
Я проанализировал 1,2 миллиона результатов поиска, чтобы выяснить, как именно читает ИИ. Вердикт? Это занятой редактор, а не терпеливый студент.
Повышайте свои навыки с помощью еженедельной экспертной информации Growth Memo. Подпишитесь бесплатно!
<стр>На этой неделе я делюсь результатами анализа 1,2 миллиона ответов ChatGPT, чтобы ответить на вопрос, как повысить ваши шансы на цитирование.
Изображение предоставлено: Кевин Индиг <п>На протяжении 20 лет оптимизаторы пишут ”полные руководства” предназначен для того, чтобы держать людей на странице. Мы пишем длинные вступления. Мы протаскиваем идеи на протяжении всего проекта и до заключения. Мы создаем напряжение до финального призыва к действию.
Данные показывают, что этот стиль письма не идеален для видимости ИИ.
Проанализировав 1,2 миллиона проверенных цитат ChatGPT, я обнаружил закономерность, настолько последовательную, что ее P-значение равно 0,0: “лыжный пандус” ChatGPT уделяет непропорционально большое внимание верхним 30% вашего контента. Кроме того, я обнаружил пять четких характеристик контента, который цитируется. Чтобы победить в эпоху искусственного интеллекта, вам нужно начать писать как журналист.
<сильный>1. Какие разделы текста с наибольшей вероятностью будут цитироваться ChatGPT?
Изображение предоставлено: Кевин Индиг
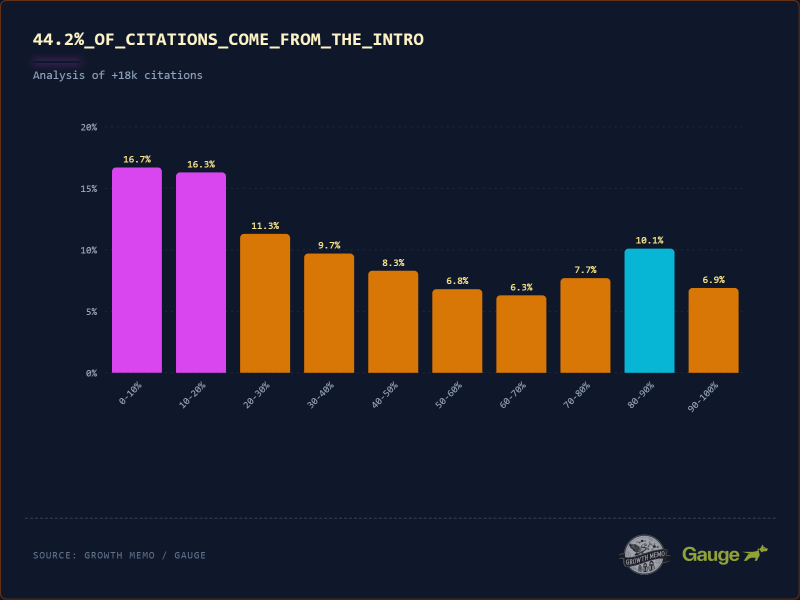
Не так уж много известно о том, какие части текста цитируют LLM. Мы проанализировали 18 012 цитат и обнаружили «лыжный спуск». распределение.
<ол> <ли><сильный>44,2% всех цитат приходится на первые 30% текста (вступление). ИИ читает как журналист. Он захватывает вопрос «Кто, Что, Где?» сверху. Если ваша ключевая идея содержится во вступлении, шансы, что ее процитируют, высоки.
<стр>Возможные объяснения структуры лыжного трапа – это тренировка и эффективность: <ул>
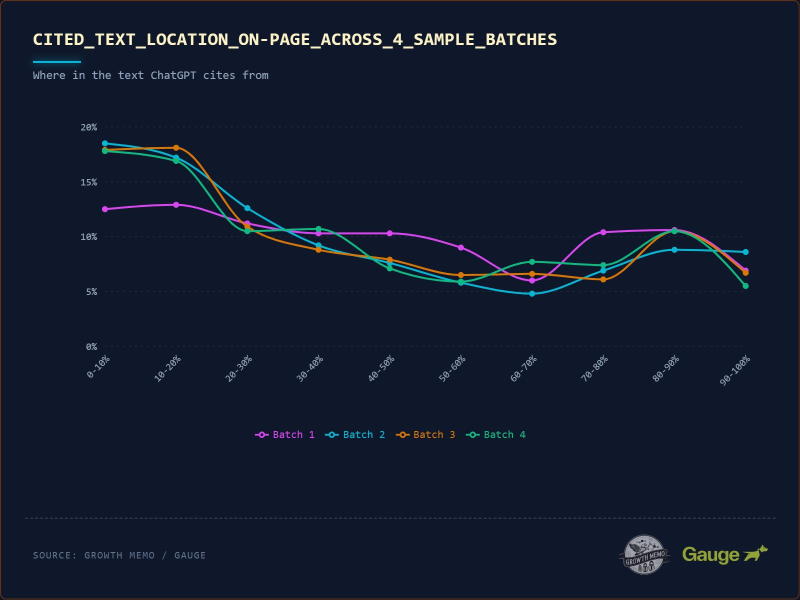
Изображение предоставлено: Кевин Индиг <п>18 000 из 1,2 миллиона цитат дают нам всю необходимую информацию. P-значение этого анализа равно 0,0, что означает, что оно статистически неоспоримо. Я разделил данные на пакеты (рандомизированное разделение для проверки), чтобы продемонстрировать стабильность результатов.
<ул>
<п>Хотя эти пакеты подтверждают стабильность на макроуровне того, где ChatGPT просматривает документ, они поднимают новый вопрос о его детальном поведении: сохраняется ли это смещение по верхним частям даже в пределах одного блока текста, или фокус ИИ меняется, когда он читает более глубоко? Установив, что данные статистически неоспоримы в масштабе, я хотел “увеличить” до уровня абзаца.
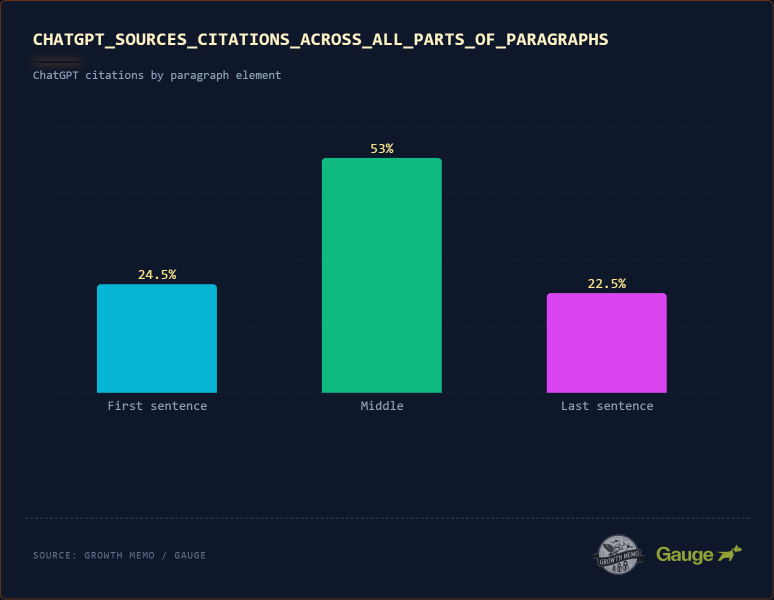
Изображение предоставлено: Кевин Индиг <п>Глубокий анализ 1000 фрагментов контента с большим количеством цитирований показывает, что 53% цитирований происходят из середины абзаца. Только 24,5% исходят из первого и 22,5% из последнего предложения абзаца. ChatGPT не является “ленивым” и читает только первое предложение каждого абзаца. Читается глубоко.
Вывод: Не обязательно вставлять ответ в первое предложение каждого абзаца. ChatGPT ищет предложение с самым высоким «приростом информации» (наиболее полное использование соответствующих объектов и дополнительной, обширной информации), независимо от того, является ли это предложение первым, вторым или пятым в абзаце. В сочетании с шаблоном «лыжный пандус» мы можем заключить, что самые высокие шансы на цитирование у абзацев в первых 20% страницы.
<сильный>2. Что делает ChatGPT более вероятным цитированием фрагментов?
Мы знаем где в контенте, который ChatGPT любит цитировать, но какие характеристики влияют на вероятность цитирования?
Анализ показывает пять выигрышных характеристик:
<ол>
<ли>Сбалансированное настроение.
<х3>1. Окончательный против. Неясный язык
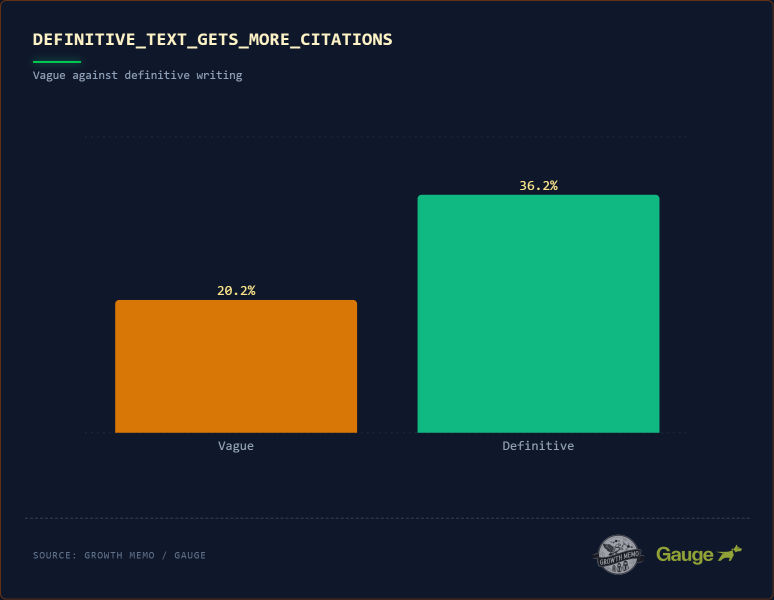
Изображение предоставлено: Кевин Индиг
Победители цитирования почти в 2 раза чаще (36,2% против 20,2%) содержат окончательные формулировки ( “определяется как ” “относится к”). Языковая цитата не обязательно должна быть дословным определением, но отношения между понятиями должны быть ясными.
<стр>Возможные объяснения влияния прямого, декларативного письма: <ул>
Вывод: Начинайте свои статьи с прямого заявления.
<ул>
<х3>2. Разговорное письмо
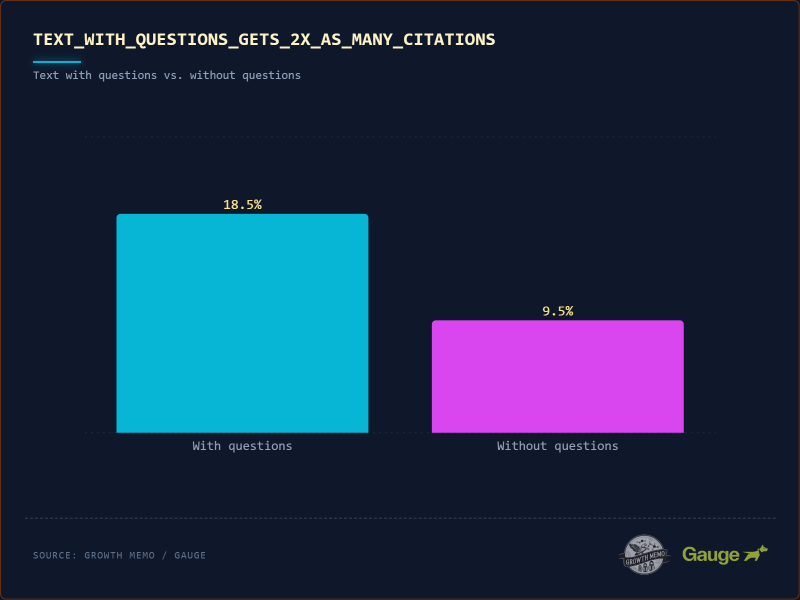
Изображение предоставлено: Кевин Индиг
Текст, который цитируется, в 2 раза чаще (18% против 8,9%) содержит вопросительный знак. Когда мы говорим о разговорном письме, мы имеем в виду взаимодействие вопросов и ответов.
Начните с вопроса пользователя как с вопроса, а затем немедленно ответьте на него. Например:
<ул>
<п>78,4% цитат с вопросами приходится на заголовки. ИИ сразу воспринимает ваш тег H2 как пользователя, а абзац, следующий за ним, как сгенерированный ответ.
Пример структуры проигрыша:
<ул>
Пример структуры победителя (78%):
<ул>
<ли><p>SEO началась в…</p> (Прямой ответ)
Причина, по которой конкретный пример выигрывает, заключается в том, что я называю “entity echoing”: заголовок спрашивает о SEO, и самое первое слово ответа – SEO.
<х3>3. Богатство сущностей
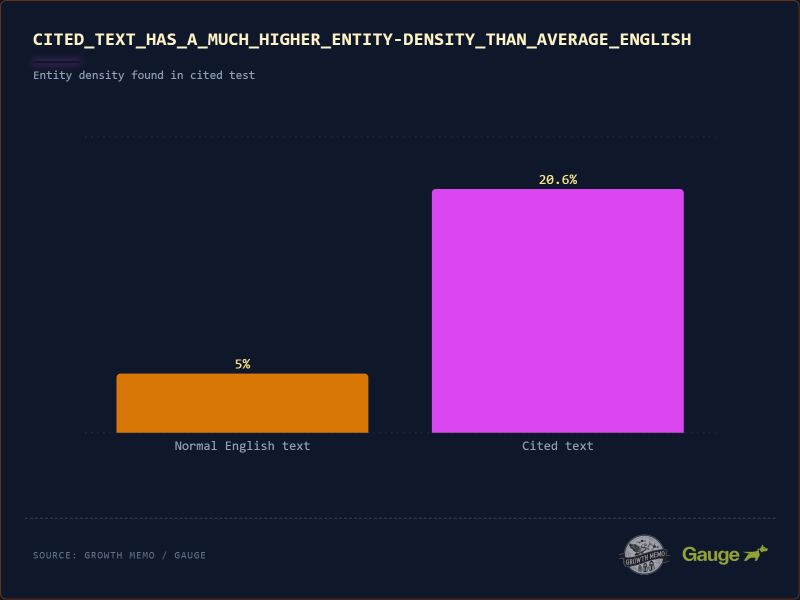
Изображение предоставлено: Кевин Индиг
Обычный английский текст имеет “плотность объектов” (то есть содержит имена собственные, такие как бренды, инструменты, люди) ~5-8%. Часто цитируемый текст имеет плотность объектов 20,6%!
<ул>
Пример:
<ул>
<п>LLM являются вероятностными. Общий совет («выберите хороший инструмент») рискован и расплывчат, но конкретный совет («выберите Salesforce») обоснован и поддается проверке. Модель отдает приоритет предложениям, содержащим “якоря” (сущностей), потому что они снижают запутанность (путаницу) ответа.
Предложение с тремя объектами содержит больше “битов” информации, чем предложение с 0 сущностями. Так что не бойтесь упоминаний (да, даже ваших конкурентов). <х3>4. Сбалансированное настроение
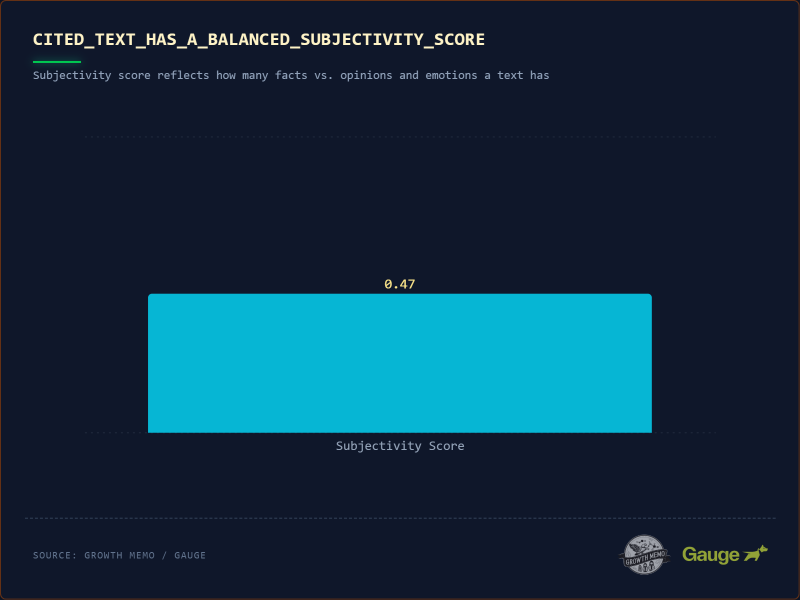
Изображение предоставлено: Кевин Индиг
В моем анализе цитируемый текст имеет сбалансированную оценку субъективности 0,47. Оценка субъективности — это стандартный показатель обработки естественного языка (НЛП), который измеряет количество личного мнения, эмоций или суждений в фрагменте текста.
<п>Оценка ведется по шкале от 0,0 до 1,0:
. <ул>
ИИ не хочет сухого текста из Википедии (0.1) и не хочет безумных мнений (0.9). Ему нужен «голос аналитика». Он предпочитает предложения, которые объясняют как применимо тот или иной факт, а не просто констатирует один только показатель.
“победа” тон выглядит следующим образом (оценка ~0,5): “Хотя iPhone 15 оснащен стандартным чипом A16 (факт), его производительность при съемке при слабом освещении делает его лучшим выбором для создателей контента (анализ/мнение).“
<х3>5. Написание делового уровня
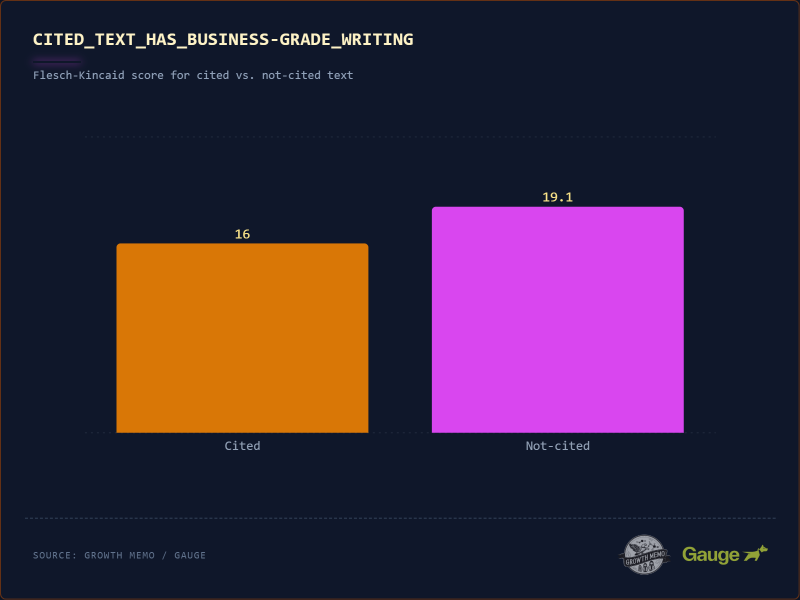
Изображение предоставлено: Кевин Индиг
Сочинения делового уровня (вспомним The Economist или Harvard Business Review) получают больше цитирований. “Победители” имеют оценку Флеша-Кинкейда 16 (уровень колледжа) по сравнению с «неудачниками»; с 19,1 (академический/докторский уровень).
<п>Даже в сложных темах сложность может навредить. Оценка 19 баллов означает, что предложения длинные, запутанные и наполнены многосложным жаргоном. ИИ предпочитает простые структуры субъект-глагол-объект с предложениями от коротких до умеренно длинных, поскольку из них легче извлекать факты.
<сильный>Вывод
“лыжная рампа” Шаблон количественно определяет несоответствие между написанием повествования и поиском информации. Алгоритм интерпретирует медленное раскрытие как недостаток уверенности. Он отдает приоритет непосредственной классификации сущностей и фактов.
<стр>Контент с высокой видимостью больше похож на структурированный брифинг, чем на рассказ. <п>Это вводит «налог на ясность»; о писателе. Победители в этом наборе данных полагаются на словарный запас бизнес-класса и высокую плотность объектов, опровергая теорию о том, что ИИ вознаграждает за «тупость»; контент (с исключениями).
Мы не только пишем роботов … еще. Но разрыв между человеческими предпочтениями и машинными ограничениями сокращается. В деловых текстах люди ищут идеи. Делая вывод заранее, мы удовлетворяем архитектуру алгоритма и нехватку времени у читателя-человека.
<сильный>Методология
Чтобы точно понять где и почему AI цитирует контент, мы проанализировали код.
Все данные в этом исследовании взяты из Gauge.
<ул> <ли>Gauge предоставил около 3 миллионов ответов AI от ChatGPT, а также 30 миллионов цитат. Веб-содержимое каждого URL-адреса цитирования было очищено во время ответа, чтобы обеспечить прямую корреляцию между истинным веб-содержимым и самим ответом. И необработанный HTML, и открытый текст были очищены.
<сильный>1. Набор данных
Мы начали с вселенной из 1,2 миллиона результатов поиска и ответов, сгенерированных искусственным интеллектом. Из этого мы выделили 18 012 проверенных цитат для позиционного анализа и 11 022 цитат для «лингвистической ДНК». анализ.
<ул>
<сильный>2. “Комбайн” Двигатель
Чтобы точно определить, какое предложение цитировал ИИ, мы использовали семантическое встраивание (подход нейронной сети).
<ул>
<сильный>3. Метрики
Как только мы нашли точное совпадение, мы измерили две вещи:
<ул>


