Поисковые системы уже давно не фокусируются исключительно на ключевых словах. Они могут и действительно «понимают» документы и предметы как часть более широкого корпуса. Это пространство векторной модели в действии.
<п>Информационно-поисковые системы предназначены для удовлетворения пользователя. Чтобы пользователь был доволен качеством отзыва. Нам важно это понимать. Каждая система, ее входы и выходы спроектированы так, чтобы обеспечить максимальное удобство для пользователя.
От данных обучения до оценки сходства и способности машины “понимать” наша усталая, грустная фигня – это третий из серии, которую я назвал, поиск информации для дебилов.

Изображение предоставлено: Гарри Кларксон-Беннетт
TL;DR
<ол>
<ли>Более длинные документы содержат больше похожих терминов. Чтобы бороться с этим, длина документа нормализуется, а релевантность имеет приоритет.
Вещи, которые следует знать, прежде чем мы начнем
<стр>Некоторые концепции и системы, о которых вам следует знать, прежде чем мы углубимся в них.
Я всего этого не помню, и ты тоже. Просто постарайтесь получать удовольствие и надеяться, что благодаря сосредоточенности и последовательности вы со временем смутно вспомните вещи. <ул> <ли><сильный>TF-IDF означает термин, частота документов, обратная частоте. Это числовая статистика, используемая в НЛП и поиске информации для измерения релевантности термина в корпусе документов.
Что такое векторная пространственная модель?
Модель векторного пространства (VSM) — это алгебраическая модель, которая представляет текстовые документы или элементы как “векторы” Такое представление позволяет системам создавать расстояние между каждым вектором.
Расстояние рассчитывает сходство между терминами или элементами.
<п>Векторные модели, которые обычно используются при поиске информации, ранжировании документов и извлечении ключевых слов, создают структуру. Это структурированное многомерное числовое пространство позволяет рассчитывать релевантность с помощью таких мер сходства, как косинусное сходство.
Терминам присваиваются значения. Если термин появляется в документе, его значение не равно нулю. Стоит отметить, что термины – это не просто отдельные ключевые слова. Это могут быть фразы, предложения и целые документы.
Как это работает?
После того как запросам, фразам и предложениям присвоены значения, документ можно оценить. Он имеет физическое место в векторном пространстве, выбранное моделью.
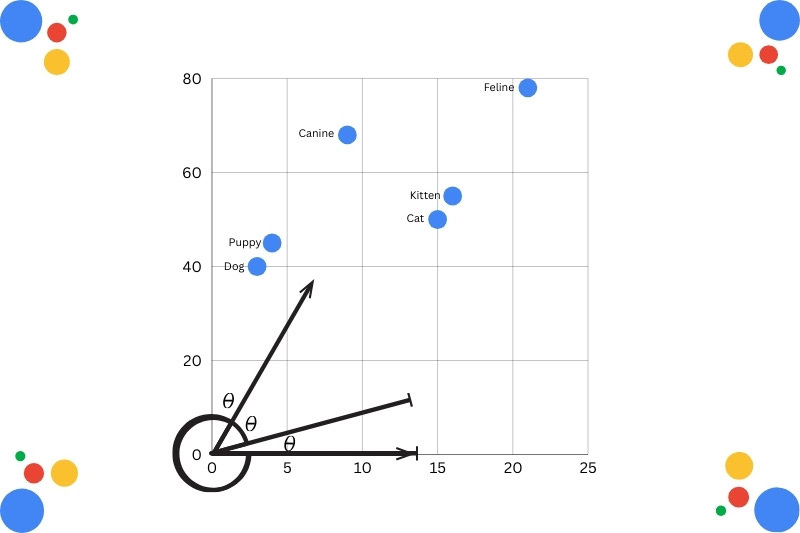
В данном случае слова представлены на графике для обозначения отношений между ними (Изображение предоставлено Гарри Кларксоном-Беннеттом)
В зависимости от оценки документы можно сравнивать друг с другом на основе введенного запроса. Вы генерируете оценки сходства в масштабе. Это известно как семантическое сходство, когда набор документов оценивается и позиционируется в индексе на основе их значения.
<с>Не только их лексическое сходство.
Я знаю, это звучит немного сложно, но подумайте об этом так:
Словами на странице можно манипулировать. Ключевое слово набито. Они слишком простые. Но если вы сможете вычислить значение (документа), вы станете на шаг ближе к качественному результату.
Почему это так хорошо работает?
<п>Машины любят не только структуру. Им это чертовски нравится.
Входные и выходные данные фиксированной длины (или стилизованные) создают предсказуемые и точные результаты. Чем более информативен и компактен набор данных, тем более качественную классификацию, извлечение и прогнозирование вы получите.
Проблема текста в том, что он не имеет особой структуры. По крайней мере, не в глазах машины. Это грязно. Вот почему она имеет такое преимущество перед классической моделью логического поиска.
<п>В моделях логического поиска документы извлекаются в зависимости от того, удовлетворяют ли они условиям запроса, использующего логическую логику. Он рассматривает каждый документ как набор слов или терминов и использует операторы И, ИЛИ и НЕ для возврата всех результатов, которые соответствуют всем требованиям.
Его простота имеет свое применение, но не может интерпретировать смысл.
<стр>Думайте об этом больше как о поиске данных, чем о идентификации и интерпретации информации. Мы слишком часто попадаем в ловушку частоты терминов (TF) при более детальном поиске. Легко, но лениво в современном мире.
В то время как модель векторного пространства интерпретирует фактическую релевантность запросу и не требует точного соответствия терминов. В этом вся красота.
Именно эта структура обеспечивает гораздо более точное воспоминание.
Трансформерская революция (не Майкл Бэй)
В отличие от серии Майкла Бэя, real архитектура-трансформер заменила старые статические методы внедрения (такие как Word2Vec) контекстными встраиваниями.
В то время как статические модели присваивают каждому слову один вектор, преобразователи генерируют динамические представления, которые изменяются в зависимости от окружающих слов в предложении.
И да, Google занимается этим уже некоторое время. Это не ново. Это не ГЕО. Это просто современный поиск информации, который “понимает” страница.
Я имею в виду, очевидно, нет. Но вы, как разумное, дышащее существо, понимаете, что я имею в виду. Но трансформеры, ну, они притворяются:
<ол>
Позвольте мне привести пример.
“Зубы летучей мыши сверкнули, когда она вылетела из пещеры.”
<п>Летучая мышь — неоднозначный термин. Неоднозначность — это плохо в эпоху ИИ.
Но архитектура трансформатора оставила биту с “зубами” “летел” и “пещера” сигнализируя о том, что летучая мышь, скорее всего, является кровососущим грызуном*, чем чем-то, что джентльмен мог бы использовать, чтобы ласкать мяч ради границы в лучшем виде спорта в мире.
*Не знаю, является ли летучая мышь грызуном, но она похожа на крысу с крыльями.
<ч2>БЕРТ наносит ответный удар
Так Google работал уже много лет. Применяя этот тип контекстуально-ориентированного понимания к семантическим отношениям между словами и документами. Это во многом объясняет, почему Google так хорошо отображает и понимает намерения, а также то, как они меняются со временем.
Более последние обновления BERT (DeBERTa) позволяют представлять слова двумя векторами – один для значения и один для его положения в документе. Это известно как распутанное внимание. Это обеспечивает более точный контекст.
<п>Да, для меня это тоже звучит странно.
BERT обрабатывает всю последовательность слов одновременно. Это означает, что контекст применяется ко всему содержимому страницы (а не только к нескольким окружающим терминам).
Синонимы Малыш
<п>RankBrain, запущенная в 2015 году, стала первой системой глубокого обучения Google. Ну, это я во всяком случае знаю. Он был разработан, чтобы помочь алгоритму поиска понять, как слова связаны с понятиями.
Это была эпоха пика поиска. Любой может создать веб-сайт о чем угодно. Получите это и ранжируйте. Заработайте кучу денег. Не требуется никакой строгости.
<п>Безмятежные дни.
Оглядываясь назад, можно сказать, что эти дни были не лучшими для широкой публики. Получение совета по планированию похорон и утилизации коммерческих отходов из спальни неряшливого 23-летнего парня в Галифаксе. <п>По мере роста количества новых и развивающихся запросов, RankBrain и последующее нейронное сопоставление стали жизненно важными.
Потом была МАМА. Способность Google “понимать” текст, изображения и визуальный контент на нескольких языках одновременно.
Решение проблем с длиной документа
Длина документа была очевидной проблемой 10 лет назад. Может быть, меньше. Более длинные статьи, к лучшему или к худшему, всегда имели больший успех. Я помню, как писал статьи на 10 000 слов о какой-то чепухе о конструкторах веб-сайтов и размещал их на главной странице.
Даже тогда это была бредовая идея…
В мире, где запросы и документы отображаются в числах, можно простить мысль, что более длинные документы всегда будут отображаться поверх более коротких.
<стр>Вспомните 10-15 лет назад, когда все были одержимы тем, что каждая статья состояла из 2000 слов.
“Это оптимальная длина для SEO.”
Если вы видите другое сообщение “Который час X” Статья на 2000 слов, я разрешаю вас пристрелить меня.
Вы не можете игнорировать тот факт, что это лучший опыт (Изображение предоставлено Гарри Кларксоном) Беннетт) <п>Более длинные документы будут – в результате содержания большего количества терминов – имеют более высокие значения TF. Они также содержат более четкие термины. Эти факторы могут привести к увеличению оценок более длинных документов
Поэтому какое-то время они были зенитом нашего дрянного производства контента.
<стр>Более длинные документы можно разделить на две категории: <ол>
Для решения этой очевидной проблемы используется форма компенсации длины документа, известная как нормализация длины поворотного документа. Это корректирует оценки, чтобы противодействовать естественной предвзятости, которую имеют более длинные документы.
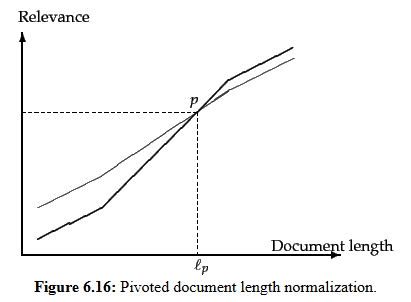
Поворотная нормализация изменяет масштаб весов терминов с использованием линейной корректировки средней длины документа (Изображение предоставлено Гарри Кларксоном-Беннеттом)
Следует использовать косинусное расстояние, потому что мы не хотим отдавать предпочтение более длинным (или более коротким) документам, а хотим сосредоточиться на релевантности. Использование этой нормализации отдает приоритет релевантности над частотой терминов.
Вот почему косинусное сходство так ценно. Он устойчив к длине документа. Короткий и длинный ответ можно рассматривать как тематически идентичные, если они указывают в одном направлении в векторном пространстве.
Ну и что?
<п>Отличный вопрос.
Ну, никто не ожидает от вас понимания тонкостей векторной базы данных. Вам не обязательно знать, что базы данных создают специализированные индексы для поиска близких соседей без проверки каждой записи.
Это просто для таких компаний, как Google, чтобы найти правильный баланс между производительностью, стоимостью и простотой эксплуатации.
Изображение предоставлено: Гарри Кларксон-Беннетт <стр>Ещё больше причин не создавать бездумно большие документы только потому, что кто-то вам сказал.
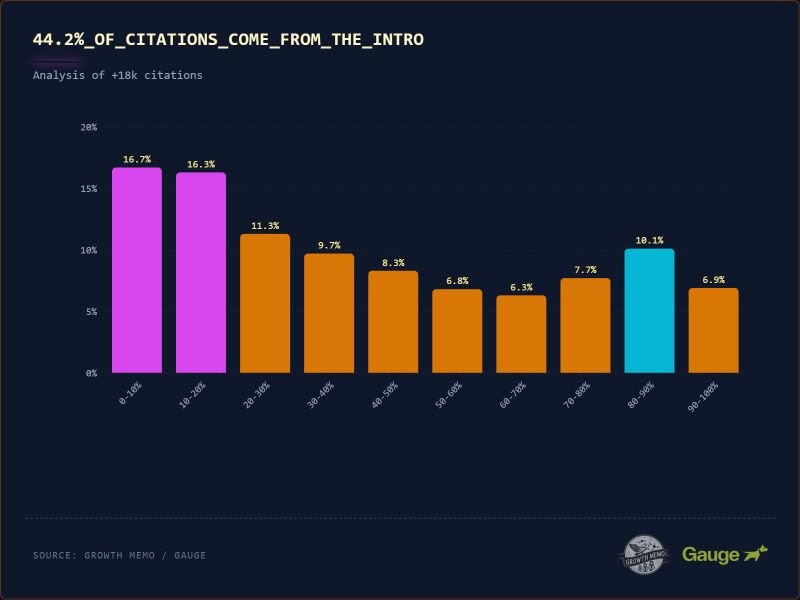
В “поиске AI” многое из этого сводится к токенам. Согласно неизменно превосходной работе Дэна Петровича, каждый запрос имеет фиксированный базовый бюджет, составляющий всего около 2000 слов, распределенных по источникам по рангу релевантности.
По крайней мере, в Google. И ваш ранг определяет ваш счет. Так что занимайтесь SEO.
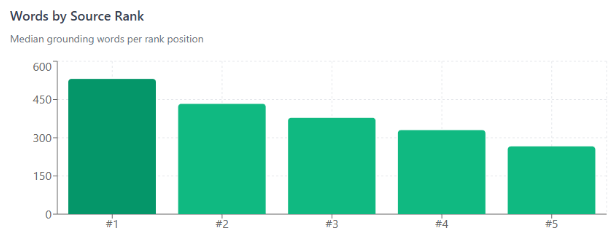
Позиция 1 дает вам вдвое большую известность, чем позиция 5 (Изображение предоставлено Гарри Кларксоном-Беннеттом)
Исследование Метехана о том, что 200 000 токенов раскрывают об AEO/GEO, действительно подчеркивает, насколько это важно. Или будет. Не только из-за нашей работы, но и из-за предубеждений и культурных последствий. <п>Поскольку текст токенизирован (сжимается и преобразуется в последовательность целочисленных идентификаторов), это влияет на стоимость и точность.
<ул>
Языки не созданы равными. В эпоху, когда капитальные затраты (CapEx) растут, а компании, занимающиеся искусственным интеллектом, заключают сделки, я не уверен, что они смогут получить прибыль, это важно.
Полезные советы
Ну, поскольку Google занимается этим уже некоторое время, в обоих интерфейсах должно работать одно и то же.
<ол> <ли>Ответьте на волнующий вопрос. Боже мой. Перейдем к делу. Меня не волнует ничего, кроме того, чего я хочу. Отдайте его мне немедленно (говорит как человек и машина).
.
*Интересно, что они менее эффективны, чем традиционная проза.
<стр>Почти все это направлено на то, чтобы быстро дать людям то, что они хотят, и устранить любую двусмысленность. В Интернете, полном дерьма, это действительно работает.
Последние биты
Идет дискуссия о том, может ли уценка для агентов помочь убрать лишнюю ерунду из HTML на вашем сайте. Таким образом, агенты могли обойти загроможденный HTML и сразу перейти к полезному материалу.
Как много из этих проблем можно решить, используя менее извращенный подход к семантическому HTML, я не знаю. В любом случае, стоит посмотреть.
Очень SEO. Много ИИ.
Прочитайте «Лидерство в SEO». Подпишитесь сейчас.


