<стр>Джон Мюллер из Google дает откровенный ответ о влиянии блокировки Google на «связывающую силу».
В подкасте SEO Office Hours Джона Мюллера из Google спросили, приведет ли блокирование сканирования веб-страницы к отмене “связывающей силы” внутренних или внешних ссылок. Его ответ предложил неожиданный взгляд на проблему и дает представление о том, как Google Search внутренне подходит к этой и другим ситуациям.
О силе ссылок
Существует много способов думать о ссылках, но что касается внутренних ссылок, Google постоянно говорит об использовании внутренних ссылок, чтобы сообщить Google, какие страницы являются наиболее важными.
Google в последнее время не публиковал никаких патентов или исследовательских работ о том, как они используют внешние ссылки для ранжирования веб-страниц, поэтому почти все, что оптимизаторы знают о внешних ссылках, основано на старой информации, которая может быть устаревшей. сейчас.
То, что сказал Джон Мюллер, ничего не добавляет к нашему пониманию того, как Google использует входящие или внутренние ссылки, но предлагает другой способ думать о них, который, на мой взгляд, более полезен, чем так кажется на первый взгляд.
<х2>Влияние блокировки индексации на ссылки
Человек, задавший вопрос, хотел знать, влияет ли блокировка Google на сканирование веб-страниц на то, как Google использует внутренние и входящие ссылки.
Это вопрос:
“Отменяет ли блокировка сканирования или индексирования URL-адреса силу связывания внешних и внутренних ссылок?”
<п>Мюллер предлагает найти ответ на вопрос, подумав о том, как на него отреагирует пользователь. Это любопытный ответ, но он также содержит интересную информацию.
<п><эм>Он ответил:
“Я бы посмотрел на это так, как посмотрел бы пользователь. Если страница им недоступна, они не смогут ничего с ней сделать, и поэтому любые ссылки на этой странице будут неактуальны».
Вышеизложенное соответствует тому, что мы знаем о взаимосвязи между сканированием, индексированием и ссылками. Если Google не может просканировать ссылку, Google не увидит ссылку и, следовательно, ссылка не будет иметь никакого эффекта.
Ключевое слово и пользовательский взгляд на ссылки
Предложение Мюллера посмотреть на это так, как на него посмотрит пользователь, интересно, потому что большинство людей не так воспримут вопрос, связанный со ссылками. Но это имеет смысл, потому что если вы заблокируете человеку доступ к веб-странице, он не сможет видеть ссылки, верно?
<п>А как насчет внешних ссылок ? Давным-давно я увидел платную ссылку на веб-сайт, посвященный чернилам для принтеров, на веб-странице морской биологии, посвященной чернилам осьминога. Разработчики ссылок в то время думали, что если на веб-странице есть слова, соответствующие целевой странице (осьминог “чернила” принтер “чернила”), то Google будет использовать эту ссылку для ранжирования странице, поскольку ссылка находилась на “релевантном” веб-страница.
Как бы глупо это ни звучало сегодня, многие люди верили в эту идею “основанную на ключевых словах” подход к пониманию ссылок в отличие от подхода, ориентированного на пользователя, который предлагает Джон Мюллер. С точки зрения пользователя, понимание ссылок становится намного проще и, скорее всего, лучше согласуется с тем, как Google ранжирует ссылки, чем старомодный подход на основе ключевых слов.
Оптимизируйте ссылки, сделав их доступными для сканирования
<п>Мюллер продолжил свой ответ, подчеркнув важность открытия страниц с помощью ссылок.
Он объяснил:
“Если вы хотите, чтобы страницу было легко найти, убедитесь, что на нее есть ссылки со страниц, которые индексируются и релевантны вашему веб-сайту. Также можно заблокировать индексирование страниц, которые вы не хотите, чтобы они были обнаружены, это в конечном итоге ваше решение, но если на важную часть вашего веб-сайта есть ссылки только с заблокированной страницы. , тогда поиск будет намного сложнее.”
О блокировке сканирования
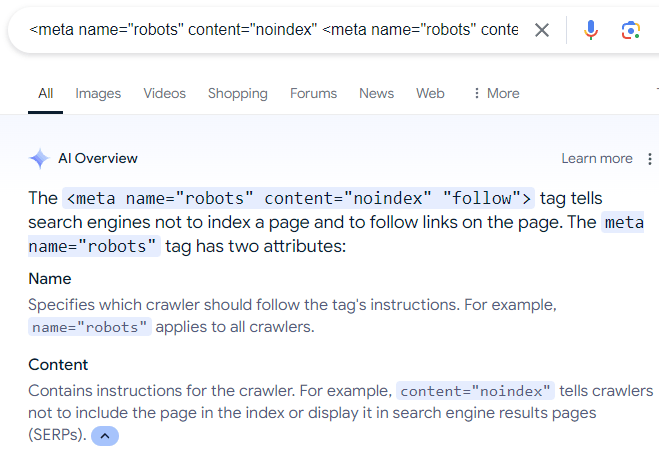
<стр>И последнее слово о блокировке поисковыми системами сканирования веб-страниц. Удивительно распространенная ошибка, которую, как я вижу, совершают некоторые владельцы сайтов, заключается в том, что они используют мета-директиву robots, чтобы сообщить Google не индексировать веб-страницу, а сканировать ссылки на веб-странице.
Директива (ошибочная) выглядит следующим образом:
<meta name=”robots” content=”noindex” <meta name=”robots” content=”noindex” “подписаться”>
В Интернете много дезинформации, которая рекомендует приведенное выше метаописание, что даже отражено в обзорах искусственного интеллекта Google:
Скриншот обзоров ИИ
<п>
<п>Конечно, приведенная выше директива роботов не работает, потому что, как объясняет Мюллер, если человек (или поисковая система) не может видеть веб-страницу, то человек (или поисковая система) не может перейти по ссылкам, которые есть в сети. стр.
Кроме того, хотя есть параметр “nofollow” директивное правило, которое можно использовать, чтобы сканер поисковой системы игнорировал ссылки на веб-странице, нет кнопки “follow” директива, которая заставляет сканер поисковой системы сканировать все ссылки на веб-странице. Переход по ссылкам — это настройка по умолчанию, которую поисковая система может решить сама.
<стр>Подробнее о метатегах роботов.
Послушайте, как Джон Мюллер отвечает на вопрос с отметки 14:45 подкаста: