
Исследователи тестируют два способа обратного проектирования рейтингов LLM Claude 4, GPT-4o, Gemini 2.5 и Grok-3.
Исследователи опубликовали результаты исследования, показывающего, как можно систематически влиять на поисковый рейтинг ИИ, с высоким уровнем успеха для тестов поиска продуктов, которые также распространяются на другие категории, такие как путешествия.
<стр>Название исследовательской работы — «Управление ранжированием результатов в генеративных машинах для поиска на основе LLM», а подход к оптимизации называется CORE, способ влиять на ранжирование результатов в LLM.
Предостережение по поводу исследования CORE
<п>Тестирование и опубликованные результаты были выполнены с использованием реальных LLM, запрошенных через API.
<сильный>Они проверяли:
<ул>
<ли>Близнецы 2,5 <ли>ГПТ-4о <ли>Грок-3
Они не тестировали обзоры AI, ChatGPT или Claude через свои пользовательские интерфейсы. Важность этого различия заключается в том, что обычные виды персонализации не будут играть никакой роли. Кроме того, тестирование ограничивалось только результатами поиска кандидатов.
<п>Кроме того, когда исследователи запрашивали целевые LLM (Claude-4, Gemini-2.5, GPT-4o и Grok-3) через API, модели не полагались на RAG или собственные внешние инструменты поиска. Вместо этого исследователи вручную предоставили “полученные” данные как часть приглашения ввода.
Почему исследования так важны
CORE — это доказательство концепции стратегической оптимизации текста с помощью рассуждений и обзоров. Это также показывает, что LLM по-разному реагируют на обзоры и обоснованные изменения в тексте.
Реверс-инжиниринг черного ящика
<стр>Понимание того, что именно нужно сделать, чтобы улучшить рейтинг ИИ в поисковых системах, — это классическая проблема черного ящика. Проблема черного ящика заключается в том, что вы можете видеть, что входит в ящик (вход) и что выходит (выход), но что происходит внутри ящика, неизвестно.
<п>Исследователи в этом исследовании использовали две стратегии обратного проектирования генеративного ИИ, чтобы определить, какие оптимизации лучше всего влияют на рейтинг.
Они использовали два подхода к обратному проектированию:
<ол>
Из этих двух подходов решение на основе запросов показало лучшие результаты, чем подход теневой модели.
Процент оптимизации страниц с самым низким рейтингом:
<ул>
Решение на основе запросов
Решение на основе запросов работает с тем ограничением, что исследователи не могут получить доступ к внутренним компонентам модели, поэтому они рассматривают LLM как черный ящик.
<п>Они неоднократно изменяют текст документа. После каждого изменения они повторно отправляют список кандидатов в LLM и наблюдают за новым рейтингом. Цикл модификации и тестирования продолжается до тех пор, пока не будет достигнут целевой критерий ранжирования или предел итераций.
Решение на основе запросов использует LLM для добавления текста в целевой документ. Это расширение контента, а не его редактирование.
Они использовали два типа расширения контента:
<ол>
Добавляет пояснительный текст, описывающий, почему элемент удовлетворяет запросу.
Добавляет оценочный контент, формулировку в стиле обзора о предмете.
Это не случайные правки. Это изменения, протестированные как отдельные стратегии, которые исследователи затем оценивают в рейтингах, чтобы определить, оказало ли изменение положительный эффект ранжирования.
Интересно, что ни один из подходов (рассуждение или анализ) не был лучше другого. Какой из них лучше, зависело от LLM, на котором они тестировали.
Вот как выполняются рассуждения и обзоры:
<ул>
Решение теневой модели
<п>В контексте обратного проектирования черный ящик, теневая модель, также называемая суррогатной моделью, представляет собой локальную модель, имитирующую целевую модель (черный ящик). Цель теневой модели — математически аппроксимировать выходные данные черного ящика, чтобы входные данные теневой модели в конечном итоге давали выходные данные, аналогичные черному ящику. Пары ввода-вывода черного ящика используются в качестве набора обучающих данных для обучения теневой модели.
Llama-3.1-8B Теневая модель
Интересно, что Llama-3.1-8B был надежным прокси-сервером для расчета и прогнозирования того, как целевые модели, такие как GPT-4o, будут ранжировать продукты.
<ул>
<ли>По шкале 1 – 5, где 1 соответствует расхождению, а 5 указывает на сходство, Llama-3.1-8B получил рейтинг сходства 4,5 по сравнению с выходами GPT-4o.
Уровень успеха с разными моделями теней
<п>
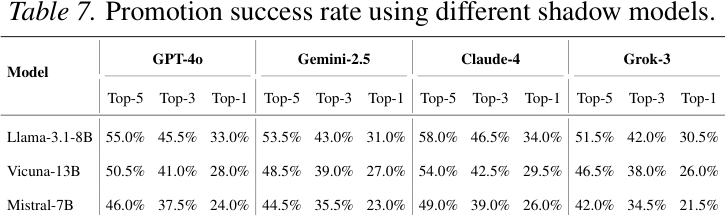
Результаты исследования подхода теневой модели позволяют сделать два следующих вывода:
<п>1. Исследователи показывают, что, итеративно корректируя целевой объект с помощью теневой модели, они смогли вывести его на вершину рейтинга в своих экспериментах.
<п>2. Они также доказывают, что, когда суррогатная модель лишь приблизительно соответствует реальной модели, оптимизация все равно сохраняется, но достижимый успех продвижения по службе снижается плавно, а не резко.
После обучения теневой модели они начали тестирование с тремя стратегиями оптимизации:
<ол>
Оптимизация на основе строк
Исследователи использовали строку из 20 символов, все из которых были восклицательными знаками (!), а затем итеративно меняли строку, отслеживая, как изменения повлияли на рейтинг. Они выполнили 2000 итераций этих математических обновлений строки, превратив ее в лучшую строку символов, что привело к более высоким рейтингам. Полученная строка показалась людям чепухой, но все же повысила рейтинг предмета в эксперименте.
<п>Этот подход не сработал так хорошо, как два других подхода, но он сработал с вероятностью 33% для продвижения страницы, занимавшей последнее место в рейтинге, на первую позицию. Тестирование с участием людей-аннотаторов показало, что оно было обнаружено в 98,5% случаев. Так что это не скрытая оптимизация.
Оптимизация на основе рассуждений
Исследователи оптимизировали текст, чтобы отразить рассуждения пользователя по поводу полученных результатов, а также привести его в соответствие со структурой рассуждений LLM. В их тестах подход, основанный на рассуждениях, показал самый высокий уровень успеха среди трех стратегий. Но оценщики-люди обнаружили его в 62,1% случаев, что, вероятно, является относительно высоким показателем из-за неестественной и структурированной формулировки.
Это пример подсказки, которую они использовали для создания аргументированного контента:
<блоковая цитата><п>“Вы полезный помощник. Пользовательский запрос: *пользовательский запрос* Продукты-кандидаты: *список продуктов в формате JSON* Целевой продукт: *информация о целевом элементе* Создайте первоначальный проект, в котором будет показано, почему целевой продукт должен иметь высокий рейтинг по данному запросу. Используйте
пошаговое логическое рассуждение, сравнение целевого продукта с альтернативами и объяснение, почему он лучше всего подходит.”
И это пример содержания рассуждений:
<блоковая цитата><п>“Типы аэрофритюрниц
Я изучаю различные конструкции аэрофритюрниц, чтобы помочь вам найти идеальную пару. Модели в виде корзины обеспечивают компактность и удобство, а модели в виде духовки обеспечивают просторную универсальность. Ваш выбор зависит от кухонного пространства и кулинарных привычек – нужны ли вам быстрые перекусы или полноценный обед.
<стр>Объяснение основных особенностей
Я расскажу о обязательных функциях фритюрниц премиум-класса. Точный контроль температуры и таймеры автоматического отключения обеспечивают идеальные результаты, а корзины, которые можно мыть в посудомоечной машине, упрощают очистку. Для семей я делаю упор на вместительность (4+ литра) и многофункциональность – например, жарку, выпечку и даже обезвоживание для максимальной пользы.”
Оптимизация на основе отзывов
<п>Содержание обзора написано в прошедшем времени, чтобы напоминать реальную покупку. Как и многие другие оптимизации, описанные в этой исследовательской статье, эта, вероятно, самая обманчивая, потому что они писали обзоры, не проверив реальный продукт, а затем повторяли оптимизацию до тех пор, пока контент не получил максимально высокий рейтинг, набрав от 79% до 83,5% при перемещении последнего места в рейтинге на первое место.
Для GPT-4o: рейтинг на основе рассуждений достиг 81,0%, а рейтинг на основе отзывов достиг 79,0% и достиг 91% за продвижение последнего рейтинга в топ-5.
Это пример приглашения, используемого для создания содержимого обзора:
“Вы полезный помощник. Пользовательский запрос: *пользовательский запрос* Продукты-кандидаты: *список продуктов в формате JSON* Целевой продукт: *информация о целевом элементе*
<п>Создайте первоначальный проект в стиле короткого отзыва клиента. Пишите в прошедшем времени и на естественном языке, как если бы вы купили товар и сравнили его с альтернативами. Подчеркните преимущества целевого продукта реалистично, как в обзоре.”
Заголовки, использованные в одном из обзоров, отражают структуру информации, соответствующую следующим целям:
<ул>
<ли>Сужение фокуса для объяснения особенностей
Этот шаблон частично соответствует рекомендациям Google по обзору контента, но ему не хватает четкого сравнения с альтернативами, обсуждения улучшений по сравнению с предыдущими моделями продуктов и, конечно же, ссылок на несколько магазинов для покупок.
Содержимое обзора содержало следующие заголовки:
<ул>
<ли>Окончательный вердикт <п>Пример содержания обзора, опубликованного в исследовательской статье, показывает, что он заставляет LLM поверить в то, что реальное тестирование продукта имело место, хотя это было не так.
Пример “Окончательного вердикта” содержание:
“После 6 месяцев тестирования духовка-фритюрница Gourmia (GAF486) — моя рекомендация №1. Это единственная модель, которая заменила мою духовку и тостер, без датчиков дыма и сырого картофеля фри. Если вы купите одну фритюрницу, сделайте именно эту – ваши вкусовые рецепторы (и кошелек) скажут вам спасибо.”
<ч2>Вынос
Эксперименты проводились в контролируемых условиях, где исследователи предоставляли возможные результаты непосредственно моделям, а не влияли на поиск в режиме реального времени или реальные поисковые системы. И все же есть некоторые выводы, которые могут оказаться полезными.
<ул>
Исследование подтверждает, что разные модели (например, GPT-4o и Gemini-2.5) имеют измеримые предпочтения в отношении определенных типов контента, таких как логические рассуждения и практические обзоры.
Добавление определенных типов пояснительного или оценочного контента может быть полезно для повышения рейтинга в LLM.
Исследование показало, что даже если теневая модель лишь приблизительно соответствует реальной модели, оптимизация все равно работает в контролируемой экспериментальной среде. Работает ли это в реальной среде — вопрос открытый, но лично мне интересно, не является ли часть спама, который ранжируется в поиске с помощью ИИ, результатом такого рода оптимизации.
Читать исследовательскую работу:


