Googlebot. Убедитесь, что ваш хостинг и CDN справятся с этим: низкое время ответа на запрос в наших данных отражает тот факт, что Alli AI обслуживает предварительно обработанный статический HTML-код с периферии CDN, а это именно та архитектура, которая поглощает этот объем без нагрузки на исходный сервер.


