
Файл robots.txt Джона Мюллера стал объектом любопытства из-за содержащихся в нем странных указаний и чудовищно огромного размера
<п> <изображение fetchpriority="высокий" src="https://www.searchenginejournal.com/wp-content/uploads/2024/03/google-john-mueller-robots--760x400.png" ширина = "760" высота="400" alt="Сага о причудливых роботах Джона Мюллера.txt" srcset="https://www.searchenginejournal.com/wp-content/uploads/2024/03/google-john-mueller-robots--1520x800.png 1,5x" />
Файл robots.txt личного блога Джона Мюллера из Google оказался в центре внимания, когда кто-то на Reddit заявил, что блог Мюллера подвергся атаке системы полезного контента и впоследствии деиндексирован. Правда оказалась менее драматичной, но все же немного странной.
Пост в SEO-субреддите
<п>Сага о robots.txt Джона Мюллера началась, когда пользователь Redditor опубликовал сообщение о том, что веб-сайт Джона Мюллера был деиндексирован, и сообщил, что он не соответствует алгоритму Google. Но как бы иронично это ни было, этого никогда не произойдет, потому что все, что потребовалось, это несколько секунд, чтобы загрузить файл robots.txt веб-сайта и увидеть, что происходит что-то странное.
Вот верхняя часть файла robots.txt Мюллера, в котором есть пасхальное яйцо с комментариями для тех, кто заглянет.
Первое, что не наблюдается каждый день, — это запрет на файл robots.txt. Кто использует свой robots.txt, чтобы сказать Google не сканировать его robots.txt?
<п>Теперь мы знаем. <п>
Следующая часть файла robots.txt блокирует сканирование веб-сайта и файла robots.txt.
всеми поисковыми системами.
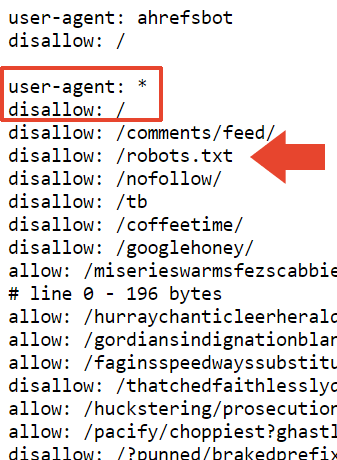
Это, вероятно, объясняет, почему сайт деиндексирован в Google. Но это не объясняет, почему Bing до сих пор индексирует его.
<п>Я поспрашивал, и Адам Хамфрис, веб-разработчик и SEO-специалист (профиль в LinkedIn), предположил, что, возможно, Bingbot не посещал сайт Мюллера, потому что он в основном неактивен.< /п>
Адам написал мне его мысли:
“Пользовательский агент: *
Запретить: /topsy/
Запретить: /crets/
Запретить: /hidden/file.htmlВ этих примерах папки и файл в этой папке не будут найдены.
<п>Он говорит запретить файл robots, который Bing игнорирует, но Google слушает.
Bing будет игнорировать неправильно реализованных роботов, потому что многие не знают, как это делать. “
Адам также предположил, что, возможно, Bing вообще проигнорировал файл robots.txt.
Он объяснил мне это так:
“Да, или он решает игнорировать директиву не читать файл инструкций.
Неправильно реализованные инструкции для роботов в Bing, скорее всего, игнорируются. Для них это самый логичный ответ. Это файл инструкций.”
Последний раз файл robots.txt обновлялся где-то между июлем и ноябрем 2023 года, поэтому, возможно, Bingbot не видел последнюю версию robots.txt. Это имеет смысл, поскольку система сканирования веб-страниц IndexNow от Microsoft отдает приоритет эффективному сканированию.
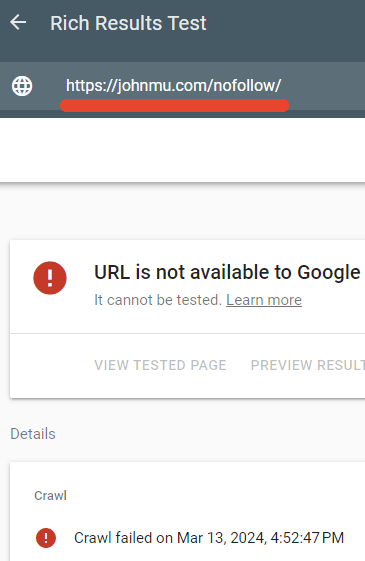
Одним из каталогов, заблокированных файлом robots.txt Мюллера, является /nofollow/(странное имя для папки).
На этой странице практически ничего нет, кроме навигации по сайту и слова Redirector.
Я проверил, действительно ли файл robots.txt блокирует эту страницу, и так оно и было.
Тестировщику расширенных результатов Google не удалось просканировать веб-страницу /nofollow/.
<п>
Объяснение Джона Мюллера
Мюллера, похоже, позабавило, что его robots.txt уделяется столько внимания, и он опубликовал на LinkedIn объяснение происходящего.
<п><сильный>Он написал:
“Но что с файлом? И почему ваш сайт деиндексирован?
Кто-то предположил, что это может быть из-за ссылок на Google+. Возможно. И вернемся к файлу robots.txt… все в порядке – Я имею в виду, это то, как я хочу, и сканеры могут с этим справиться. Или они смогут это сделать, если будут следовать RFC9309.”
Далее он сказал, что nofollow в файле robots.txt предназначен просто для того, чтобы предотвратить его индексацию как HTML-файл.
<сильный>Он объяснил:
“”disallow: /robots.txt” – это заставляет роботов кружиться? Это деиндексирует ваш сайт? Нет.
<п>В моем файле robots.txt просто много всего, и он будет чище, если его не проиндексировать вместе со своим содержимым. Это просто блокирует сканирование файла robots.txt с целью индексации.
Я также мог бы использовать HTTP-заголовок x-robots-tag с noindex, но в этом случае он будет присутствовать и в файле robots.txt.”
Мюллер также сказал то же самое о размере файла:
<блоковая цитата><п>“Размер взят из тестов различных инструментов тестирования robots.txt, которые моя команда & Я работал дальше. В RFC сказано, что сканер должен парсить не менее 500 кибибайт (бонус лайк первому, кто объяснит, что это за закуска). Надо где-то останавливаться, можно делать страницы бесконечно длинные (и у меня, и у многих так, некоторые даже специально). На практике происходит следующее: система, проверяющая файл robots.txt (парсер), где-то делает разрез.”
Он также сказал, что добавил запрет поверх этого раздела в надежде, что он будет воспринят как «полный запрет»; но я не уверен, о каком запрете он говорит. В его файле robots.txt ровно 22 433 запрета.
Он написал:
“Я добавил “disallow: /” в верхней части этого раздела, так что, надеюсь, это будет воспринято как полный запрет. Вполне возможно, что парсер обрежет в неудобном месте, например, строку с “allow: /cheeseisbest” и он останавливается прямо на “/”, что ставит синтаксический анализатор в тупик (и, мелочь! правило разрешения переопределяет, если у вас есть оба “allow: /” и “disallow: /”). Хотя это кажется очень маловероятным.”
И вот оно. Странные роботы Джона Мюллера.txt.
Robots.txt можно просмотреть здесь:
<п>


