
<стр>В эпоху дыма и зеркал, проблем со спамом, фальшивых авторов и специалистов по связям с общественностью, продемонстрировать настоящую ясность людям и машинам – это все.
<сильный>TL;DR
<ол> <ли>Устранение неоднозначности — это процесс разрешения двусмысленности и неопределенности в данных. Это имеет решающее значение в современном SEO и поиске информации.
<п>
Интернет изменился. Каналы начали гомогенизироваться. Google пытается стать чем-то вроде пункта назначения, а индивидуальный создатель контента сейчас сильнее, чем когда-либо.
О, и нам не нужно ни на что нажимать.
<п>Но то, что делает контент отличным, не изменилось. ИИ и LLM не изменили то, что люди хотят потреблять. Они изменили то, на что нам нужно нажать. Которое я не обязательно ненавижу.
При условии, что вы уже много лет создаете хорошо структурированный, интересный, образовательный/развлекательный контент. Вся эта болтовня о фрагментировании для меня — это немного дым и зеркала.
“Если он ходит как утка и говорит как утка, возможно, это мошенник, продающий вам услуги по построению ссылок или ГЕО.”
<п>Однако это совершенно не все ерунда. Такие понятия, как двусмысленность, являются более разрушительной силой, чем когда-либо. Если вы разрешите быстрое двойное отрицание, вы не сможете not быть ясным.
Ты яснее. Тем более лаконично. Более структурированная страница и вне ее. Тем больше у вас шансов. Здесь нет места двусмысленным фразам, абзацам и определениям.
Это известно как устранение неоднозначности.
Что такое неоднозначность?
Устранение неоднозначности — это процесс разрешения двусмысленности и неопределенности в данных. Неоднозначность — это проблема современного Интернета. Чем глубже мы погружаемся в кроличью нору, тем меньше внимания уделяется точности и истине. Чем больше ясности обеспечивает окружающий контекст, тем лучше.
<стр>Это важнейший компонент современного SEO, искусственного интеллекта, обработки естественного языка (НЛП) и поиска информации.
Это очевидный и слишком часто используемый пример, но рассмотрим такой термин, как яблоко. Намерения и понимание, стоящие за этим, неясны. Мы не знаем, имеют ли люди в виду компанию, фрукт, дочь придурка, безмозглую знаменитость.
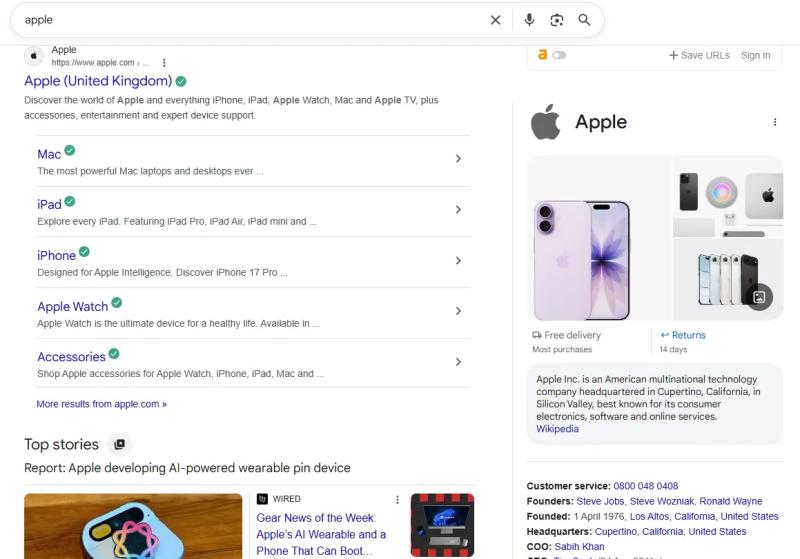
Изображение предоставлено: Гарри Кларксон-Беннетт <п>Несколько лет назад этот тип неоднозначного поиска дал бы более разнообразный набор результатов. Но благодаря персонализации и триллионам сохраненных взаимодействий Google знает, чего мы все хотим. Здесь фундаментальное значение имеют масштабируемые сигналы вовлечения пользователей и лучшее понимание намерений, а также ключевых слов, фраз и контекста.
Да, я мог бы придумать пример получше, но меня это не беспокоило. Вы понимаете мою точку зрения.
Почему меня это должно волновать?
Современный поиск информации требует ясности. Контекст, который вы предоставляете, действительно имеет значение, когда дело доходит до оценки достоверности, которую требуют системы оценки при поиске “правильных” ответ.
И этот контекст присутствует не только в контенте.
Существуют серьезные споры о ценности структурированных данных в современном поиске и получении информации. Использование структурированных данных, таких как SameAs , чтобы точно указать, кто этот автор, и связывание всех учетных записей и суббрендов вашей компании в социальных сетях может быть только полезным делом.
Аргумент не в том, что это не имеет никакой ценности. Это имеет смысл. <ул>
Это позволяет моделям эффективно предсказывать какие слова должны присутствовать в окружающем контексте. Именно поэтому ответы на самые актуальные вопросы, прогнозирование намерений пользователей и «что будет дальше» позволяют получить ответы на самые важные вопросы. долгое время был так ценен в поисках.
Для получения дополнительной информации см. Google&s Word2Vec
Google занимается этим уже давно
Вы помните, каким было раннее и официальное заявление Google относительно информации?
“Организовать информацию в мире и сделать ее общедоступной и полезной.”
Их прежним девизом было «не будь злым». Я думаю, что в последнее время они, возможно, несколько упустили это из виду. Или удобно спрятать.
<стр>Организация мировой информации стала намного эффективнее благодаря достижениям в области информационного поиска. Изначально Google преуспел в использовании простого сопоставления ключевых слов. Затем они перешли к токенизации.
<п>Их способность разбивать предложения на слова и отвечать на короткие запросы была революционной. Но по мере того, как запросы развивались, а намерения становились менее очевидными, им приходилось развиваться.
Появление Google Knowledge Graph произвело трансформацию. База данных сущностей, которая помогла обеспечить согласованность. Это обеспечило стабильность и повысило точность в постоянно меняющейся сети.
Изображение предоставлено: Гарри Кларксон-Беннетт <п> <п>Теперь запросы переписываются в масштабе. Ранжирование является вероятностным, а не детерминированным, и в некоторых случаях для получения всеобъемлющего ответа применяются процессы разветвления. Речь идет о соответствии намерениям пользователя в данный момент. Это персонализировано. Контекстуальные сигналы применяются для того, чтобы дать человеку наилучший результат.
Это означает, что мы теряем предсказуемость в зависимости от настроек температуры, контекста и пути вывода. Происходит гораздо больше извлечений на уровне отрывков.
Благодаря Дэну Петровичу мы знаем, что Google не использует весь контент вашей страницы при обосновании своих систем искусственного интеллекта на базе Gemini. Каждый запрос имеет фиксированный базовый бюджет, составляющий примерно 2000 слов, распределенных по источникам по рангу релевантности.
<п>Чем выше ваш рейтинг в поиске, тем больше бюджета вам выделяется. Думайте об этом ограничении контекстного окна как о бюджете сканирования. Большие окна обеспечивают более длительное взаимодействие, но приводят к снижению производительности. Поэтому им нужно найти баланс.
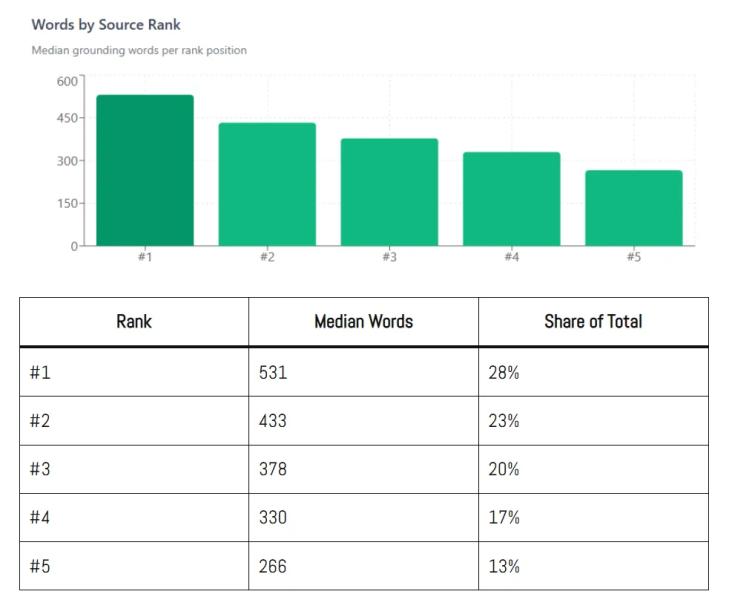
Позиция 1 дает вам вдвое больше “бюджет” на позиции 5 (Изображение предоставлено Гарри Кларксон-Беннеттом)
Hummingbird, BERT, RankBrain – Базовое семантическое понимание
<п>Эти старые изменения в алгоритмах сыграли решающую роль в том, что системы Google стали по-другому относиться к языку и значению.
<ул>
RankBrain был основан на успехе семантического поиска Hummingbird. Овладев системами НЛП, Google начал сопоставлять слова с математическими шаблонами (векторизацией), чтобы лучше обслуживать новые и постоянно развивающиеся запросы.
Эти векторы помогают Google ‘угадать’ намерение запросов, которые он имеет никогда раньше не встречались путем нахождения их ближайших математических соседей.
Обновления диаграммы знаний
В июле 2023 года Google выпустил крупное обновление Knowledge Graph. Я думаю, что люди в SEO назвали это обновлением «Касатка», но я не могу вспомнить, кто придумал эту фразу. Или почему. Извинения. Он был разработан, чтобы ускорить рост графа и уменьшить его зависимость от сторонних источников, таких как Википедия.
<п>Как человек, который долгое время возился с сущностями, я прекрасно понимаю, почему. Это огромная и дорогая трата времени.
Он явно расширил и реструктурировал способы распознавания и классификации сущностей в Графе знаний. В частности, личности с четкими ролями, такие как автор или писатель.
<ул>
Все это — попытка бороться с ошибками ИИ, обеспечить ясность и минимизировать дезинформацию. Чтобы уменьшить двусмысленность и предоставлять контент, в центре которого находится живой, дышащий эксперт. <блоковая цитата><п>Здесь стоит проверить, присутствуете ли вы в сети знаний. Если вы это сделали и можете претендовать на панель знаний, сделайте это. Зацементируйте свое присутствие. Если нет, создайте свой бренд и связи в Интернете.
А как насчет программ LLM иamp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp; Поиск ИИ?
Существует два основных способа получения информации LLM:
<ул>
<п>RAG — вот почему традиционный поиск Google по-прежнему так важен. Последние модели больше не обучаются на данных в реальном времени и немного отстают. Прежде чем основная модель начнет реагировать на вашу отчаянную потребность в общении, классификатор определяет, необходим ли поиск информации в реальном времени.

Отсюда необходимость в RAG (Изображение предоставлено Гарри Кларксоном-Беннеттом)
Они не могут знать всего, и им приходится использовать RAG, чтобы восполнить недостаток актуальной информации (или фактов, поддающихся проверке с помощью данных обучения) при получении определенных ответов. По сути, пытаюсь убедиться, что они не болтают чушь.
<стр>Галлюцинации, если тебе хочется чего-то необычного. <п>Итак, каждой модели нужна своя форма устранения неоднозначности. В первую очередь это достигается с помощью:
<ул>
<ли><сильный>Диалоговые агенты. LLM могут быть предложены решить, следует ли напрямую ответить на запрос или попросить пользователя уточнить, если они не соответствуют одному и тому же порогу доверия.
Помните: если ваш контент недоступен для поисковых систем, его нельзя использовать как часть ответа на заземление. Здесь нет разделения.
Что с этим делать?
Если вы хотели преуспеть в поиске на протяжении последнего десятилетия, это должно было стать основной частью вашего мышления. Полезный контент награждает ясностью.
Предположительно. Это также вознаграждает за прекращение существования небольших сайтов.
Помните, что быть умным не лучше, чем быть ясным.
Это не значит, что вы не можете быть и тем, и другим. Отличный контент развлекает, обучает, вдохновляет и развивает.
Используй слова
Тебе нужно научиться писать. Короткие, емкие предложения. Помогите людям и машинам соединить точки. Если вы понимаете тему, вы должны знать, что люди хотят или им нужно прочитать дальше, почти лучше, чем они сами. <ул>
<ли>Выделяться. Будьте разными. Добавьте информацию в корпус, чтобы добиться упоминания и/или цитирования.
Эффективно структурируйте страницу
<стр>Пишите ясными, простыми абзацами с логичной структурой заголовков. Вам действительно не обязательно называть это фрагментированием, если вы этого не хотите. Просто сделайте так, чтобы людям и машинам было легко потреблять ваш контент.
<ул> <ли>Ответьте на вопрос. Ответь пораньше.
<стр>Позвольте пользователям легко увидеть, что они получают и подходит ли им эта страница. <ч3>Намерение
Большое намерение статично. Коммерческие запросы всегда требуют определенного уровня сравнения. Транзакционные запросы требуют определенного процесса покупки или продажи.
<п>Но намерения меняются, и каждый день возникают миллионы новых запросов.
Итак, вам нужно следить за смыслом термина или фразы. Новости, вероятно, являются прекрасным примером. Истории ломаются. Развивать. То, что было правдой вчера, может быть неверным сегодня. Суды общественного мнения порицают и хвалят в равной мере.
Вы можете использовать что-то вроде Также спросил , чтобы отслеживать изменения намерений с течением времени.
Технический уровень
В течение многих лет структурированные данные помогали разрешить двусмысленность. Но у нас нет полной ясности относительно его влияния на поиск ИИ. Чистые, хорошо структурированные страницы всегда легче анализировать, а распознавание объектов действительно имеет значение.
<ул>
<ли>Внутренние ссылки помогают ботам перемещаться по связанным разделам вашего веб-сайта и создавать некоторую форму тематического авторитета.
<стр>Если вам нравится возиться с схемой знаний (а кто, черт возьми, не любит?), вы можете найти показатели доверия к своему бренду.
Согласно собственным рекомендациям Google, структурированные данные дают четкую информацию о содержании страницы, помогая поисковым системам лучше понять ее.
Да-да, он отображает подробные результаты и т. д. Но он устраняет двусмысленность.
Сопоставление объектов
Я думаю, это все объединяет. Ваш бренд, ваши продукты, ваши авторы, ваши аккаунты в социальных сетях. <стр>То, что вы говорите о своем бренде, сейчас важно как никогда. <ул>
<стр>Все это помогает машинам составить четкое представление о том, кто вы есть. Если у вас сильный профиль в социальных сетях, вам нужно убедиться, что вы используете это доверие.
<стр>На уровне страницы отличным началом будет последовательность заголовков, использование соответствующих объектов в первом абзаце, ссылки на соответствующие теги и страницы статей, а также использование насыщенной и актуальной биографии автора.
Действительно, просто хорошее, надежное SEO. Не @me.
PSA: Не будьте скучными. Ты не выживешь.
Этот пост был первоначально опубликован на сайте Leadership in SEO.


