
<стр>Узнайте, как компании реализуют инициативы по маркировке контента, чтобы помочь пользователям отличать контент, созданный человеком, от контента, созданного искусственным интеллектом.
Новое масло – это не данные или внимание. Это слова. Отличительной особенностью создания моделей ИИ следующего поколения является доступ к контенту при нормализации вычислительной мощности, хранилища и энергии.
Но Интернет уже становится слишком мал, чтобы утолить голод новыми моделями.
Некоторые руководители и исследователи говорят, что потребность отрасли в высококачественных текстовых данных может превысить предложение в течение двух лет, что потенциально замедлит развитие ИИ.1
Даже точная настройка, кажется, не работает так же хорошо, как простое создание более мощных моделей. Исследование Microsoft показывает, что эффективные подсказки могут превосходить по эффективности точно настроенную модель на 27%.2
Нам интересно, будет ли будущее состоять из множества маленьких, точно настроенных моделей или из нескольких больших, всеобъемлющих моделей. Кажется, последнее.
<стр>Не существует стратегии ИИ без стратегии данных.
Жаждущие более качественного контента для разработки следующего поколения больших языковых моделей (LLM), разработчики моделей начинают платить за естественный контент и возобновляют свои усилия по маркировке синтетических данных.
<п>Для создателей контента любого рода этот новый поток денег может проложить путь к новой модели монетизации контента, которая стимулирует качество и делает Интернет лучше.
Изображение предоставлено: Lyna ™
Повышайте свои навыки с помощью еженедельной экспертной информации в Памятках о росте. Подпишитесь бесплатно!
<ч2>KYC: AI
Если контент — это новая нефть, то социальные сети — это нефтяные вышки. Google инвестировал 60 миллионов долларов в год в использование контента Reddit для обучения своих моделей и вывода ответов Reddit в топ поиска. Пенни, по моему мнению. <стр>Генеральный директор YouTube Нил Мохан недавно ясно дал понять OpenAI и другим разработчикам моделей, что обучение на YouTube бесполезно, поскольку это защищает огромные запасы нефти компании.
The New York Times, которая в настоящее время подает иск против OpenAI, опубликовала статью, в которой говорится, что OpenAI разработала Whisper для обучения моделей на транскриптах YouTube, а Google использует контент со всех своих платформ, таких как Google Docs и Обзоры карт для обучения моделей ИИ.
<п>Поставщики данных генеративного ИИ, такие как Appen или Scale AI, нанимают авторов (людей) для создания контента для обучения моделям LLM. <стр>Не заблуждайтесь, писатели не разбогатеют, писая для ИИ. <стр>За 25–50 долларов в час писатели выполняют такие задачи, как ранжирование ответов ИИ, написание коротких рассказов и проверка фактов. <п>Кандидаты должны иметь степень доктора философии. или степень магистра или в настоящее время учатся в колледже. Поставщики данных явно ищут экспертов и «хороших» специалистов. писатели. Но первые признаки обнадеживают: написание статей для ИИ может быть монетизировано.

Изображение предоставлено: Кевин Индиг
Изображение предоставлено: Кевин Индиг
Разработчики моделей ищут хороший контент во всех уголках сети, и некоторые из них с радостью его продают.
Платформы контента, такие как Photobucket, продают фотографии по цене от пяти центов до одного доллара за штуку. Короткие видеоролики могут стоить от 2 до 4 долларов; Более длинные фильмы стоят от 100 до 300 долларов за час съемки. <стр>Благодаря миллиардам фотографий компания нашла нефть на своем заднем дворе. Какой генеральный директор сможет устоять перед таким искушением, особенно учитывая, что монетизация контента становится все сложнее и сложнее?3
<стр>Из бесплатного контента:
Издателей давят с нескольких сторон:
<ул>
Мало кто готов к смерти сторонних файлов cookie. Социальные сети отправляют меньше трафика (Мета) или ухудшают качество (X). Большинство молодых людей получают новости из TikTok. SGE маячит на горизонте. <п>По иронии судьбы, более правильная маркировка контента ИИ может помочь развитию LLM, потому что так легче отделить природный контент от синтетического.
В этом смысле в интересах разработчиков LLM маркировать контент ИИ, чтобы они могли исключить его из обучения или использовать правильно.
Маркировка
Подбор слов для обучения студентов-магистров права — это лишь одна сторона разработки моделей искусственного интеллекта следующего поколения. Другое дело — маркировка. Разработчикам моделей нужна маркировка, чтобы избежать краха модели, а обществу она нужна как щит от фейковых новостей.
<п>Новое движение по маркировке ИИ растет, несмотря на то, что OpenAI отказывается от водяных знаков из-за низкой точности (26%). с помощью метода кнута и пряника.
Google использует двойной подход для борьбы со спамом, создаваемым искусственным интеллектом в поиске: на видном месте отображаются форумы, такие как Reddit, где контент, скорее всего, создается людьми, и штрафы.
От AIЭффективность:
Google размещает больше контента с форумов в поисковой выдаче, чтобы уравновесить контент ИИ. Верификация — это лучший водяной знак ИИ. Несмотря на то, что Reddit не может помешать людям использовать ИИ для создания публикаций или комментариев, шансы ниже из-за двух вещей, которых нет в поиске Google: модерации и кармы.
<п>Да, Контентные гоблины уже нацелились на Reddit, но большинство из 73 миллионов ежедневных активных пользователей дают полезные ответы1. Модераторы контента наказывают спам банами или даже пинками. Но самым мощным фактором качества на Reddit является Карма, «оценка репутации пользователя, отражающая его вклад в сообщество». Простыми голосами «за» или «против» пользователи могут получить авторитет и надежность — два неотъемлемых компонента системы качества Google.
<п>Google недавно пояснил, что ожидает, что продавцы не будут удалять метаданные AI из изображений с помощью протокола метаданных IPTC.
Когда изображение имеет тег типа compositeSynthetic, Google может пометить его как “созданное искусственным интеллектом” где угодно, а не только в магазинах.5 Наказание за удаление метаданных ИИ неясно, но я представляю это как штраф за ссылку.
IPTC — это тот же формат, который Meta использует для Instagram, Facebook и WhatsApp. Обе компании присваивают метатеги IPTC любому контенту, исходящему из их собственных LLM. Чем больше производителей инструментов ИИ следуют одним и тем же правилам при маркировке и тегировании контента ИИ, тем надежнее работают системы обнаружения.
<блоковая цитата><п>Когда фотореалистичные изображения создаются с помощью нашей функции Meta AI, мы делаем несколько вещей, чтобы люди знали об использовании искусственного интеллекта, в том числе размещаем видимые маркеры , которые вы можете видеть на изображениях, а также невидимые водяные знаки& nbsp;и метаданные, встроенные в файлы изображений. Использование невидимых водяных знаков и метаданных повышает надежность этих невидимых маркеров и помогает другим платформам их идентифицировать.6
Недостатки ИИ-контента невелики, когда контент выглядит как ИИ. Но когда контент ИИ выглядит реальным, нам нужны ярлыки.
<п>В то время как рекламодатели стараются уйти от внешнего вида искусственного интеллекта, контент-платформы предпочитают его, потому что его легко узнать.7
Для художников и рекламодателей генеративный искусственный интеллект способен значительно ускорить творческий процесс и предоставлять клиентам персонализированную рекламу в больших масштабах – – что-то вроде Святого Грааля в мире маркетинга. Но есть одна загвоздка: многие изображения, генерируемые моделями искусственного интеллекта, имеют мультяшную плавность, явные недостатки или и то, и другое.
Потребители уже восстают против “внешности искусственного интеллекта” настолько, что сверхъестественную и кинематографическую рекламу христианской благотворительной организации He Gets Us на Суперкубке обвинили в том, что она рождена искусственным интеллектом – хотя ее изображения создал фотограф.
YouTube начал применять новые рекомендации для создателей видео, согласно которым реалистично выглядящий контент с искусственным интеллектом должен быть помечен.8
<блоковая цитата><п>Проблемы, создаваемые генеративным ИИ, постоянно находятся в центре внимания YouTube, но мы знаем, что ИИ создает новые риски, которыми злоумышленники могут попытаться воспользоваться во время выборов. ИИ может использоваться для создания контента, который может ввести зрителей в заблуждение – особенно если они не знают, что видео было изменено или создано искусственно. Чтобы лучше решить эту проблему и информировать зрителей, когда контент, который они смотрят, изменен или синтезирован, мы начнем вводить следующие обновления:
<ул>
Самый большой неизбежный страх — это фальшивый контент ИИ, который может повлиять на ситуацию в США в 2024 году. президентские выборы.
<п>Ни одна платформа не хочет быть Facebook 2016 года, репутация которого серьезно пострадала и отразилась на цене ее акций.
Китайские и российские государственные деятели уже экспериментировали с фейковыми новостями об искусственном интеллекте и пытались вмешаться в дела Тайваня и будущих США. выборы.10
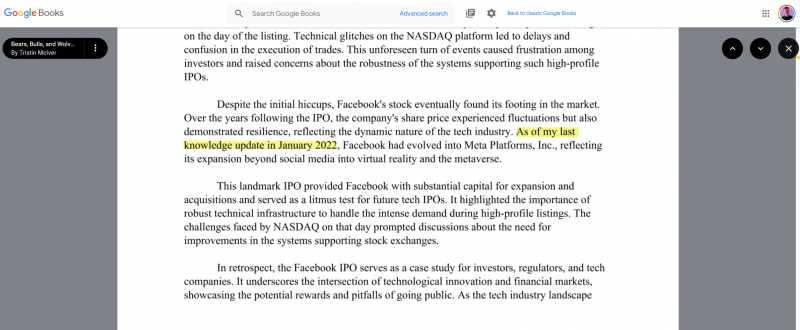
Теперь, когда OpenAI близка к выпуску Sora, которая создает гиперреалистичные видеоролики из подсказок, нетрудно представить, как видеоролики AI могут вызывать проблемы без строгой маркировки. Ситуацию сложно взять под контроль. В Google Книгах уже есть книги, явно написанные с помощью ChatGPT.11
Изображение предоставлено: Кевин Индиг <ч2>На вынос <п>Ярлыки, мысленные или визуальные, влияют на наши решения. Они аннотируют мир для нас и обладают силой создавать или разрушать доверие. Подобно эвристике категорий в покупках, метки упрощают принятие решений и фильтрацию информации.
От Messy Middle:
<блоковая цитата><п>Наконец, идея эвристики категорий, чисел, на которые обращают внимание клиенты для упрощения принятия решений, например, мегапикселей для камер, предлагает путь для оптимизации поведения пользователей. Например, интернет-магазин, продающий камеры, должен оптимизировать свои карточки товаров, чтобы визуально расставить приоритеты эвристики категорий. Конечно, сначала вам нужно понять эвристику в ваших категориях, а они могут различаться в зависимости от продукта, который вы продаете. Я думаю, это то, что нужно для достижения успеха в SEO в наши дни.
Скоро лейблы будут сообщать нам, когда контент написан искусственным интеллектом или нет. В ходе публичного опроса 23 000 респондентов компания Meta обнаружила, что 82% людей хотят иметь ярлыки на контенте ИИ.12 Пока неясно, сработают ли общие стандарты и наказания, но срочность есть.
<стр>Здесь также есть возможность: лейблы могут привлечь внимание к писателям-людям и сделать их контент более ценным, в зависимости от того, насколько хорошим станет контент ИИ. <п>Кроме того, написание статей для ИИ может стать еще одним способом монетизации контента. Хотя нынешние почасовые ставки никого не делают богатыми, обучение моделей добавляет контенту новую ценность. Контент-платформы могут найти новые источники дохода.
Веб-контент стал чрезвычайно коммерциализирован, но лицензирование ИИ может стимулировать авторов снова создавать хороший контент и освободиться от партнерских или рекламных доходов.
Иногда контраст делает ценность видимой. Возможно, ИИ все-таки сможет сделать Интернет лучше.
1 Для компаний, занимающихся ИИ, поглощающих данные, Интернет слишком мал
<стр>2 Сила подсказки
3 В подпольной гонке крупных технологических компаний за покупкой данных для обучения ИИ
4 OpenAI отказывается от инструмента обнаружения текста, сгенерированного искусственным интеллектом
5 Метаданные фотографий IPTC
6 Маркировка изображений, созданных искусственным интеллектом, в Facebook, Instagram и в тредах
7 Как рекламная индустрия делает изображения ИИ менее похожими на ИИ
<стр>8 Как мы помогаем авторам раскрывать измененный или синтетический контент
9 Борьба с дезинформацией о выборах, сгенерированной ИИ
10 Китай нацелился на США. Избиратели и Тайвань с дезинформацией, основанной на искусственном интеллекте
11 Google Книги индексируют мусор, созданный искусственным интеллектом
<стр>12 Наш подход к маркировке контента, созданного искусственным интеллектом, и манипулируемых медиа


