
<стр>В этом экспертном анализе рассматриваются этические проблемы и потенциальные преимущества контента, ориентированного на пользователей с помощью ИИ, как для пользователей, так и для издателей.
<п><эм>Повышайте свои навыки с помощью еженедельной экспертной информации в «Записках о росте». Подпишитесь бесплатно!
Стратегия Perplexity, лежащая в основе новой функции Pages, вызвала глубокий раскол среди издателей, но реакция, похоже, преувеличена. Это гораздо интереснее, чем пример использования AI-контента, ориентированного на пользователя (UDC вместо UGC).< /п>
Perplexity Pages позволяет пользователям “создавать красиво оформленные, полные статьи на любую тему” Вы можете превратить ветку, последовательность подсказок, в страницу по теме.
<стр>Как постоянный читатель Growth Memo, вы быстро поймете, что это стратегия роста, при которой в идеале пользователи создают ИИ-контент, который ранжируется в органическом поиске и приводит посетителей на perplexity.ai, которые превращаются в платных подписчиков.
Стратегия роста соответствует тому, что генеральный директор Шринивас называет «агрегатором информации».1 Он удерживает власть, обеспечивая превосходный пользовательский опыт, который позволяет ему направлять спрос и превращать предложение в товар. .
Бросить в ведро
<п>Когда мы смотрим на фактические данные, мы видим, что реакция СМИ преувеличена. Не в критике, а в воздействии. Будет справедливо попросить Perplexity настроить атрибуцию, следовать веб-стандартам, таким как robots.txt, и использовать официальные IP-адреса, как это делают поисковые системы.
По словам разработчика Райана Найта, Perplexity сканирует Интернет с помощью безголового браузера, который маскирует IP-строку.2
Генеральный директор Шринивас сказал, что Perplexity подчиняется файлу robots.txt, а замаскированный IP-адрес получен от стороннего сервиса. Но он также упомянул, что «появление ИИ требует нового типа рабочих отношений между создателями контента или издателями и такими сайтами, как его».
Но с точки зрения пользы от Perplexity, Pages — это капля в море.
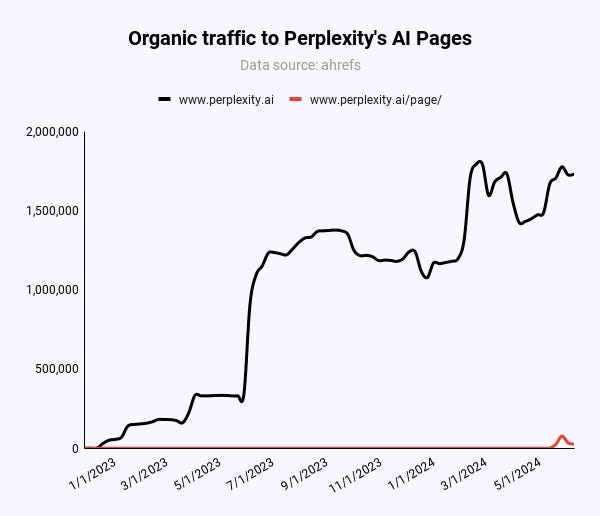
Изображение предоставлено: Кевин Индиг
91% органического трафика на perplexity.ai поступает из таких фирменных терминов, как “perplexity.”
Только 47 000 из 217 000 (21,6%) ежемесячных посетителей страниц во всем мире приходят по органическим, небрендированным ключевым словам.
<п>В США это 55% (20 000/36 000). Однако по сравнению с x ежемесячными посещениями по брендовым запросам Pages не оказывает никакого влияния на органический трафик Perplexity.
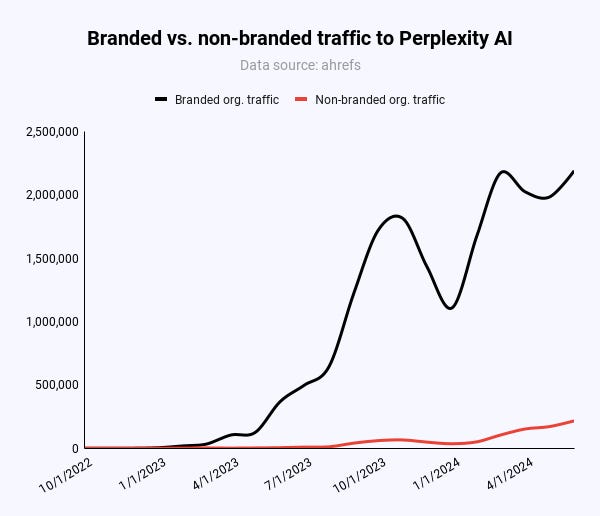
Изображение предоставлено: Кевин Индиг <п>На самом деле большая часть трафика на Perplexity поступает через бренд и сарафанное радио. Недавнее освещение в СМИ, возможно, больше помогло Недоумению, чем навредило. По данным Likeweb, сайт ежедневно достигает новых рекордных максимумов посещаемости, начиная с января 2024 года.
Весь домен Perplexity содержит всего 950 страниц, из которых около 600 страниц. По сравнению с другими сайтами – как и 6,8 миллиона статей в Википедии только по английской версии – это просто не так уж и много. По мере увеличения популярности Pages будет проявляться более сильный эффект масштаба. На данный момент Pages находится на стадии зарождения бета-версии.
Если присмотреться к его эффективности, то можно увидеть, что самое популярное ключевое слово на страницах, по которому оно входит в тройку лучших, — это “была виновата Кэнди Монтгомери” (600МСВ). Самое сложное ключевое слово, по которому он занимает первую позицию, — это «когда была первая покупка биткойнов»? (КД: 76, МСВ: 30). Другими словами, Pages еще предстоит пройти долгий путь.
Сравнение сходства текстов n=1 (!) с GoTranscript между страницей Perplexity для “биткойн-пиццерии” и четыре связанных источника показывают мало доказательств плагиата:
<ол>
<ли>coinedition.com/bitcoin-pizza-day-a-700-million-reminder-of-cryptocurrencys-rise/(15%).

Сравнение текста между статьями Perplexity и NationalToday о Bitcoin Pizza Day (Изображение предоставлено: Кевин Индиг) )
The “пропавший” проблема с атрибуцией, кажется, была исправлена, как показано в примере ниже.
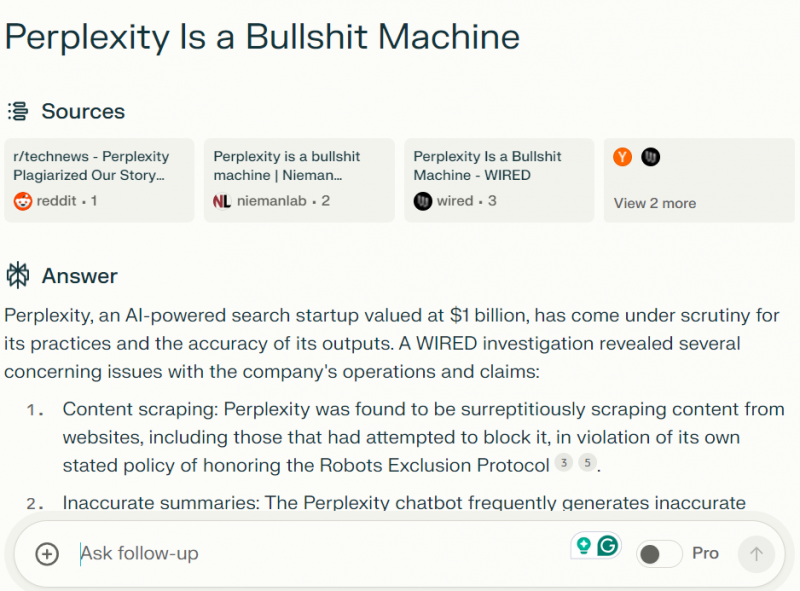
Perplexity выделяет источники ответов вверху (Изображение предоставлено Кевином Индигом) <блоковая цитата><п>Результаты показали, что чат-бот временами перефразировал истории WIRED, а иногда резюмировал истории неточно и с минимальным указанием авторства.
Мне не удалось подтвердить или опровергнуть случаи галлюцинаций, но я ожидаю, что лучшие модели дойдут до того момента, когда смогут безупречно резюмировать существующий контент. Реальность такова, что мы еще не достигли этого. Также было показано, что обзоры искусственного интеллекта Google включают неверные факты или выдумывают их.
<п>Кажется, Google смог быстро решить проблему, поэтому я ожидаю, что степень галлюцинаций снизится.
Одна из основных проблем критики плагиата заключается в том, что поиск по точному названию статьи возвращает именно эту статью.
Конечно, Perplexity должна возвращать краткое содержание статьи, когда пользователи запрашивают ее. Что еще должен показать Perplexity? Тот же аргумент возник в судебном процессе между OpenAI и NY Times.
<ч2>Срабатывает
Помимо проблем со сканированием, которые Perplexity необходимо исправить, реакция СМИ, похоже, вызвана позиционированием Perplexity.
Одно предложение в объявлении Perplexity о Pages отражает суть основной проблемы:
“С Pages вам не обязательно быть опытным писателем, чтобы создавать высококачественный контент.”4
На странице также упоминается:
<блоковая цитата><п>”Создание контента, который находит отклик, может быть трудным. Страницы созданы для ясности, разбивают сложные темы на удобоваримые части и предназначены для всех, от преподавателей до руководителей».”5
Все примеры страниц, перечисленные в объявлении, посвящены “как” или “что такое” темы: <ул>
<ли>“Стив Джобс: генеральный директор-провидец”
Это именно та задача, которую ИИ ставит перед писателями: ИИ может все чаще охватывать четко определенные форматы контента, такие как руководства или учебные пособия. Я понимаю, как это действует на журналистов.
Контент, ориентированный на пользователя
Обратите внимание, что Perplexity не создает весь контент для Pages, а принимает руководство от людей через подсказки ( УДК). <стр>Вместо того, чтобы писать целую статью, люди складывают кусочки головоломки вместе и ставят на страницу биографию своего автора. <п>Я ожидаю, что то же самое произойдет и с другими типами контента, такими как обзоры и платформы, такие как Google, Tripadvisor, Yelp, G2 и другие платформы. Co., чтобы предоставить соответствующие инструменты, упрощающие создание контента. Самой большой проблемой будет сохранение высокого качества и сокращение бесполезной информации до минимума.
Большой вопрос заключается в том, сможет ли такая сборка, как Pages, конкурировать с сайтом, написанным исключительно людьми, таким как Wikipedia, который в настоящее время имеет 116 000 активных участников.6
Большая “Игра роста” за страницами (ИМХО) — это то, как Perplexity создает подкасты с искусственным интеллектом (видео) из обобщенных статей, которые превосходят исходные результаты.
<блоковая цитата><п>«Perplexity затем разослала эту поддельную историю своим подписчикам с помощью мобильного push-уведомления. Он создал подкаст, созданный с помощью искусственного интеллекта, используя ту же отчетность (Forbes) — без какой-либо ссылки на Forbes, и это стало видео на YouTube, которое превосходит весь контент Forbes по этой теме в поиске Google.”7
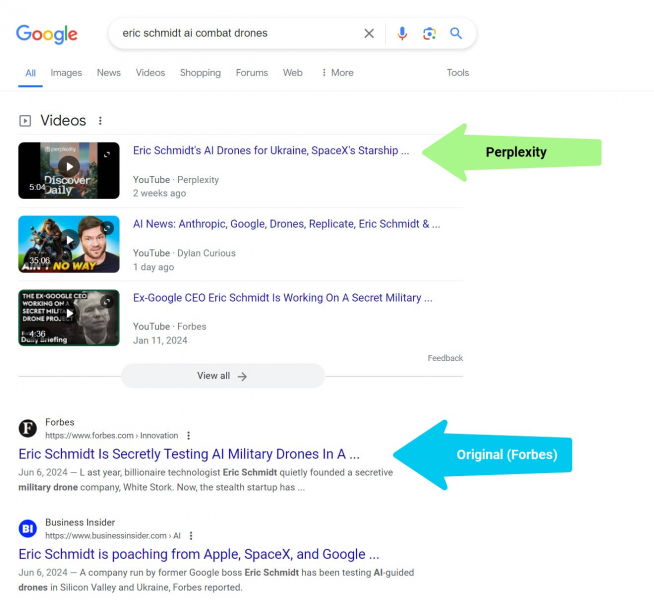
Perplexity опережает издателей, выпускающих видеоподкасты, резюмирующие статьи (Изображение предоставлено Кевином Индигом)
Google придется придумать, как помешать LLM повторно использовать контент издателей.
<п>После изучения фактов остается осознание того, насколько сложно сбалансировать предоставление ИИ отвечать при отправке трафика на источники. Почему пользователи должны кликать, когда на большинство их вопросов есть ответы?
С другой стороны, издатели сами могут предоставлять краткое изложение своих статей. Таким образом, ключевая задача Perplexity – и всем, кто хочет создавать крупномасштабный AI-контент для поиска – добавляет уникальную ценность к сводкам ИИ.
Персонализация
Путь к уникальной ценности обзоров ИИ и другого контента ИИ — это персонализация. <п>Система, которая может распознавать ваши предпочтения в отношении уровня понимания темы, может сделать резюме ИИ более полезными для вас. Perplexity — это оболочка различных LLM, но если она собирает важную информацию о пользователях и персонализирует вывод, она может принести пользу, помимо быстрых ответов.
Производители операционных систем для устройств, такие как Alphabet и Apple, имеют наибольшее преимущество, когда дело касается пользовательских данных, поскольку они находятся на вершине пищевой цепочки.
Ярким примером является Apple Intelligence, которая, вероятно, могла бы ответить на вопросы, которые в настоящее время задаются в руководствах и учебных пособиях в Google или Perplexity.
<п>Apple Intelligence (сокращенно “AI” – здорово, Apple!) имеет полный контекст, включая местоположение (Apple Maps), использование сторонних приложений, подсказки Siri, электронную почту (Apple Mail) и другие источники. , что создает хорошую основу для персонализации результатов. Интернет — это всего лишь один из массивов знаний, гораздо более интересный из которых ждет нас в Dropbox, почтовом ящике Gmail и фотографиях на iPhone.
<стр>Сегодня персонализированные ответы — это идея и демонстрация. <стр>Но в какой-то момент в будущем персонализация даст лучшие ответы, чем любое общее резюме LLM, и уж точно больше, чем любое руководство, написанное человеком.
Ценность определенных и общих знаний находится на пути к столкновению с бомбардировщиками LLM. В то же время ценность персонализированных знаний, человеческого опыта и заслуживающих доверия экспертов стремительно растет.
1 ИИ-стартап Perplexity хочет перевернуть поисковый бизнес. Новостное издание Forbes заявляет, что оно их обдирает; Рост интегратора и агрегатора
2 Недоумение ИИ лжет о своем пользовательском агенте
<стр>3 Генеральный директор Perplexity Аравинд Шринивас отвечает на обвинения в плагиате и нарушении авторских прав
4 Что такое страницы недоумения?
5 Знакомство со страницами недоумения
6 Википедия:О
7 Почему циничная кража в Perplexity представляет собой все, что может пойти не так с ИИ


