
Предварительное тестирование показало, что применение структурированных данных повышает видимость и стабильность фрагмента, созданного ИИ.
<п>Когда диалоговые ИИ, такие как ChatGPT, Perplexity или Google AI Mode, генерируют фрагменты или сводки ответов, они не пишут с нуля, они выбирают, сжимают и заново собирают то, что предлагают веб-страницы. Если ваш контент не оптимизирован для SEO и не индексируется, он вообще не попадет в генеративный поиск. Поиск, каким мы его знаем, теперь является функцией искусственного интеллекта.
Но что, если ваша страница не “предлагает” в машиночитаемой форме? Вот тут-то и приходят на помощь структурированные данные, не только как SEO-концепция, но и как основа для ИИ, позволяющая надежно выбирать «правильные факты». В нашем сообществе возникла некоторая путаница, и в этой статье я:
<ол>
В последние месяцы многие спрашивали меня, используют ли LLM структурированные данные, и я повторял снова и снова, что LLM не использует структурированные данные, поскольку у него нет прямого доступа к всемирной паутине. LLM использует инструменты для поиска в Интернете и загрузки веб-страниц. Его инструменты – в большинстве случаев – получить большую выгоду от индексации структурированных данных.

Изображение автора, октябрь 2025 г. <п>Согласно нашим ранним результатам, структурированные данные повышают согласованность фрагментов и контекстную релевантность в GPT-5. Это также намекает на расширение эффективного конверта Wordlim – Это скрытая директива GPT-5, которая определяет, сколько слов ваш контент получит в ответ. Представьте это как квоту на видимость вашего ИИ, которая увеличивается, когда контент становится богаче и лучше типизирован. Вы можете прочитать больше об этой концепции, которую я впервые изложил на LinkedIn.
Почему это важно сейчас
<ул>
<блоковая цитата>
Мой личный тезис заключается в том, что мы хотим рассматривать структурированные данные как уровень инструкций для ИИ. Он не “ранжируется для вас,” он стабилизирует то, что ИИ может сказать о вас.
Дизайн эксперимента (97 URL)
Хотя размер выборки был небольшим, я хотел посмотреть, как на самом деле работает уровень поиска ChatGPT при использовании из собственного интерфейса, а не через API. Для этого я попросил GPT-5 выполнить поиск и открыть пакет URL-адресов с разных типов веб-сайтов и вернуть необработанные ответы.
<п>Вы можете предложить GPT-5 (или любой системе искусственного интеллекта) показать дословный вывод своих внутренних инструментов, используя простой мета-подсказку. Собрав ответы поиска и выборки для каждого URL-адреса, я запустил рабочий процесс агента WordLift [отказ от ответственности, наш AI SEO-агент] для анализа каждой страницы, проверки наличия на ней структурированных данных и, если да, определения конкретных обнаруженных типов схем.
В результате этих двух шагов был получен набор данных из 97 URL-адресов, аннотированных ключевыми полями:
<ул>
<п>Использование “LLM в качестве судьи” Используя подход Gemini 2.5 Pro, я затем проанализировал набор данных, чтобы выделить три основных показателя:
<ул>
<х3>Скрытая квота: распаковка “wordlim”
При выполнении этих тестов я заметил еще одну тонкую закономерность, которая может объяснить, почему структурированные данные приводят к более согласованным и полным фрагментам. Внутри конвейера поиска GPT-5 есть внутренняя директива, неофициально известная как wordlim: динамическая квота, определяющая, какой объем текста с одной веб-страницы может превратиться в сгенерированный ответ.
На первый взгляд, это действует как ограничение на количество слов, но он адаптивный. Чем богаче и лучше типизирован контент страницы, тем больше места он занимает в окне синтеза модели.
<п>Из моих постоянных наблюдений: <ул>
Это не произвольно. Предел помогает системам ИИ:
<ол>
Однако это также открывает новые горизонты для SEO: ваши структурированные данные эффективно увеличивают вашу квоту видимости. Если ваши данные не структурированы, вы ограничены минимумом; если это так, вы предоставляете ИИ больше доверия и больше возможностей для продвижения вашего бренда.
<п>Хотя набор данных еще недостаточно велик, чтобы быть статистически значимым по каждой вертикали, первые закономерности уже ясны – и действенно.
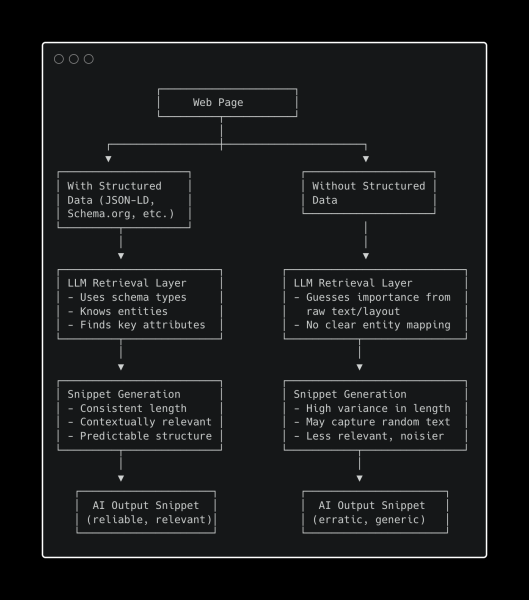
Рис. 1 – Как структурированные данные влияют на создание фрагментов кода ИИ (изображение автора, октябрь 2025 г.) <ч2>Результаты
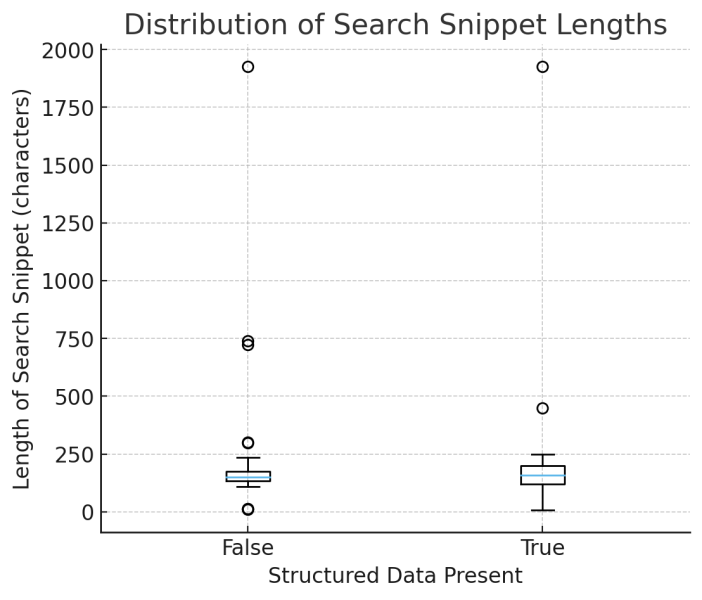
Рис. 2 – Распределение длины поисковых фрагментов (изображение автора, октябрь 2025 г.)
1) Согласованность: фрагменты более предсказуемы при использовании схемы
В прямоугольном графике длины фрагмента поиска (со структурированными данными и без него):
<ул>
<сильный>Интерпретация: Структурированные данные не увеличивают длину; это уменьшает неопределенность. Модели по умолчанию используют типизированные безопасные факты вместо догадок на основе произвольного HTML.
2) Контекстная релевантность: извлечение руководств схемы
<ул>
3) Показатель качества (все страницы)
Усреднение оценки 0–1 по всем страницам:
<ул>
Даже там, где средние значения выглядят одинаково, дисперсия разрушается схемой. В мире искусственного интеллекта, ограниченном объемом слов и издержками на поиск, низкая дисперсия является конкурентным преимуществом.
За пределами согласованности: более богатые данные расширяют границы Wordlim (ранний сигнал)
Хотя набор данных еще недостаточно велик для проверки значимости, мы наблюдали следующую закономерность:
Страницы с более богатыми структурированными данными, состоящими из нескольких объектов, имеют тенденцию давать немного больше времени, поскольку фрагменты до усечения.
Гипотеза. Типизированные взаимосвязанные факты (например, продукт + предложение + бренд + совокупный рейтинг или статья + автор + дата публикации) помогают моделям расставлять приоритеты и сжимать более ценную информацию – – эффективно увеличивая полезный бюджет токенов для этой страницы.
Страницы без схемы чаще преждевременно обрезаются, вероятно, из-за неуверенности в релевантности.
<п>Следующий шаг: мы измерим взаимосвязь между семантическим богатством (количеством различных объектов/атрибутов Schema.org) и эффективной длиной фрагмента. В случае подтверждения структурированные данные не только стабилизируют фрагменты – это увеличивает информационную пропускную способность при постоянном ограничении количества слов.
От схемы к стратегии: Учебник
Мы структурируем сайты как:
<ол>
Почему это работает: Слой сущностей дает ИИ безопасную основу; лексический уровень предоставляет многократно используемые доказательства, которые можно цитировать. Вместе они обеспечивают точность при ограничениях по количеству слов.
Вот как мы преобразуем эти выводы в повторяемую инструкцию по SEO для брендов, работающих в условиях ограничений в области обнаружения ИИ.
<ол>
Храните спецификации, часто задаваемые вопросы и текст политики в виде блоков и связанных объектов.
Факты должны быть согласованными в видимом HTML и JSON‑LD; держите важные факты в секрете и стабильно.
Отслеживайте дисперсию, а не только средние значения. Сравните охват ключевых слов/полей в сводках машин по шаблону.
<ч2>Заключение
Структурированные данные не меняют средний размер фрагментов AI; это меняет их уверенность. Он стабилизирует резюме и формирует то, что они включают. В GPT-5, особенно в агрессивных условиях ограниченного количества слов, эта надежность приводит к более высоким и качественным ответам, меньшему количеству галлюцинаций и большей заметности бренда в результатах, генерируемых ИИ.
Для оптимизаторов и продуктовых команд вывод ясен: относитесь к структурированным данным как к базовой инфраструктуре. Если вашим шаблонам все еще не хватает четкой семантики HTML, не переходите сразу к JSON-LD: сначала исправьте основу. Начните с очистки разметки, а затем наложите структурированные данные поверх нее, чтобы обеспечить семантическую точность и возможность долгосрочного обнаружения. В поиске ИИ семантика — это новая область поверхности.

