
Большинство советов по написанию AI SEO не выдерживают масштаба. В этой памятке подробно описано, что на самом деле вознаграждает ИИ внутри прочитанного контента и по вертикалям.
Повышайте свои навыки с помощью еженедельной экспертной информации Growth Memo. Подпишитесь бесплатно!
<стр>В книге «Наука о том, как ИИ обращает внимание» Я проанализировал 1,2 миллиона ответов ChatGPT, чтобы понять, как именно ИИ читает страницу. В книге «Наука о том, как ИИ выбирает свои источники» Я проанализировал 98 000 строк цитирования, чтобы понять, какие страницы вообще попадают в пул чтения.
<п>Это часть 3.
Там, где в части 1 указано куда на странице, которую смотрит ИИ, а в части 2 рассказывается какие страницы ИИ обычно рассматривает, эта часть сообщает вам что ИИ на самом деле вознаграждает внутри контента, который он читает.
Данные уточняют:
<ул>
<х2>1. Определенные сигналы письма влияют на цитирование, а другие вредят ему
В то время как “Наука о том, как ИИ обращает внимание” охватывает части страницы и типы текста, влияющие на видимость ChatGPT, я хотел понять, какие сигналы уровня письма – – количество слов, структура, стиль языка – прогнозировать более высокие показатели цитирования ИИ по вертикалям.
<ч3>Подход <ол> <ли>Я сравнил страницы с высокой цитируемостью (более трех уникальных подсказок) и страницы с низкой цитируемостью по семи показателям письма: количество слов, определенный язык, хеджирование, элементы списка, плотность именованных объектов и сигналы, специфичные для вступления.
Результаты: Во всех вертикалях важна четкая формулировка и включение соответствующих объектов. Но большинство сигналов плоские.
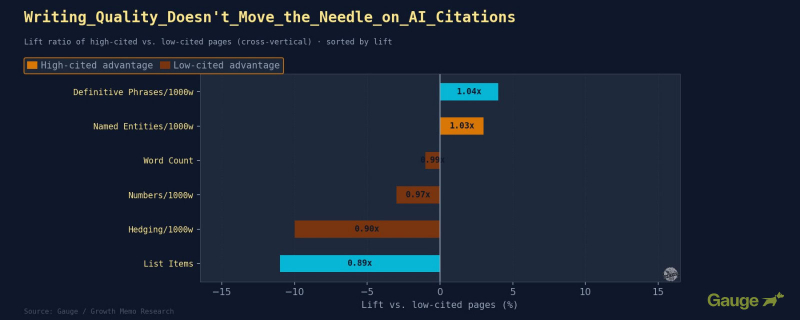
Изображение предоставлено: Кевин Индиг
Что показали тенденции в отрасли
При разделении данных по вертикали мы внезапно видим предпочтения:
<ул>

Изображение предоставлено: Кевин Индиг <ч3>Лучшие блюда на вынос <п><сильный>1. Не существует универсального метода «пишите так, чтобы вас цитировали». формула. Например, сигналы, которые повышают показатели цитируемости CRM/SaaS, активно вредят финансам. Вместо этого сопоставьте формат контента с вертикальными нормами.
<п><сильный>2. Единственное универсальное правило: начинать с прямого декларативного заявления. Не вопрос, не установка контекста, не преамбула. Форма: “[X] равно [Y]” или “[X] выполняет [Z].” Это единственная инструкция записи, которая действует независимо от вертикали, типа контента или длины.
<п><сильный>3. LLM “штрафовать” подстраховка в вашем вступлении.“Это может помочь командам понять” показывает худшие результаты, чем “Команды, которые делают X, видят Y” Удалите квалификаторы из первого абзаца перед любой другой оптимизацией.
<х2>2. Типы сущностей, которые предсказывают цитирование, не являются целью
<стр>Большая часть рекомендаций УЭО сосредоточена на названных объектах как на категории: упакуйте более известные торговые марки, названия инструментов, номера. Приведенный ниже анализ типов кросс-вертикальных объектов рассказывает более конкретную (и более полезную) историю.
<ч3>Подход <ол> <ли>Запустил API естественного языка Google для первых 1000 символов (около 200–250 слов) каждого уникального URL-адреса.
* Небольшое замечание по терминологии: Google NLP классифицирует программные продукты, приложения и инструменты SaaS как CONSUMER_GOOD, устаревший ярлык, существовавший с тех пор, как API был создан для физической розничной торговли. В этом анализе CONSUMER_GOOD означает объекты программного обеспечения/продукта.
Результаты: ДАТА и НОМЕР — наиболее универсальные положительные сигналы. Интересно, что ЦЕНА – самый сильный универсальный негатив.
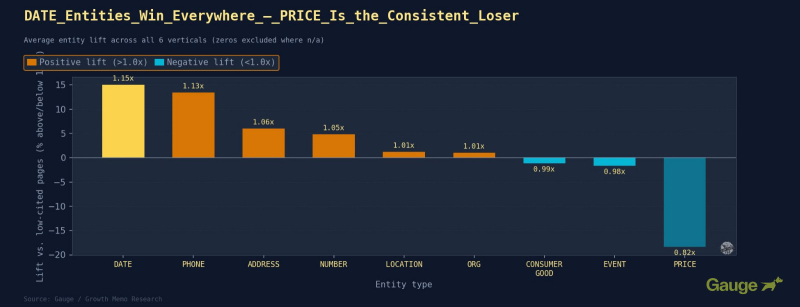
Изображение предоставлено: Кевин Индиг
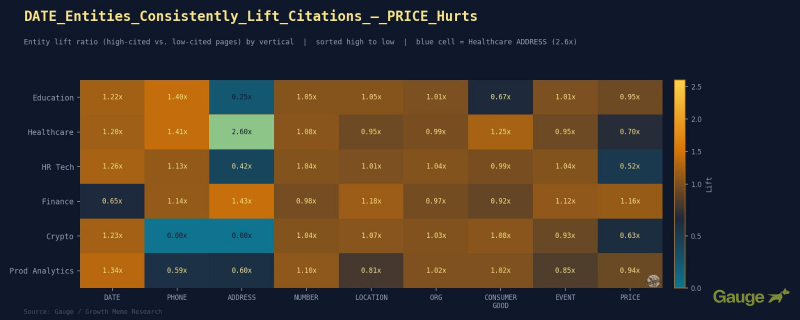
Изображение предоставлено: Кевин Индиг <х3>Что показали отраслевые тенденции
<ул>
<ли><сильный>CONSUMER_GOOD(субъекты программного обеспечения/продукта) является смешанным. В здравоохранении субъекты продукта сигнализируют об устоявшихся брендах и инструментах. В криптографии присвоение имен конкретным протоколам и продуктам является основой ответа на технические вопросы.
Инверсия Графа Знаний заслуживает отдельного упоминания:
<ул> <ли>Данные показали, что страницы с высокой цитируемостью в среднем составляют 1,42 объекта, проверенных KG, по сравнению с 1,75 для страниц с низкой цитируемостью (подъем: 0,81x).
<ч3>Лучшие блюда на вынос <п><сильный>1. Добавьте дату публикации на свои страницы и постарайтесь использовать хотя бы одно конкретное число в своем контенте. Эта комбинация наиболее близка к универсальному сигналу цитирования ИИ, который генерирует этот набор данных. Но вместо этого финансы достигают цели через данные о ценах и специфику местоположения.
<п><сильный>2. Избегайте вступлений с ценами в нефинансовых отраслях. Вступительные объявления с доминированием цены коррелируют с более низким уровнем цитируемости.
<п><сильный>3. Присутствие КР и авторитет бренда не приводят к преимуществу цитирования ИИ. Погоня за записями в Википедии, панелями брендов или проверкой КИ – неправильный рычаг. Конкретные нишевые организации (даже те, у которых нет записей в КР) превосходят известные.
<х2>3. Структура заголовка: выберите один или не беспокойтесь
Мы знаем, что заголовки важны для цитирования из двух предыдущих анализов. Далее я хотел понять, влияет ли количество заголовков на уровень цитируемости и зависит ли оптимальная структура от вертикали.
<ч3>Подход <ол>
<ли>Страницы сгруппированы в 7 групп по количеству заголовков: 0, 1–2, 3–4, 5–9, 10–19, 20–49, 50+.
.
Результаты: Включение большего количества заголовков в ваш контент не всегда лучше. Золотая середина зависит от вертикали и типа контента. Один вывод справедлив повсюду: как ни странно, 3-4 заголовка хуже нуля.
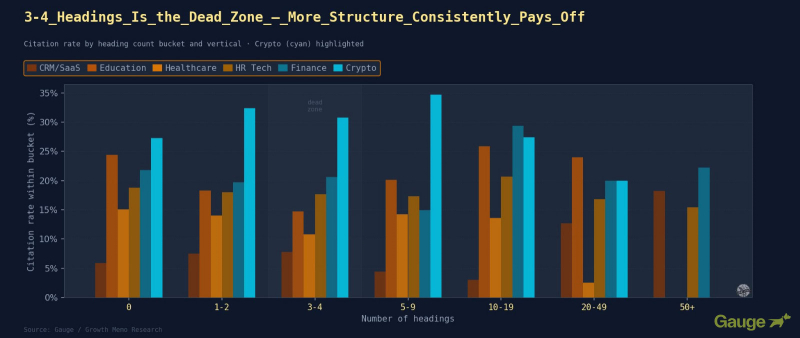
Изображение предоставлено: Кевин Индиг
Что показали тенденции в отрасли
<ул>
<ли><сильный>Образованиеодинаков для всех значений количества заголовков, что согласуется с обнаружением сигналов письма. Структура заголовков почти ничего не объясняет о вероятности цитирования в образовательном контенте.
<ч3>Лучшие блюда на вынос <п><сильный>1. Результат «20+ заголовков» из Части 1 — это результат CRM/SaaS, а не универсальный. Применение его к здравоохранению, образованию или финансам может активно снижать показатели цитируемости в этих вертикалях.
<п><сильный>2. Принцип, который действует повсюду: придерживайтесь структуры или не используйте ее. Золотая середина обходится вам в каждой вертикали. Полностью структурированная страница с правильной глубиной заголовка превосходит полуструктурированную страницу по каждой вертикали.
<п><сильный>3. Используйте оптимальный диапазон курса для вашей вертикали. Крипто: 5-9. Финансы и образование: 10-19. CRM/SaaS: 20+ (с H3). Здравоохранение: 0 или максимум 5-9. Длинные справочные страницы CRM с более чем 50 разделами — это тот случай, когда максимальная глубина заголовка окупается.
<х2>4. Пользовательский контент не доминирует
<п>«Эффект Reddit» изменил органический поиск в период с 2024 по 2025 год. Я хотел понять, цитирует ли ChatGPT пользовательский контент (Reddit, форумы, обзоры) с значимыми показателями или же доминирует корпоративный/редакционный контент.
Общее отраслевое предположение – что ИИ также отдает предпочтение голосам сообщества – это не то, что мы нашли в данных.
<ч3>Подход <ол>
Результаты: На корпоративный контент приходится 94,7% всех цитирований. Пользовательский контент почти невидим.
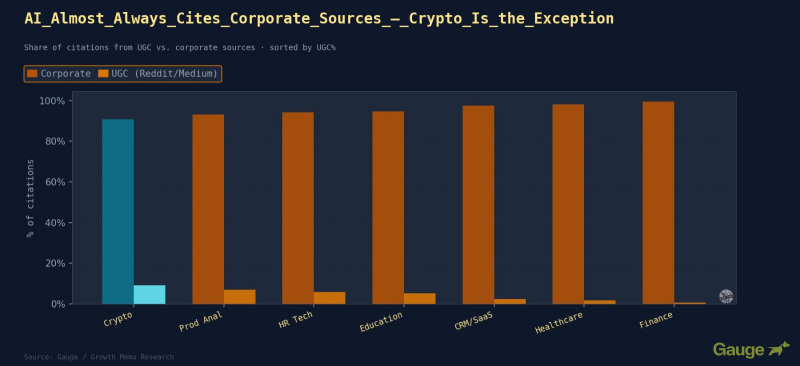
Изображение предоставлено: Кевин Индиг
Что показали тенденции в отрасли
<ул>
В
<ли><сильный>Криптоимеет самый высокий уровень проникновения пользовательского контента в наборе данных — 9,2%. Контент, созданный сообществом (технические темы Reddit, учебные пособия Medium, сообщения на форумах разработчиков), отвечает на значительную часть проанализированных запросов. В быстро меняющейся технической нише, где официальная документация постоянно отстает, посты сообщества заполняют этот пробел.
<ч3>Лучшие блюда на вынос <п><сильный>1. «Эффект Reddit» в SEO не транслируется пропорционально цитированию AI. В большинстве вертикалей reddit.com захватывает 2-5% от общего числа цитирований. Этот вывод согласуется с другими отраслевыми исследованиями, включая отчет Profound.
<п><сильный>2. Для финансов и здравоохранения: пользовательский контент имеет почти нулевую ценность цитирования AI.Инвестируйте в структурированный, авторитетный корпоративный контент с четкими источниками. Участие сообщества может иметь значение и по другим причинам, но оно не вносит существенного вклада в долю цитирования ИИ в этих вертикалях.
<п><сильный>3. Для криптографии, продуктовой аналитики и HR-технологий: присутствие в сообществе имеет измеримую ценность цитирования. Подробные темы сравнения Reddit, технические посты на Medium и структурированные ответы на форумах разработчиков могут расширить охват корпоративного контента.
<х2>Что это означает для разработки стратегии повышения видимости LLM
Во всех трех частях этого исследования неизменно обнаруживается, что цитирование ИИ не является в первую очередь проблемой качества письма.
Часть 2 показала, что это проблема архитектуры контента: тонкие одноцелевые страницы структурно заблокированы независимо от того, насколько хорошо они написаны. Этот фрагмент показывает, что та же логика применяется и внутри самого контента.
Совокупная таблица сигналов написания является наиболее важной диаграммой в этом анализе. Не потому, что он показывает вам, что делать, а потому, что он показывает, какая часть того, что говорит вам индустрия AI SEO/GEO/AEO, не выдерживает перекрестной проверки. Количество слов, плотность списка, количество именованных объектов … все одинаково или отрицательно в совокупности. Сигналы, которые работают, специфичны для конкретной отрасли и меньше, чем предполагает консенсус в нашей отрасли.
Мета-урок этого анализа заключается в том, что результаты зависят от вертикали (и, возможно, темы), что ничем не отличается от SEO.
<стр>Эта часть завершает «Науку искусственного интеллекта» – на данный момент. Потому что экосистема ИИ постоянно меняется.
<ч3>Методология
Мы проанализировали около 98 000 строк цитирования ChatGPT, взятых примерно из 1,2 миллиона ответов ChatGPT от Gauge.
Поскольку ИИ ведет себя по-разному в зависимости от темы, мы изолировали данные по семи различным, проверенным вертикалям, чтобы гарантировать, что результаты не будут искажены какой-либо одной конкретной отраслью.
Проанализированные вертикали:
<ул>
<ли>Крипто


