
В век помоев заземление — наш спаситель. Это может значительно уменьшить галлюцинации и стоит намного дешевле, чем переобучение моделей. Но тебя это волнует?
<стр>Когда мы говорим о заземлении, мы имеем в виду проверку фактов о галлюцинациях о роботах, уничтожающих планеты, и технических братьях. <п>Если вам нужна неглупая вступительная фраза, когда модели признают, что они чего-то не знают, они обосновывают результаты, пытаясь проверить себя фактами. <п>Счастлив сейчас?
TL;DR
<ол>
Что такое ТРЯПКА?
<п>RAG (Поисковая дополненная генерация) — это форма заземления и фундаментальный шаг к повышению точности системы ответов. LLM обучаются на огромных массивах данных, и каждый набор данных имеет ограничения. Особенно когда дело касается таких вещей, как новостные запросы или изменение намерения.
Когда модели задают вопрос, она не имеет соответствующего показателя уверенности для точного ответа; он обращается к конкретным доверенным источникам, чтобы обосновать ответ. Вместо того, чтобы полагаться исключительно на результаты своих обучающих данных.
<п>Привлекая эту релевантную внешнюю информацию, поисковая система идентифицирует соответствующие похожие страницы/отрывки и включает фрагменты как часть ответа.
Это дает действительно ценный взгляд на то, почему участие в обучающих данных так важно. Вы с большей вероятностью будете выбраны в качестве надежного источника для RAG, если вы фигурируете в данных обучения по соответствующим темам.
Это одна из причин, почему устранение неоднозначности и точность в сегодняшнем развитии Интернета важнее, чем когда-либо.
Зачем нам это нужно?
Потому что LLM, как известно, склонны к галлюцинациям. Они обучены давать вам ответ. Даже если ответ неправильный. <стр>Обоснование результатов дает некоторое облегчение от потока ерунды. <п>Все модели имеют предел отсечения в своих обучающих данных. Им может быть год и больше. Таким образом, все, что произошло за последний год, было бы неопровержимым без обоснования фактов и информации в реальном времени.
Как только модель получила значительный объем обучающих данных, гораздо дешевле полагаться на конвейер RAG для получения новой информации, а не на повторное обучение модели.
Различаются ли заземление и тряпка?
<п>Да. RAG — это форма заземления.
Заземление — это широкий термин, применяемый к любому типу привязки ответов ИИ к достоверным, фактическим данным. RAG достигает заземления, извлекая соответствующие документы или отрывки из внешних источников.
Почти в каждом случае, с которым вы или я будем работать, этим источником является онлайн-поиск.
<п>Думай об этом так; <ул>
<ли>RAG либо подтверждает свои утверждения, когда порог не достигается, либо находит источник истории, которая не появляется в ее обучающих данных.
<стр>Представьте себе факт, который вы слышите в пабе. Кто-то говорит вам, что шрам на груди остался от нападения акулы. Чертова история. Небольшая проверка покажет вам, что они подавились арахисом в указанном пабе, и им пришлось сделать девятичасовую операцию, чтобы удалить часть легкого.
<стр>Правдивая история – и в это я верил, пока не поступил в университет. Это был мой отец.
Существует много противоречивой информации относительно того, какой веб-поиск используют эти модели. Однако у нас есть очень достоверная информация о том, что ChatGPT (все еще) собирает результаты поиска Google, чтобы сформировать ответы при использовании веб-поиска.
Почему никто не может решить галлюцинаторную проблему ИИ?
<п>Многие галлюцинации обретают смысл, если представить их как модель, заполняющую пробелы. Выходит из строя без проблем.
<п>Это правдоподобная ложь.
Это как Элизабет Холмс из позорной компании Theranos. Ты знаешь, что это неправильно, но не хочешь в это верить. вы здесь какой-нибудь аморальный старый медиа-магнат или какая-то инвестиционная фирма, которая сэкономила на комплексной проверке.
<блоковая цитата><п>«Даже несмотря на то, что языковые модели становятся более функциональными, одну проблему по-прежнему трудно полностью решить: галлюцинации. Под этим мы подразумеваем случаи, когда модель уверенно генерирует ответ, который не соответствует действительности.”
Это прямая цитата из OpenAI. Галлюцинаторный рот лошади.
Модели галлюцинируют по нескольким причинам. Как утверждается в последней исследовательской работе OpenAI, они галлюцинируют, потому что процессы обучения и оценки вознаграждают за ответ. Правильно или нет.

Количество ошибок “высоко.” Даже на более продвинутых моделях. (Изображение предоставлено: Гарри Кларксон-Беннетт)
Если вы думаете об этом в смысле павловской обусловленности, модель получает удовольствие , когда она отвечает. Но это не совсем ответ почему модели ошибаются. Просто модели обучены отвечать на ваши бессвязные фразы уверенно и без каких-либо обращений.
Во многом это связано с тем, как была обучена модель.
Поглотите достаточное количество структурированных или полуструктурированных данных (без правильной или неправильной маркировки), и они станут невероятно умелыми в предсказании следующего слова. Звучит как разумное существо.
Не из тех, с кем ты бы тусовался на вечеринке. Но с разумным звучанием.
Если факт упоминается в обучающих данных десятки или сотни раз, модели с гораздо меньшей вероятностью ошибутся. Модели ценят повторение. Но редко упоминаемые факты служат показателем того, сколько «нов» результаты, с которыми вы можете столкнуться при дальнейшей выборке.
<п>Факты, на которые ссылаются на это нечасто, группируются под термином «одиночный коэффициент». По ранее не проводившемуся сравнению, высокий уровень синглтонов — это верный путь к катастрофе для данных обучения LLM, но отличный вариант для девичников в Эссексе.
Согласно статье о том, почему языковые модели галлюцинируют:
“Даже если бы данные обучения были безошибочными, цели, оптимизированные во время обучения языковой модели, привели бы к возникновению ошибок.”
Даже если обучающие данные на 100% безошибочны, модель будет генерировать ошибки. Их строят люди. Люди несовершенны, и мы любим уверенность.
Несколько техник после тренировки – – например, обучение с подкреплением на основе отзывов людей или, в данном случае, формы заземления – уменьшите галлюцинации.
Как работает ТРЯПКА?
Технически можно сказать, что процесс RAG инициируется задолго до получения запроса. Но я тут немного придурковат. И я не эксперт.
Стандартные LLM получают информацию из своих баз данных. Эти данные принимаются для обучения модели в форме параметрической памяти (подробнее об этом позже). Таким образом, тот, кто обучает модель, принимает четкие решения о типе контента, который, вероятно, потребует определенной формы заземления.
RAG добавляет компонент поиска информации на уровень ИИ. Система:
➡️ <сильный>Извлекает данные
➡️ Дополняет подсказку
<сильный>➡️ Создает улучшенную реакцию.
Более подробное объяснение (если оно вам нужно) будет выглядеть примерно так:
<ол>
<ли>Если определенный порог достоверности не достигнут, вызывается RAG (или форма заземления).
Если модель использует внешнюю базу данных, такую как Google или Bing (что они все делают), нет необходимости создавать ее для использования в RAG.
Это делает вещи намного дешевле.
<п>Проблема технических руководителей в том, что они все ненавидят друг друга. Поэтому, когда в сентябре 2025 года Google отказался от параметра num=100, цитируемость ChatGPT резко упала. Они больше не могли использовать своих сторонних партнеров для сбора этой информации.
Изображение предоставлено: Гарри Кларксон-Беннетт <п>Стоит отметить, что более современные архитектуры RAG применяют гибридную модель поиска, в которой семантический поиск выполняется наряду с более простыми совпадениями типов ключевых слов. Как и обновления BERT (DaBERTa) и RankBrain, это означает, что при ответе учитывается весь документ и контекстное значение.
Гибридизация позволяет получить гораздо более совершенную модель. В этом примере по сельскому хозяйству базовая модель достигла точности 75%, точная настройка увеличила ее до 81%, а точная настройка + RAG подскочила до 86%.
Параметрический против. Непараметрическая память
Параметрическая память модели — это, по сути, шаблоны, которые она усвоила из обучающих данных, которые жадно поглощала.
На этапе предварительного обучения модели обрабатывают огромное количество данных – слова, числа, мультимодальный контент и т. д. Как только эти данные будут преобразованы в модель векторного пространства, LLM сможет идентифицировать закономерности в своей нейронной сети.
<п>Когда вы задаете ему вопрос, он вычисляет вероятность следующего возможного токена и вычисляет возможные последовательности в порядке вероятности. Настройка температуры обеспечивает уровень случайности.
Непараметрическая память хранит (или осуществляет доступ) информацию во внешней базе данных. Любой поисковый индекс очевиден. Википедия, Reddit и т. д. тоже. Любая идеально структурированная база данных. Это позволяет модели получать конкретную информацию, когда это необходимо.
методологии RAG способны объединить эти две конкурирующие и взаимодополняющие друг друга дисциплины.
<ол>
Более высокие температуры увеличивают случайность. Или «творчество». При более низких температурах наоборот.
Как ни странно, эти модели невероятно некреативны. Это плохой способ сформулировать это, но преобразование слов и документов в токены является настолько статистическим, насколько это возможно.
Почему это важно для SEO?
Если вы заботитесь о поиске с помощью ИИ и это важно для вашего бизнеса, вам необходимо иметь хорошие позиции в поисковых системах. Вы хотите, чтобы ваш путь был принят во внимание, когда применяется поиск RAG.
<с>Вы должны знать, как работает RAG и как на него влиять. <п>Если ваш бренд плохо представлен в обучающих данных модели, вы не сможете немедленно это изменить. Что ж, для будущих итераций это возможно. Но база знаний модели не обновляется «на лету».
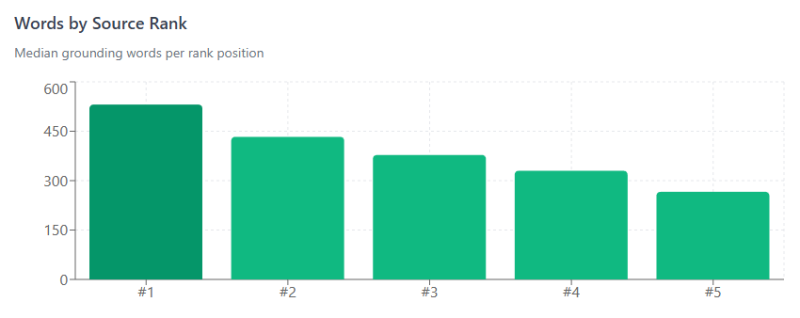
Мы знаем, насколько велики основные куски Google. Чем выше ваш рейтинг, тем больше у вас шансов (Изображение предоставлено: Гарри Кларксон-Беннетт)
Итак, вы полагаетесь на заметное место в этих внешних базах данных, чтобы быть частью ответа. Чем выше ваш рейтинг, тем больше вероятность того, что вы попадете в поисковые запросы, специфичные для RAG.
<стр>Настоятельно рекомендую посмотреть презентацию Марка Уильямса-Кука «От грязи к богатству». Это превосходно. Очень разумно и дает четкие рекомендации о том, как найти запросы, требующие RAG, и как на них можно повлиять. <п>