
<стр>Новое исследование поведения пользователей, показывающее, как пользователи режима искусственного интеллекта принимают короткие списки, созданные LLM, в то время как пользователи классического поиска Google создают их сами.
Повышайте свои навыки с помощью еженедельной экспертной информации Growth Memo. Подпишитесь бесплатно!
<п>Режим искусственного интеллекта сжимает этап, на котором покупатели сравнивают, отвергают и открывают для себя бренды самостоятельно. Наше новое исследование удобства использования 185 задокументированных задач покупки показывает, что 74% окончательных списков режима искусственного интеллекта были получены непосредственно из результатов искусственного интеллекта – никакой внешней проверки, никакой триангуляции, никакого второго мнения.
Этот анализ будет охватывать:
<ул>
Почему мы провели исследование
AI преобразует поиск из списка результатов в список рекомендаций (короткий список). До сих пор мы понятия не имеем, как пользователи относятся к шорт-листам ИИ. Принимают ли они это за чистую монету или тщательно подтверждают это?
Вот почему я сотрудничал с Citation Labs и Clickstream Solutions, чтобы записывать реальных пользователей и их взаимодействие при совершении дорогостоящих покупок. Это исследование удобства использования, в котором приняли участие 48 участников, выполнивших 185 задач по крупным покупкам, показывает, что режим AI работает как рекомендуемая среда, а не как среда сравнения.
При традиционном поиске люди просматривают результаты, сравнивая источники, чтобы собрать набор кандидатов. В режиме ИИ они принимают кандидатов ИИ и двигаются дальше. 74% коротких списков режима ИИ были получены непосредственно с выходных данных ИИ без какой-либо внешней проверки. При традиционном поиске более половины пользователей создали собственный список с нуля.
<п>Исследование охватывает четыре категории (телевизоры, ноутбуки, стиральные и сушильные машины и автострахование). Участники выполнили задания, используя как режим искусственного интеллекта, так и традиционный поиск в рамках внутрипредметного A/B-проекта, выполнив 149 наблюдений за выполнением задач в режиме искусственного интеллекта и 36 поисковых наблюдений. Поведенческие модели достаточно согласованы между категориями и участниками, чтобы иметь вес. (Полный план исследования будет в конце.)
<стр>От Гаррета Френча, основателя Citation Labs:
“В режиме искусственного интеллекта покупатели часто используют синтез короткого списка, чтобы сократить когнитивные усилия стандартного поиска и сравнения. Это повышает ценность ресурсов для принятия решений на месте и сторонних источников, которые предоставляют ИИ четкие компромиссы, конкретные доказательства и достаточную контекстуальную структуру для уверенного описания предложения бренда.”
<стр>От Эрика Ван Баскирка:
Отсутствие разочарования в узости является наиболее интеллектуально значимым открытием. 15 % в режиме искусственного интеллекта против 11 % в режиме поиска, без значимой статистической разницы. Это открытие исключает очевидное альтернативное объяснение: пользователи приняли короткий список ИИ, потому что чувствовали себя в ловушке. Они не сопротивлялись. Они не были разочарованы. Они остались довольны. Это усложняет отказ от принятия.
<п>Вот что произошло.
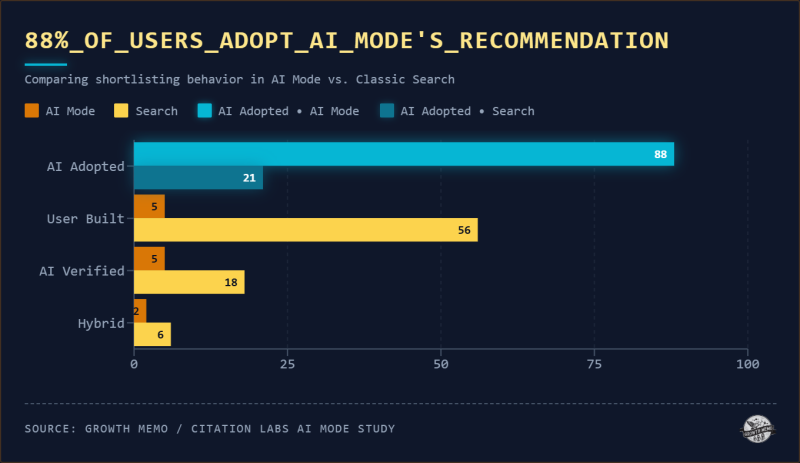
<сильный>1. 88% пользователей сразу выбрали шорт-лист AI
В задачах по ноутбуку и страхованию, где участники использовали обе поверхности поиска (классический поиск и режим искусственного интеллекта), разрыв в составлении списка продуктов был сильным.
Изображение предоставлено: Кевин Индиг
Определения:
<ул>
При классическом поиске 56% участников составили собственный список из нескольких источников. В режиме искусственного интеллекта только 8 из 147 кодируемых задач составляли действительно собственный список. Процесс сравнения пользователя не просто сокращался при использовании режима AI. Для большинства участников этого вообще не произошло.
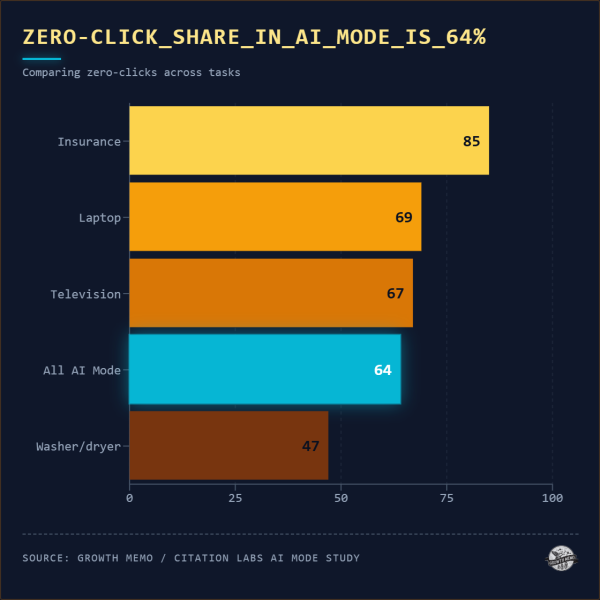
64% участников режима AI вообще ничего не нажимали во время выполнения задания. Они читали текст ИИ, иногда просматривали встроенные фрагменты продуктов и объявляли своих финалистов. Показатель отсутствия кликов варьировался в зависимости от категории:
.
Изображение предоставлено: Кевин Индиг
Самое большое количество делегировали участники страховой отрасли. Участники, участвовавшие в выборе стиральной/сушильной машины, нажимали больше всего, вероятно, потому, что решения об использовании устройства связаны с конкретными физическими ограничениями (емкостью, совместимостью штабелирования, размерами), которые не всегда учитывались в обзоре AI.
36%, которые взаимодействовали с отдельными результатами в режиме AI, разделились на 2 группы:
<ул>
Отдельные <сильные>23% всех задач в режиме ИИ включали хотя бы одно посещение внешнего веб-сайта, в основном ритейлеры (Best Buy фигурировала в 10 из 34 задач с внешними посещениями) и сайты производителей. Шаблон назначения имеет значение: пользователи выходили из режима ИИ, чтобы подтвердить кандидата, которого они уже приняли из списка ИИ, а не искать новых.
Из 117 участников, которые напрямую приняли короткий список ИИ, примерно 85% вообще не проявили никакого поведения при внутренней проверке. Участники, составившие свои собственные списки, потратили в среднем на 89 секунд больше времени и обратились более чем в два раза к большему количеству источников.
<ул>
<ли>Другой пользователь режима искусственного интеллекта заметил: «Мне он понравился больше, чем что-либо еще, что я когда-либо использовал для поиска продуктов». Это значительно ускорило поиск вариантов.” Они воспринимали скорость как ценную функцию, а не как ярлык.
В классическом поиске картина обратная. Почти 89% участников нажали на что-нибудь.
<ул>
<сильный>2. Лучший выбор ИИ становится лучшим выбором пользователя в 74% случаев
<п><сильный>Как и в классическом поиске, верхний ответ имеет огромный вес. 74% участников выбрали элемент, занимающий первое место в ответе ИИ, в качестве своего лучшего выбора. Средний рейтинг окончательного выбора составил 1,35. Только 10% выбрали что-то третье или ниже.
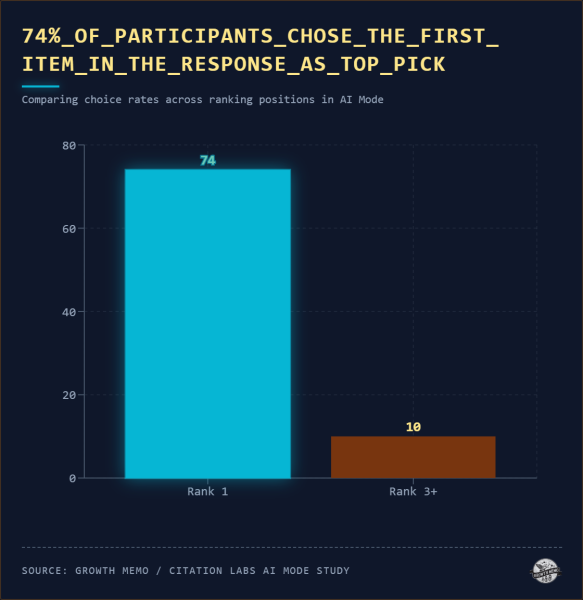
Изображение предоставлено: Кевин Индиг <п>Первая позиция в выводе ИИ имеет огромное преимущество из-за того, где она находится: внутри курируемого раздела, который обычно содержит от двух до пяти элементов, после того как ИИ уже выполнил фильтрацию. Первый предмет — лучший выбор ИИ. Когда люди используют режим AI, мы знаем, что они читают почти всю информацию: первое исследование режима AI показало, что пользователи тратят от 50 до 80 секунд на чтение результатов режима AI, что более чем вдвое превышает время пребывания в обзорах AI. Пользователи читают внимательно. Они просто читают в наборе, где ИИ уже сузился.
Однако 26% участников этого исследования нарушили порядок рангов. Движущая сила: узнаваемость бренда.Они заметили бренд ниже в списке и отдали ему предпочтение независимо от того, где его поместил ИИ. Больше всего это наблюдалось в категориях телевизоров и ноутбуков, где участники прибыли с существующими предпочтениями в отношении Samsung, LG, Apple или Lenovo. Но переопределение ранга не означало отказ от результатов ИИ: 81% участников переопределения ранга по-прежнему выбирали из набора кандидатов ИИ.
<сильный>3. Слова ИИ становятся сигналом доверия
“Travelers и USAA на самом деле говорят мне, сколько именно, тогда как State Farm и GEICO указывают проценты. Просто зная точную сумму, я сразу же хочу выбрать Travelers или USAA.”
<стр>Эта цитата отражает основную закономерность доверия в режиме ИИ. Форматирование ИИ повлияло на решение: суммы в долларах и процентные скидки определяли, какие бренды вошли в шорт-лист.
Формирование ИИ (37%), то есть то, как ИИ говорит о продукте, и узнаваемость бренда (34%) были двумя основными факторами доверия в режиме ИИ. Они бегут почти равномерно:
<ул> <ли>Узнаваемость бренда привела к тому, что участники пришли с предпочтениями бренда.
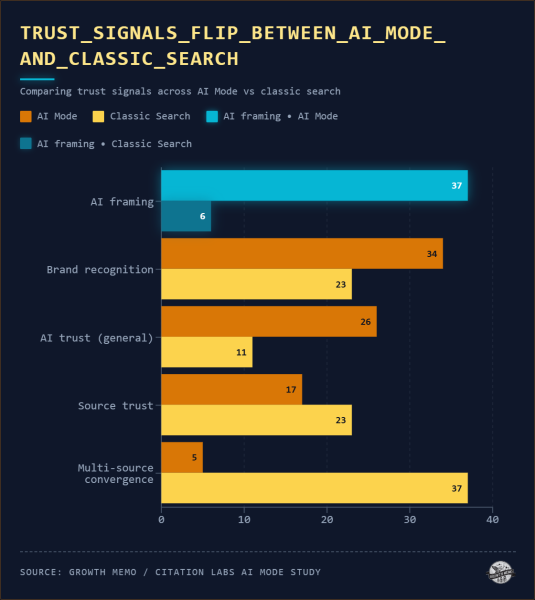
Изображение предоставлено: Кевин Индиг <п>В классическом поиске доминирующим механизмом доверия была конвергенция нескольких источников: участники укрепляли доверие, проверяя, согласны ли несколько независимых источников относительно продукта.
По сути, пользователи триангулировали. Один проверил Progressive, затем GEICO, затем статью Experian. Другой сравнил совокупные звездные рейтинги с отзывами на реальном сайте. Они собирали корпус из отдельных входов.
Такое поведение почти отсутствовало в режиме AI (5%). Вместо этого ИИ-фреймворк (то, как ИИ сформулировал описание продукта) и узнаваемость бренда были двумя главными драйверами доверия.
Распределение между этими двумя сигналами тесно отслеживается в зависимости от категории продукта:
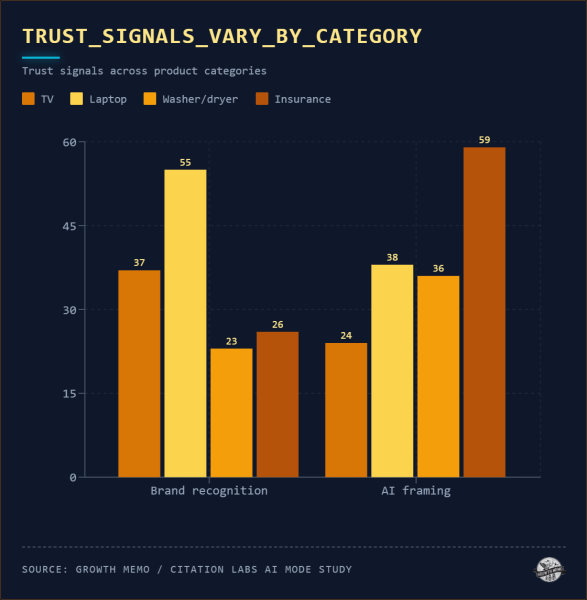
Изображение предоставлено: Кевин Индиг
Для телевизоров и ноутбуков, куда большинство участников пришли с уже существующими предпочтениями бренда, преобладала узнаваемость бренда. В сфере страхования и стиральной/сушильной машины, где у участников было меньше предварительных знаний, преобладал подход ИИ.
Когда вам не хватает предварительного представления, описание ИИ становится сигналом доверия. В режиме AI синтез является подтверждением. Участники отнеслись к резюме ИИ так, как будто за них уже была проведена перекрестная проверка.
<сильный>4. Если вас нет в списке, вас не существует
<п>Результаты покупок в режиме AI сильно концентрируются. Что касается ноутбуков, то на три бренда пришлось 93% всех окончательных выборов в режиме AI. В классическом поиске распределение было шире: варианты HP EliteBook появлялись трижды, ASUS один раз, а другие бренды получали внимание, которого они никогда не получали в режиме AI.
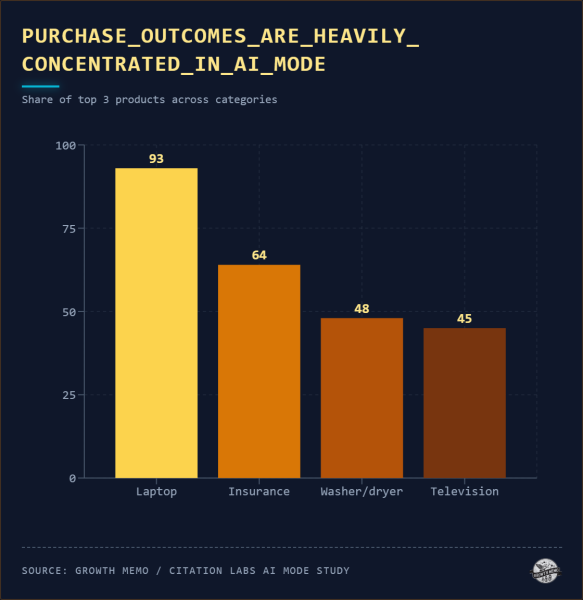
Изображение предоставлено: Кевин Индиг
Возникли две отдельные проблемы:
<ол> <ли><сильный>Бренды, которые никогда не появлялись в продукции ИИ, никогда не рассматривались. Участники их не видели, поэтому не могли их оценить. ИИ решал, кто составил список, а не покупатель.
Другой участник сказал при использовании режима AI: «Мне уже не терпится поверить, что это хорошие рекомендации, потому что в них упоминаются LG и Samsung, два бренда, которые я считаю очень надежными». ИИ не сказал, что эти бренды лучше. Участник сделал вывод об этом по знакомству.
Участники не чувствовали себя скованными из-за более узкого набора. Разочарование от узости возникло в 15% задач в режиме искусственного интеллекта и в 11% классических задач поиска, что статистически неотличимо. Набор опций сократился, но ощущение наличия достаточного количества вариантов не изменилось. Самый скептически настроенный участник режима искусственного интеллекта в группе сравнения, который жаловался, что ИИ продолжает указывать на «водителей-подростков, водителей-подростков, водителей-подростков» и т. д. по-прежнему выбрал GEICO и Travelers: консенсусный результат ИИ.
<сильный>5. Пользователи уходят, чтобы покупать, а не исследовать
<п>23% задач в режиме искусственного интеллекта включали посещение внешних объектов, но имейте в виду, что эти подсказки отражают ситуации с высокими ставками. При стандартном поиске эта цифра составила 67%.
.
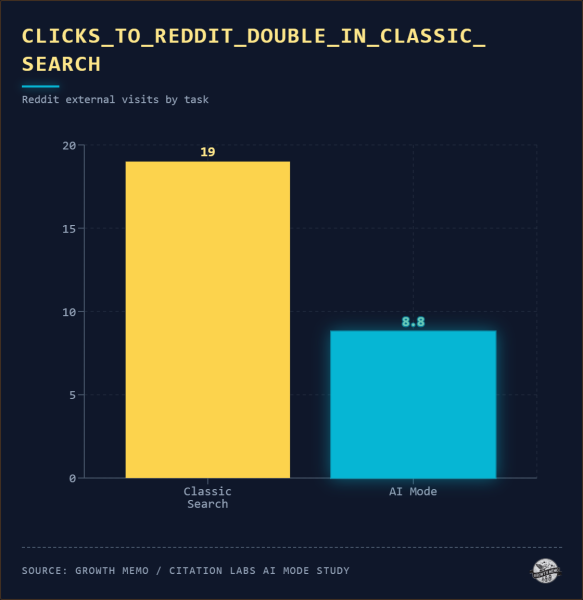
Изображение предоставлено: Кевин Индиг
Разница в громкости имеет меньшее значение, чем разница намерение:
<ул>
<стр>В первом исследовании «Обзоры ИИ» мы обнаружили, что высокий риск заставляет пользователей больше проверять заявления ИИ и ссылаться на ответы других пользователей на платформах пользовательского контента (например, Reddit).
В этом исследовании Reddit появлялся в 19% стандартных поисковых задач и только дважды во всех 149 сеансах режима AI. Уровень мнения коллег, который формирует большую часть традиционного поиска, практически не существует в поведении режима искусственного интеллекта.
<п>В этом есть ирония. Google в значительной степени опирается на контент Reddit для обучения своих моделей. Однако источник, на который пользователи больше всего полагаются при стандартном поиске, — это тот, который они почти никогда не посещают, когда ИИ синтезирует для них те же самые источники.
Первое исследование выявило ту же закономерность в другом масштабе. За 250 сеансов клики были «зарезервированы для транзакций»:” Подсказки к покупке обеспечили самую высокую долю выхода, а подсказки для сравнения — самую низкую. The exit destinations were retailers and brand sites, not editorial or peer-opinion sources. Спустя шесть месяцев и другую задачу, поставленную перед нами, закономерность сохраняется: когда пользователи выходят из режима искусственного интеллекта, они уходят, чтобы покупать.
<сильный>6. 3 рычага: видимость, кадрирование и данные о ценах
<стр>Три вещи, которые меня больше всего волнуют в учебе:
Во-первых, <сильный>мы можем применить ментальную модель ранжирования(выше = лучше) и в режим AI. Большинство пользователей выбирают первый продукт. Теперь мы можем применить это к отслеживанию подсказок, уделив больше внимания подсказкам, которые ведут к коротким спискам, и использовать нашу позицию в качестве ориентира.
Второй, <сильный>доверие превосходит ранг. Мы знаем об этом еще со времен первых исследований поведения пользователей, которые я опубликовал, но это исследование подчеркивает важность построения доверительных отношений с пользователями до того, как они начнут поиск. Это лучший чит-код.
В-третьих, теперь мы знаем, что <сильные>покупатели доверяют рекомендациям ИИ. Очевидно, что здесь существует высокий риск, если ИИ ошибается, но то, как быстро покупатели принимают рекомендации ИИ, также показывает нам, насколько быстро потребители принимают ИИ. Это действительно будущее Поиска.
Имейте в виду:
<п><сильный>1. Видимость на уровне модели — это новый порог. Если режим искусственного интеллекта не отображает ваш бренд, у вас есть проблемы с видимостью на уровне модели. Запросите свою категорию так, как это сделал бы покупатель (например, «лучшая страховка автомобиля для семьи с водителем-подростком», «лучшая стирально-сушильная машина стоимостью менее 2000 долларов США») и задокументируйте, какие бренды появляются, в каком порядке и в каких рамках. Сделайте это с несколькими вариантами приглашений. Делайте это регулярно, потому что реакция ИИ со временем меняется.
<п><сильный>2. То, как ИИ описывает вас, имеет такое же значение, как и то, как он выглядит. Бренды, упоминаемые с конкретными атрибутами (конкретная модель, конкретная цена, названный вариант использования), занимают более сильные позиции, чем бренды, описанные в целом. Контент на вашем сайте, из которого извлекается ИИ, влияет не только на , вы появляетесь, но также насколько уверенно и конкретно вы появляетесь. Бренд со структурированными данными о ценах, четкими характеристиками продукта и четкими сценариями использования дает ИИ лучший материал для работы.
<п><сильный>3. Для категорий с контекстно-зависимыми ценами режим AI создает проблему ложной уверенности.63% участников страхования были оценены как слишком самоуверенные в отношении цен. Они приняли оценки ставок, предложенные AI, не проверив, применимы ли эти цифры к их фактическому состоянию, водительскому стажу или текущему страховщику. Они приняли решения об исключении, основываясь на цифрах, которые, возможно, к ним не относились. Там, где на торговых панелях были указаны цены, подтвержденные розничным продавцом (стиральная машина/сушилка), 85% участников ясно понимали цены. Там, где этого не было (страховка, ноутбуки), пробел заполнили растерянность и чрезмерная самоуверенность. Структурированные данные о ценах через фиды Merchant Center и наценку схемы – это самый прямой рычаг для брендов, продающих физические товары. Для услуг рычаг является редакционным: убедитесь, что цены на целевые страницы и рамки контента FAQ являются условными (“ваша ставка зависит от X, Y, Z”), чтобы ИИ мог использовать эту структуру.
<сильный>Дизайн исследования
При сравнении режима AI и традиционного стандартного поиска использовался дизайн A/B внутри субъекта: участники использовали обе поверхности, а не одну или другую. Расчеты значимости были нормализованы для точного количества участников в каждой группе (149 наблюдений за задачами в режиме AI, 36 наблюдений за стандартными поисковыми задачами). Это важно, поскольку группы неравны по размеру, и без этой поправки простое процентное сравнение между ними приведет к завышению уверенности.
<п>Сеансы записывались на экран и сопровождались звуком для размышлений вслух. Обученные аналитики аннотировали каждую запись по поведенческим маркерам (клики, происхождение из короткого списка, сигналы доверия, посещения внешних сайтов) и качественным маркерам (заявленные аргументы, упоминание бренда, сигналы разочарования). 185 наблюдений на уровне задач обеспечивают более обширную аналитическую базу, чем предполагает численность 48 участников, но доверительные интервалы остаются шире, чем в крупномасштабном опросе. Результаты носят направленный характер, а не оценки на уровне популяции.
Примечания к терминологии, используемой в этом отчете:
<ул>


