
<стр>Узнайте, как раскрытие информации Министерства юстиции об испытаниях объясняет использование Google систем ранжирования на базе искусственного интеллекта и почему удовлетворенность пользователей перевешивает векторную оптимизацию.
<с>Давайте посмотрим, смогу ли я вас убедить!
Я поделился многим в этом видео и суммировал свои мысли в статье ниже. Кроме того, это вторая запись в блоге, написанная на эту тему за последнюю неделю. Гораздо больше информации о пользовательских данных и о том, как Google их использует, можно найти в моем предыдущем посте в блоге.
<п>
Рейтинг состоит из 3 компонентов
В ходе судебного разбирательства Министерства юстиции США и Google мы узнали, что процесс ранжирования Google включает в себя три основных компонента:
<ол>
<п>В иске Министерства юстиции США против Google подробно говорилось о том, что огромное преимущество Google проистекает из больших объемов пользовательских данных, которые он использует. В своей апелляции Google заявила, что не желает выполнять постановление судьи о передаче пользовательских данных конкурентам. В нем перечислены два способа использования пользовательских данных – в системе под названием Glue, системе, включающей Navboost , которая смотрит на то, на что пользователи нажимают и с чем взаимодействуют, а также в модели RankEmbed.
RankEmbed – это увлекательно. Он встраивает запрос пользователя в векторное пространство. Содержимое, которое может иметь отношение к этому запросу, будет найдено поблизости. RankEmbed настраивается двумя вещами:
<п><сильный>1. Оценки от оценщиков качества. Им предоставляются два набора результатов – “Замороженный” Результаты Google и “Retrained” результаты – или, другими словами, результаты недавно обученных и усовершенствованных поисковых алгоритмов, управляемых ИИ. Их оценки помогают системам Google понять, дают ли переобученные алгоритмы результаты поиска более высокого качества.
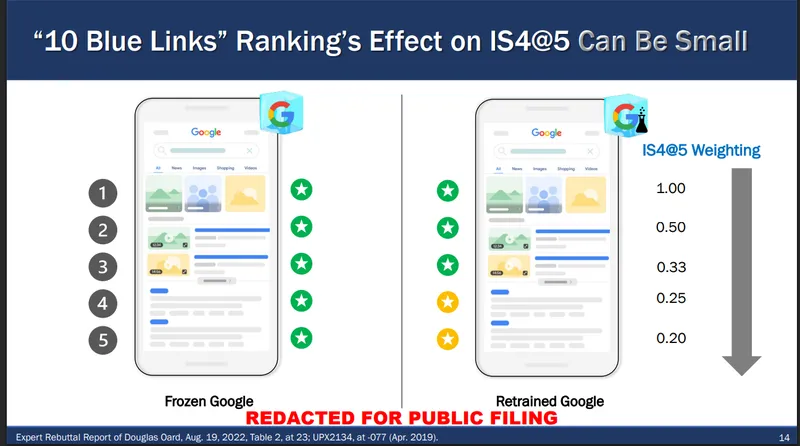
Из показаний Дугласа Оарда: Замороженный и переобученный Google
2. Реальные живые эксперименты, где небольшому проценту реальных пользователей показываются результаты старых и переобученных алгоритмов. Их щелчки и действия помогают точно настроить систему.
<п>Конечная цель этих систем — постоянно улучшать результаты ранжирования, которые удовлетворяют пользователя.
Больше размышлений о живых тестах – Пользователи сообщают Google типы страниц, которые являются полезными, а не настоящие страницы
Я понял, что пользовательские тесты Google в реальном времени — это не просто сбор данных на определенных страницах. Они предназначены для обучения системы распознаванию шаблонов. Google не обязательно отслеживает каждое взаимодействие пользователя, чтобы ранжировать этот конкретный URL. Вместо этого он использует эти данные, чтобы научить свой ИИ тому, что “полезно” похоже. Система учится идентифицировать типы контента, который удовлетворяет намерения пользователя, а затем предсказывает, соответствует ли ваш сайт этому успешному образцу.
Он продолжит совершенствовать процесс прогнозирования того, какой контент может оказаться полезным. Это определенно выходит далеко за рамки простого векторного поиска. Google постоянно находит новые способы понять намерения пользователей и способы их удовлетворения.
Что это значит для SEO
Если вы находитесь в первых нескольких страницах поиска, вы убедили традиционные системы ранжирования выставить вас на рейтинговый аукцион.
<п>Оказавшись там, множество систем искусственного интеллекта работают над прогнозированием того, какой из лучших результатов действительно является лучшим для поисковика. Это становится еще более важным сейчас, когда Google начинает использовать “Персональный интеллект в режимах Gemini и ИИ. Мои самые популярные результаты поиска будут специально адаптированы к тому, что системы Google считают полезными.I сочтут полезным.
Как только вы начнете понимать, как системы ИИ осуществляют поиск, а это в первую очередь векторный поиск, у вас может возникнуть соблазн заняться их реверс-инжинирингом. Если вы оптимизируете, используя глубокое понимание того, что вознаграждает векторный поиск (включая использование косинусного сходства), вы работаете над тем, чтобы хорошо выглядеть в глазах систем ИИ. Я не буду нырять здесь слишком глубоко.
Изображение предоставлено: Мари Хейнс
Учитывая, что системы настроены так, чтобы постоянно совершенствоваться и выдавать результаты, наиболее удовлетворяющие искателя, хороший внешний вид для ИИ далеко не так важен, как действительно самый полезный результат. Я бы сказал, что оптимизация векторного поиска может принести больше вреда, чем пользы, если только у вас действительно нет того типа контента, который пользователи находят более полезным, чем другие варианты, которые у них есть. В противном случае есть большая вероятность, что вы тренируете системы ИИ так, чтобы они были в вашу пользу, а не .

Изображение предоставлено: Мари Хейнс
Мой совет
Мой совет — свободно оптимизировать векторный поиск. Под этим я подразумеваю не зацикливаться на ключевых словах и косинусном сходстве, а вместо этого понять, чего хочет ваша аудитория, и быть уверенным, что ваши страницы отвечают ее конкретным потребностям. Полезно ли здесь использовать знания о разветвлении запросов Google? В некоторой степени да, поскольку полезно знать, какие вопросы обычно возникают у пользователей по поводу запроса. Но я думаю, что мои опасения применимы и здесь. Если вы действительно хорошо относитесь к системам искусственного интеллекта, пытающимся найти контент, удовлетворяющий разветвленному запросу, но пользователи не склонны с этим соглашаться, или если вам не хватает других характеристик, связанных с полезностью, по сравнению с конкурентами, вы можете научить системы Google оказывать вам меньшее предпочтение.
Используйте заголовки – не для того, чтобы системы искусственного интеллекта могли это увидеть, а для того, чтобы помочь вашим читателям понять, что то, что они ищут, находится на вашей странице.
Посмотрите на страницы, которые Google ранжирует по запросам, которые должны вести на вашу страницу, и по-настоящему спросите себя что особенного в этих страницах, что поисковики находят полезным. Посмотрите, насколько хорошо они отвечают на конкретные вопросы, используют ли они хорошие изображения, таблицы или другую графику, и насколько легко просматривать страницу и перемещаться по ней. Постарайтесь выяснить, почему эта страница была выбрана как одна из наиболее вероятных для удовлетворения потребностей пользователей.
Вместо того, чтобы зацикливаться на ключевых словах, работайте над улучшением фактического пользовательского опыта. Если вы сделаете свою страницу более привлекательной, уделив больше внимания таким показателям, как прокрутка и продолжительность сеанса, рейтинг должен естественным образом улучшиться.
И, главным образом, одержимость желанием помочь. Может быть полезно, чтобы сторонняя сторона просмотрела ваш контент и рассказала, почему он может быть полезен, а может и нет.
Я обнаружил, что, несмотря на то, что я понимаю, что поиск создан для постоянного обучения и улучшения показа пользователям страниц, которые они могут найти полезными, я все еще борюсь с желанием оптимизировать сайт для машин, а не для пользователей. От этой привычки сложно избавиться! Учитывая, что системы глубокого обучения Google неустанно работают над одной целью – прогнозирование того, какие страницы могут оказаться полезными для пользователя – – это также должно быть нашей целью. Как следует из документации Google по полезному контенту, тип контента, который люди склонны находить полезным, — это контент, который является оригинальным, информативным и представляет значительную ценность по сравнению с другими страницами в результатах поиска.
Этот пост был первоначально опубликован на сайте Marie Haynes Consulting.


