
<стр>Новые доказательства, полученные Министерством юстиции против Google, проливают свет на сигналы качества собственных страниц, оценку спама и то, почему данные о взаимодействии с пользователем лежат в основе современного рейтинга в поисковых системах.
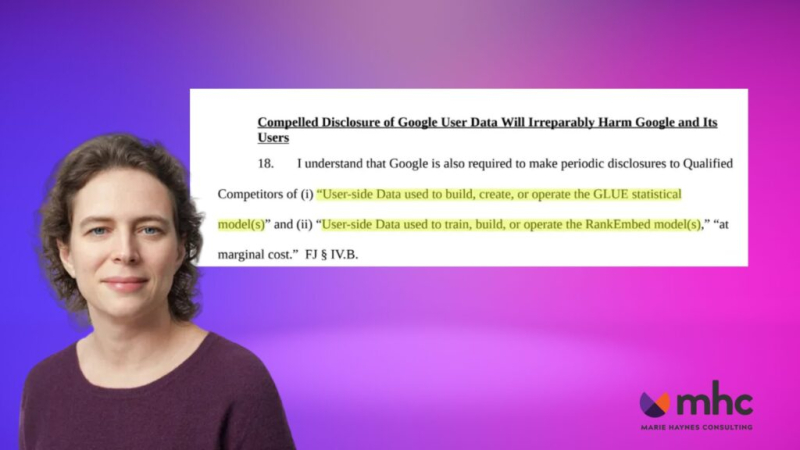
Я нашел кое-что интересное в последнем документе по делу Министерства юстиции США против Google. Google подала апелляцию на решение, согласно которому компания должна предоставлять конфиденциальную информацию конкурентам.
Изображение предоставлено Мари Хейнс <ч2>Ключевые выводы: <ул>
<ли><сильный>Пользовательские данные важны для системы Google Glue , которая хранит информацию о каждом поисковом запросе, о том, что видел пользователь, и о том, как он взаимодействовал с результатами поиска.
<стр>Хорошо, давайте перейдем к самому интересному!
Google имеет собственные сигналы качества и актуальности страниц
<п>Это действительно не сюрприз. Мне показалось интересным, что сигналы свежести лежат в основе секретов Google.

Изображение предоставлено: Мари Хейнс
И еще раз о важности собственных сигналов свежести Google:

Изображение предоставлено: Мари Хейнс
Сканируемые страницы помечаются ‘собственными аннотациями для понимания страниц’
Каждая страница в индексе Google помечена аннотациями, которые помогают понять страницу. К ним относятся сигналы для выявления спама и дубликатов страниц. Я уже писал ранее о том, что каждая страница в индексе имеет рейтинг спама.

Изображение предоставлено: Мари Хейнс
Оценки спама можно использовать для реверс-инжиниринга систем ранжирования
Google не хочет делиться информацией об этих показателях со своими конкурентами.

Изображение предоставлено: Мари Хейнс
Если информация о спаме станет известна, это может привести к увеличению количества спама и усложнить Google борьбу со спамом.

Изображение предоставлено: Мари Хейнс <х3>Google создает индекс, используя эти размеченные страницы
Страницы, на которые Google добавил аннотации для понимания страниц, организованы в зависимости от того, как часто Google ожидает доступа к контенту и насколько свежим должен быть контент.

Изображение предоставлено: Мари Хейнс
Только часть страниц попадает в индекс Google
Google утверждает, что предоставление конкурентам списка проиндексированных URL-адресов позволит им «отказаться от сканирования и анализа более широкой сети и вместо этого сосредоточить свои усилия на сканировании только той части страниц, которые Google включил в свой индекс». Создание этого индекса требует от Google много времени и денег. Они не хотят отдавать это бесплатно.

Изображение предоставлено: Мари Хейнс
Роль пользовательских данных в системах ранжирования Google
<сильный>Это самая интересная часть. Я считаю, что мы не уделяем достаточно внимания использованию Google пользовательских данных в рейтинговых системах Google.)
<х3>Пользовательские данные используются для создания моделей GLUE и RankEmbed
RankEmbed BERT еще интереснее. RankEmbed BERT — это одна из систем глубокого обучения, лежащая в основе поиска. Из свидетельства Панду Наяка мы узнали, что RankEmbed BERT используется для переоценки результатов, возвращаемых традиционными системами ранжирования. RankEmbed BERT обучается на данных о кликах и запросах реальных пользователей.
<п>Системы искусственного интеллекта, лежащие в основе поиска, постоянно учатся совершенствоваться, предоставляя поисковикам удовлетворительные результаты. Google смотрит, на что они нажимают и возвращаются ли они в результаты поиска или нет. Google также проводит живые эксперименты, которые смотрят на то, на что пользователи предпочитают нажимать и оставаться на них. Эти действия помогают обучать RankEmbed BERT. Далее он уточняется с помощью оценок оценщиков качества. Скоро я опубликую об этом больше. Изюминка, на которой я хочу остановиться: удовлетворенность пользователей — это, безусловно, самая важная вещь, ради которой мы должны оптимизироваться!
Из документа Лиз Рид, который мы анализируем сегодня, мы видим, что пользовательские данные используются для обучения, построения и эксплуатации моделей RankEmbed.

Изображение предоставлено Мари Хейнс <п>Мы снова узнаем, что пользовательские данные, которые используются для обучения этих моделей, включают запрос, местоположение, время поиска и то, как пользователь взаимодействовал с тем, что ему отображалось.

Изображение предоставлено: Мари Хейнс
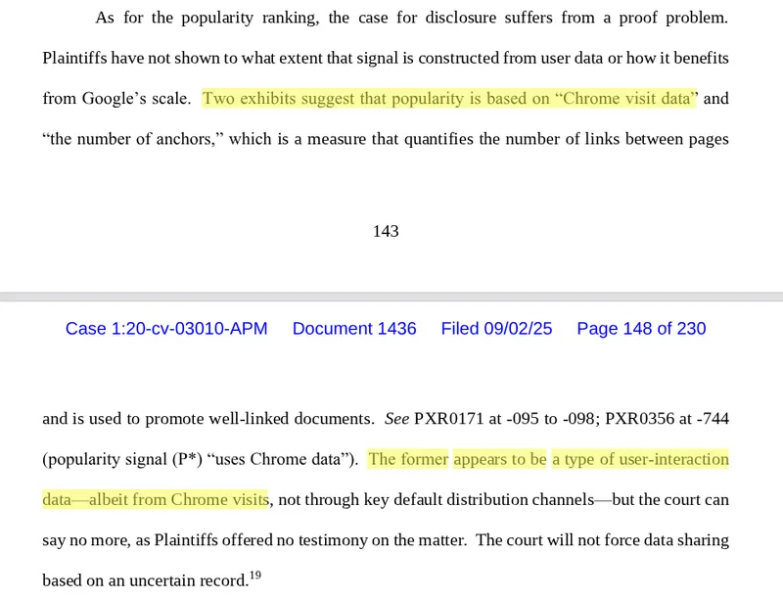
Речь идет о действиях, которые пользователи совершают в результатах поиска Google. Что я действительно хочу знать, так это какую роль играют данные Chrome. Смотрит ли Google, взаимодействуют ли люди с вашими страницами, заполняют ли ваши формы, готовят ли ваши рецепты и т. д. ? Я думаю, что да. Резюме решения по этому делу намекает на то, что данные Chrome используются в системах ранжирования, но не раскрывается много подробностей.
Изображение предоставлено: Мари Хейнс
Google утверждает, что если бы у кого-то были пользовательские данные Glue и RankEmbed, он мог бы с их помощью обучить LLM
Эти пользовательские данные являются ключом к успеху Google.

Изображение предоставлено: Мари Хейнс <стр>Стоит прочитать всю декларацию Лиз Рид.
Этот пост был первоначально опубликован на сайте Marie Haynes Consulting.


