
Рекомендации ИИ зависят от реляционных знаний, а не только от содержания. Вот почему ваш бренд может отсутствовать и как это исправить
Попросите ChatGPT или Клода порекомендовать продукт на вашем рынке. Если ваш бренд не отображается, значит, у вас есть проблема, которую не решит никакая оптимизация ключевых слов.
<п>Большинство SEO-специалистов, столкнувшись с этим, сразу задумываются о контенте. Больше страниц, больше ключевых слов, лучшие сигналы на странице. Но причина отсутствия вашего бренда в рекомендациях ИИ может не иметь ничего общего со страницами или ключевыми словами. Это связано с так называемым реляционным знанием и исследовательской работой 2019 года, о которой большинство маркетологов никогда не слышали.
Бумага, которую большинство маркетологов пропустили
В сентябре 2019 года Фабио Петрони и его коллеги из Facebook AI Research и Университетского колледжа Лондона опубликовали статью «Языковые модели как базы знаний?” на EMNLP, одной из ведущих конференций по обработке естественного языка.
Их вопрос был простым: действительно ли предварительно обученная языковая модель, такая как BERT, хранит фактические знания в своих весах? Не лингвистические шаблоны или грамматические правила, а факты о мире. Такие вещи, как «Данте родился во Флоренции»; или «iPod Touch произведен Apple».
Чтобы проверить это, они создали зонд под названием LAMA (Анализ модели LAnguage). Они взяли известные факты, тысячи из которых были взяты из Викиданных, ConceptNet и SQuAD, и превратили каждый из них в утверждение, заполняющее пустые поля. “Данте родился в ___.” Затем они попросили BERT предсказать пропущенное слово.
<п>BERT без какой-либо тонкой настройки вызывает фактические знания на уровне, конкурирующем со специально созданной базой знаний. Эта база знаний была построена с использованием контролируемой системы извлечения отношений с компоновщиком сущностей на базе Oracle, что означало, что она имела прямой доступ к предложениям, содержащим ответы. Языковая модель, которая просто прочитала много текста, работала почти так же хорошо.
Модель не искала ответов. Во время обучения он впитал в себя ассоциации между сущностями и понятиями, и эти ассоциации можно было восстановить. BERT построил внутреннюю карту того, как вещи в мире связаны друг с другом.
После этого исследовательское сообщество начало серьёзно относиться к идее о том, что языковые модели работают как хранилища знаний, а не просто как механизмы сопоставления с образцом.
Что такое “Relational Knowledge” Означает <п>Петрони проверял то, что он и другие называли реляционным знанием: факты, выраженные в виде тройки субъекта, отношения и объекта. Например: (Данте, [уроженец], Флоренция). (Кения, [дипломатические отношения], Уганда). (iPod Touch, [производитель], Apple).
Что делает это интересным для узнаваемости бренда (и AIO), так это то, что команда Петрони обнаружила, что способность модели вспомнить факт во многом зависит от структурного типа отношений. Они определили три типа, и разница в точности между ними была большой.
Отношения 1-к-1: один субъект, один объект
Это однозначные факты. “Столица Японии — ___.” Ответ один: Токио. Каждый раз, когда модель встречала в обучающих данных Японию и столицу, появлялся один и тот же объект. Ассоциация четко сформировалась при многократном воздействии.
BERT давал правильные ответы в 74,5% случаев, что является высоким показателем для модели, которая никогда не была специально обучена отвечать на фактические вопросы.
Отношения N-к-1: много субъектов, один объект
<стр>Здесь один и тот же объект используется многими разными субъектами. “Официальным языком Маврикия является ___.” Ответ – английский, но английский также является ответом для десятков других стран. Модель видела шаблон (страна → официальный язык → английский) много раз, поэтому она хорошо знает форму ответа. Но иногда по умолчанию используется наиболее статистически распространенный объект, а не правильный для данного конкретного субъекта.
<п>Точность упала примерно до 34%. Модель знает категорию, но путается в ней.
Отношения N-к-M: много субъектов, много объектов
Здесь все становится запутанно. “Патрик Обоя играет на позиции ___.” Один футболист может играть полузащитника, нападающего или нападающего в зависимости от контекста. И многие разные футболисты разделяют каждую из этих позиций. Отображение нечеткое в обоих направлениях.
Точность BERT здесь составила всего около 24%. Модель обычно предсказывает что-то правильного типа (она указывает местоположение, а не город), но не может дать конкретный ответ, поскольку обучающие данные содержат слишком много конкурирующих сигналов.
<блоковая цитата>
Я считаю это очень полезным, потому что оно напрямую связано с тем, что происходит, когда ИИ пытается порекомендовать бренд. Бренды (без монополий) действуют по принципу «многие ко многим». отношение. Итак, “Рекомендуйте [Бренд] с [особенностью]” — одна из самых сложных вещей, которую ИИ «предсказывает» для ИИ. с постоянством. Я еще вернусь к этому…
Что произошло с 2019 года
В статье Петрони установлено, что языковые модели хранят реляционные знания. Следующий очевидный вопрос был: где именно?
<п>В 2022 году Дамай Дай и его коллеги из Microsoft Research опубликовали книгу «Нейроны знаний в предварительно обученных трансформаторах». в АКЛ. Они представили метод определения местоположения определенных нейронов в слоях прямой связи BERT, которые отвечают за выражение определенных фактов. Когда они активировали эти «нейроны знаний», Вероятность того, что модель выдаст правильный факт, увеличилась в среднем на 31%. Когда они их подавили, оно упало на 29%.
. <блок-цитата><п><эм>О боже! Это не метафора. Фактические ассоциации закодированы в идентифицируемых нейронах модели. Вы можете их найти и изменить.
<п>Позже в том же году Кевин Мэн и его коллеги из Массачусетского технологического института опубликовали статью «Нахождение и редактирование фактических ассоциаций в GPT». в НейриПС. Мы взяли те же идеи и применили их к моделям в стиле GPT — архитектуре, лежащей в основе ChatGPT, Claude и помощников искусственного интеллекта, которых покупатели фактически используют, когда запрашивают рекомендации. Команда Менга обнаружила, что они могут точно определить конкретные компоненты внутри GPT, которые активируются, когда модель вспоминает факт о субъекте.
Что еще более важно, они могли изменить эти факты. Они могли редактировать то, во что «верит» модель. о сущности без переобучения всей системы.
<п>Этот вывод важен для SEO-специалистов. Если бы ассоциации внутри этих моделей были фиксированными и постоянными, оптимизировать было бы нечего. Но они не фиксированы. Они формируются в зависимости от того, что модель усваивает во время обучения, и меняются, когда модель переобучается на новых данных. Веб-контент, техническая документация, обсуждения в сообществе, отчеты аналитиков, которые появятся на момент следующего тренинга, будут определять, какие бренды и темы ассоциируются у модели.
Итак, прогресс с 2019 по 2022 год выглядит так. Петрони показал, что модели хранят реляционные знания. Дай показал, где оно хранится. Мэн показал, что это можно изменить. Последний пункт должен иметь наибольшее значение для всех, кто пытается повлиять на то, как ИИ рекомендует бренды.
Что это значит для брендов в поиске с помощью ИИ
<стр>Позвольте мне перевести три типа отношений Петрони в сценарии позиционирования бренда.
Бренд 1-к-1: Тесная ассоциация
<п>Подумайте о Stripe и онлайн-платежах. Ассоциация специфична и постоянно укрепляется в Интернете. Документация для разработчиков, обсуждения финтех-технологий, колонки с советами для стартапов, руководства по интеграции: все они связывают Stripe с одной и той же концепцией. Когда кто-то спрашивает ИИ: “Какая платформа обработки платежей является лучшей для разработчиков?” модель извлекает Stripe с высокой достоверностью, поскольку реляционная связь однозначна.
Это динамика Петрони 1 к 1. Сильный сигнал, отсутствие помех.
Бренд N-To-1: Затерян в категории
<п>Теперь представьте себе, что вы являетесь одним из 15 поставщиков кибербезопасности, связанных с “защитой конечных точек” Модель хорошо знает свою категорию. Он видел тысячи дискуссий о защите конечных точек. Но когда его просят порекомендовать конкретного поставщика, по умолчанию он выбирает тот бренд, который имеет самый сильный ассоциативный сигнал. Обычно это наиболее обсуждаемый вопрос в авторитетных кругах: отчеты аналитиков, технические форумы, документация по стандартам.
Если ваш бренд присутствует в разговоре, но не дифференцирован, вы находитесь в ситуации N-to-1. Модель может время от времени упоминать вас, но вместо этого она будет стремиться вспомнить бренд, вызывающий самую сильную ассоциацию.
Бренд N-To-M: везде и нигде
<п>Это самая тяжелая позиция. Крупная компания по производству корпоративного программного обеспечения, работающая в сфере облачной инфраструктуры, консалтинга, баз данных и оборудования, связана со многими темами, но каждая из этих тем также связана со многими конкурентами. Ассоциации рыхлые в обоих направлениях.
Результатом является то, что Петрони наблюдал с отношениями N-к-M: модель выдает что-то правильного типа, но не может дать конкретный ответ. Бренд время от времени появляется в рекомендациях ИИ, но никогда не появляется достоверно по какому-либо конкретному запросу.
Я часто наблюдаю эту закономерность при работе с корпоративными брендами. Они вложили значительные средства в контент по многим темам, но не создали концентрированных, усиленных ассоциаций, которые необходимы модели для уверенного извлечения их по какой-либо отдельной теме.
Измерение зазора
<п>Если вы принимаете предпосылку (и исследования подтверждают ее), что рекомендации ИИ основаны на реляционных ассоциациях, хранящихся в весах модели, тогда практический вопрос: можете ли вы измерить, где ваш бренд находится в этом ландшафте?
Два бренда могут иметь одинаковые показатели доли голоса по совершенно разным структурным причинам. Человек может быть широко связан со многими темами, но слабо с каждой из них. Другой может быть глубоко связан с двумя темами, но невидим везде. Это разные проблемы, требующие разных стратегий.
<п>Именно этот пробел призван устранить метрика под названием AI Topical Presence, разработанная Waikay. Вместо того, чтобы измерять, появляетесь ли вы, он измеряет, с чем ИИ вас ассоциирует, а с чем нет. [Раскрытие информации: я генеральный директор Waikay]
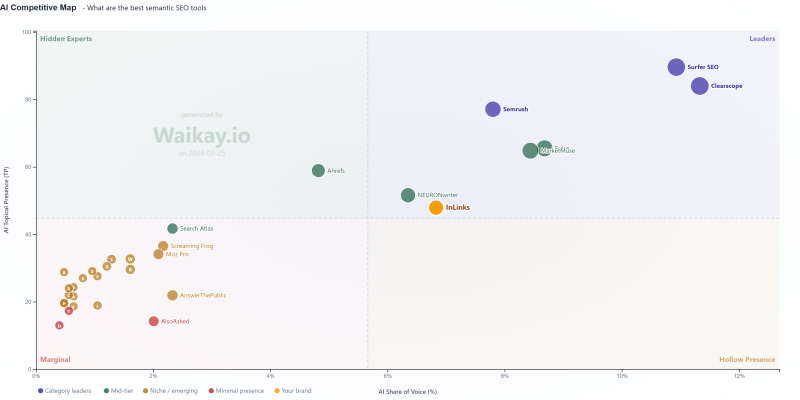
Тематическое присутствие так же важно, как доля голоса (изображение автора, март) 2026) <п>Метрика охватывает три измерения. Глубина измеряет, насколько сильно ИИ связывает ваш бренд с соответствующими темами, взвешенными по важности. Ширина измеряет, сколько основных коммерческих тем на вашем рынке ИИ связывает с вашим брендом. Концентрация измеряет, насколько равномерно распределены эти ассоциации, используя индекс Херфиндаля-Хиршмана, заимствованный из экономики конкуренции.
Бренд с большой глубиной, но малым охватом, хорошо известен по некоторым вещам, но невидим для многих других. Бренд с широким охватом, но высокой концентрацией хрупкий: одно обновление модели может существенно изменить его узнаваемость. Расшифровка компонентов подскажет вам, какая у вас проблема и какой рычаг нужно потянуть.
<п>На приведенной выше диаграмме мы начинаем видеть, как разные бренды действительно конкурируют друг с другом, чего мы раньше не могли видеть. Например, Inlinks гораздо более тесно конкурирует с продуктом под названием Neuronwriter, чем считалось ранее. Neuronwriter имеет меньшую долю голоса (вероятно, я помог им, написав эту статью… чёрт возьми, упс!), но у них больше актуального присутствия в подсказке: «Какие инструменты семантического SEO являются лучшими?” Таким образом, при прочих равных условиях, немного маркетинга — это все, что им нужно, чтобы получить входящие ссылки. Это, конечно, предполагает, что Inlinks стоит на месте. Это не так. Напротив, угроза со стороны Ahrefs присутствует всегда, но, поскольку они предлагают полный спектр услуг, им приходится распространять свою «долю голоса»; во всех своих продуктовых предложениях. Таким образом, хотя их актуальность высока, этот бренд не является естественным выбором для LLM в этом вопросе.
<п>Это снова связано с концепцией Петрони. Если ваш бренд находится в позиции 1 к 1 по одним темам, но отсутствует в других, тематическое присутствие покажет вам, где есть пробелы. Если вы находитесь в ситуации N-to-1 или N-to-M, это поможет вам определить, какие ассоциации нуждаются в усилении и по каким темам конкуренты уже завоевали доминирующие позиции.
От страниц рейтинга к созданию ассоциаций
В течение 25 лет SEO было связано с ранжированием страниц. PageRank сам по себе представлял собой алгоритм на уровне страницы; подсказка всегда была в названии (IYKYK … Не надо меня поправлять…). Несмотря на то, что Google перешел к объектам и графам знаний, практическая работа SEO по-прежнему основывалась на ключевых словах, ссылках и оптимизации страниц.
Это фантастическая новость для брендов, которые хорошо работают на своих рынках. Объем контента сам по себе не создает прочных реляционных ассоциаций. Процесс обучения модели работает как фильтр качества: он обучается на шаблонах всего корпуса, а не на какой-то отдельной странице. Бренд с реальным опытом, обсуждаемый многими людьми в разных контекстах, создаст более сильные ассоциации, чем бренд, который просто публикует больше.
Вопрос, который следует задать, заключается не в том, “Есть ли у нас страница на эту тему?” Это так: “Если кто-то прочитает все, что ИИ усвоил по этой теме, наш бренд будет выглядеть заслуживающим доверия участником разговора?”
Это более сложный вопрос. Но исследования, начавшиеся с тестов Петрони в 2019 году, дали нам достаточное понимание механизма для его измерения. А то, что можно измерить, можно улучшить.


