Поиск смещается от ранжированных списков к точным ответам. В этом руководстве рассматриваются факторы поиска, цитирования и доверия, которые определяют видимость LLM в 2026 году.
<п><эм>Повышайте свои навыки с помощью еженедельной экспертной информации Growth Memo. Подпишитесь бесплатно!
<стр>Каждый год, после зимних каникул, я провожу несколько дней, собирая контекст прошлого года и напоминая себе о том, где находятся мои клиенты. Я хочу использовать возможность поделиться своим пониманием того, где мы находимся с AI Search, чтобы вы могли быстро вернуться в курс дела.
Напоминаем, что в конце 2025 года атмосфера вокруг ChatGPT немного ухудшилась:
<ул>
Google выпустил улучшенную версию Gemini 3, в результате чего Сэм Альтман объявил о Code Red (по иронии судьбы, через три года после того, как Google сделал то же самое при запуске ChatGPT 3.5).
OpenAI осуществила серию циклических инвестиций, которые вызвали недоумение и вопросы о том, как их финансировать.
<ли>ChatGPT, который отправляет большую часть всех LLM, достигает не более 4% текущего органического реферального трафика (в основном Google).
Самое главное, мы до сих пор не знаем ценность упоминания в ответе ИИ. Однако тема искусственного интеллекта и LLM не может быть более важной, потому что пользовательский опыт Google превращается из списка результатов в окончательный ответ.
Большое “спасибо” Дэну Петровичу и Андреа Вольпини за рецензирование моего черновика и добавление значимых концепций.
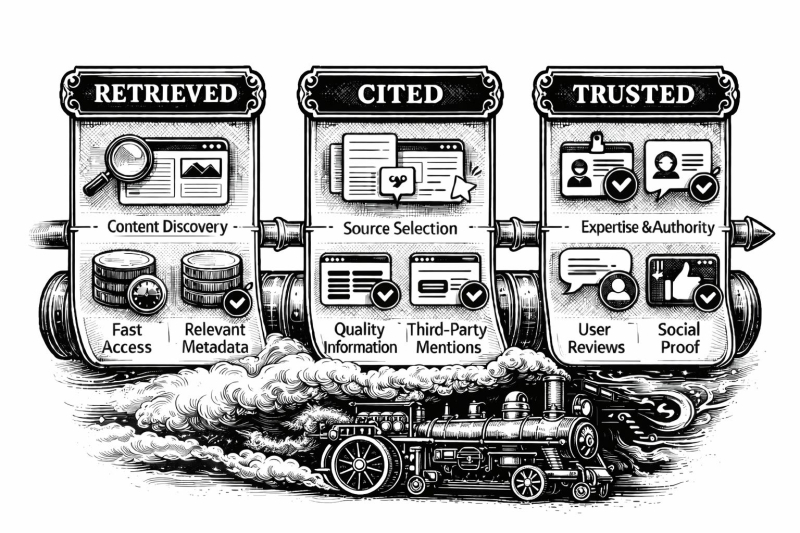
Изображение предоставлено: Кевин Индиг
<сильный>Добавлено → Цитируется → Доверенный
Оптимизация видимости поиска при помощи ИИ осуществляется по конвейеру, аналогичному классическому алгоритму “сканирование, индексирование, ранжирование” для поисковых систем:
<ол>
Поисковые системы решают, какие страницы входят в набор кандидатов.
Модель выбирает, какие источники цитировать.
Пользователи решают, какой цитате доверять и на основании которой действовать.
Предостережения:
<ол> <ли>Многие рекомендации сильно совпадают с общепринятыми передовыми практиками SEO. Та же тактика, новая игра.
Я не претендую на то, что у меня есть исчерпывающий список всего, что работает.
Спорные факторы, такие как схема или llms.txt, не включены.
<сильный>Рассмотрение: попадание в пул кандидатов
<п>Прежде чем какой-либо контент попадет в набор рассмотрения (обоснования) модели, он должен быть просканирован, проиндексирован и доступен для извлечения в течение миллисекунд во время поиска в реальном времени.
Факторы, которые влияют на рассмотрение:
<ул>
Скорость выбора и первичное смещение.
Время ответа сервера.
Актуальность метаданных.
Фиды товаров (в электронной торговле).
<сильный>1. Скорость выбора и первичное смещение
<ул>
Определение: Первичная предвзятость измеряет ассоциации с атрибутами бренда, которые у модели возникают перед тем, как она попадает в результаты живого поиска. Коэффициент выбора показывает, как часто модель выбирает ваш контент из пула кандидатов на поиск.
<сильный>Почему это важно:На LLM влияют данные обучения. Модели рассчитывают показатели достоверности для отношений между атрибутами бренда (например, «дешево», «долговечно», «быстро») независимо от поиска в реальном времени. Эти уже существующие ассоциации влияют на вероятность цитирования, даже когда ваш контент попадает в пул кандидатов.
Цель: Понять, какие атрибуты модели ассоциируются с вашим брендом и насколько она уверена в вашем бренде как в целом. Систематически укрепляйте эти ассоциации с помощью целевых кампаний на странице и за ее пределами.
<сильный>2. Время ответа сервера <ул>
<сильный>Определение: Время между запросом сканера и первым байтом данных ответа сервера (TTFB = время до первого байта).
Почему это важно: Когда моделям нужны веб-результаты для обоснования ответов (RAG), им необходимо извлекать контент, как сканеру поисковой системы. Несмотря на то, что поиск в основном основан на индексах, более быстрые серверы помогают с рендерингом, агентскими рабочими процессами, актуальностью и разветвлением составных запросов. Поиск LLM работает в условиях ограниченной задержки во время поиска в реальном времени. Медленные ответы не позволяют страницам попасть в пул кандидатов, поскольку они пропускают окно поиска. Постоянно медленное время отклика приводит к ограничению скорости сканирования.
<ли><сильный>Цель: Поддерживать время ответа сервера <200 мс. Сайты со временем загрузки 1 с получают в 3 раза больше запросов от Googlebot, чем сайты >3 с. Для сканеров LLM (GPTBot, Google-Extended) окна поиска еще меньше, чем при традиционном поиске.
<сильный>3. Релевантность метаданных
<ул>
Определение: Теги заголовков, метаописания и структура URL-адресов, которые LLM анализируют при оценке релевантности страницы во время оперативного поиска.
Почему это важно: Прежде чем выбирать контент для формирования ответов ИИ, LLM анализируют заголовки на предмет актуальности, описания как сводки документов, а URL-адреса как контекстные подсказки для определения релевантности страницы и надежности.
Цель: Включить целевые концепции в заголовки и описания (!), чтобы они соответствовали языку подсказок пользователю. Создавайте URL-адреса с описанием ключевых слов, возможно, даже включая текущий год, чтобы сигнализировать о свежести.
<сильный>4. Доступность фида товаров (электронная торговля) <ул>
Определение: Структурированные каталоги продуктов, отправляемые непосредственно на платформы LLM с данными о запасах, ценах и атрибутах в режиме реального времени.
Почему это важно: Прямые каналы обходят традиционные ограничения поиска и позволяют LLM отвечать на запросы о транзакционных покупках (”где я могу купить” “лучшая цена”) с точной и актуальной информацией.
<ли><сильный>Цель: Отправляйте фиды товаров, контролируемые продавцом, в торговую программу ChatGPT (chatgpt.com/merchants) в формате JSON, CSV, TSV или XML с полными атрибутами (название, цена, изображения, обзоры, наличие, характеристики). Внедрите ACP (протокол агентской коммерции) для агентских покупок.
Актуальность: выбрано для цитирования
“Кризис атрибуции в результатах поиска LLM” (Strauss et al., 2025) сообщает о низком уровне цитирования, даже когда модели получают доступ к соответствующим источникам.
<ул>
24% ответов ChatGPT (4o) генерируются без явного получения какого-либо онлайн-контента.
Gemini не дает кликабельной цитаты в 92% ответов.
Perplexity посещает около 10 релевантных страниц за один запрос, но цитирует только три-четыре.
Модели могут ссылаться только на источники, которые входят в контекстное окно. Упоминания перед обучением часто остаются без указания авторства. При оперативном поиске добавляется URL-адрес, который позволяет указать авторство.
<сильный>5. Структура контента
<ул>
Определение: Семантическая иерархия HTML, элементы форматирования (таблицы, списки, часто задаваемые вопросы) и плотность фактов, которые делают страницы машиночитаемыми.
<сильный>Почему это важно: LLM извлекают и цитируют конкретные отрывки. Четкая структура облегчает анализ и выборку страниц. Поскольку длина подсказок в среднем в 5 раз превышает длину ключевых слов, структурированный контент, отвечающий на вопросы, состоящие из нескольких частей, превосходит страницы с одним ключевым словом.
Цель: Используйте семантический HTML с четкими иерархиями H-тегов, таблицами для сравнения и списками для перечисления. Увеличьте плотность фактов и концепций, чтобы максимизировать вероятность добавления фрагмента.
<сильный>6. Охват часто задаваемых вопросов
<ул>
Определение: Разделы вопросов и ответов, которые отражают разговорные фразы, используемые пользователями в подсказках LLM.
<сильный>Почему это важно:Форматы часто задаваемых вопросов соответствуют тому, как пользователи запрашивают LLM (”Как мне…,” “В чем разница между…”). Такое структурное и лингвистическое соответствие увеличивает вероятность цитирования и упоминания по сравнению с контентом, оптимизированным по ключевым словам.
Цель: Создать библиотеки часто задаваемых вопросов на основе реальных вопросов клиентов (заявки в службу поддержки, звонки по продажам, форумы сообщества), которые отражают возникающие шаблоны подсказок. Отслеживайте актуальность часто задаваемых вопросов с помощью схемы LastReviewed или DateModified.
<сильный>7. Свежесть контента <ул>
Определение: Недавность обновлений контента, измеряемая по “последнему обновлению” временные метки и фактические изменения контента.
<сильный>Почему это важно: LLM анализируют последние обновленные метаданные, чтобы оценить актуальность источника и определить приоритет недавней информации как более точной и актуальной.
Цель: Обновить контент за последние три месяца для достижения максимальной производительности. Более 70% страниц, цитируемых ChatGPT, были обновлены в течение 12 месяцев, но контент, обновленный за последние три месяца, работает лучше всего во всех отношениях.
<сильный>8. Сторонние упоминания (”Вебутация”)
<ул>
Определение: Упоминания бренда, обзоры и цитирования на внешних доменах (издателях, сайтах с обзорами, новостных агентствах), а не на собственных ресурсах.
<сильный>Почему это важно: LLM придают большее значение внешней проверке, чем саморекламе, чем ближе намерение пользователя к решению о покупке. Сторонний контент обеспечивает независимую проверку утверждений и устанавливает релевантность категории посредством совместного упоминания с признанными авторитетами. Они увеличивают целостность внутри больших контекстных графов.
Цель: 85 % упоминаний бренда в поиске с использованием ИИ для подсказок о высоком покупательском намерении поступает из сторонних источников. Зарабатывайте контекстные обратные ссылки с авторитетных доменов и ведите полные профили на платформах обзора категорий.
<ч4><сильный>9. Позиция в органическом поиске
<ул>
Определение: Рейтинг страниц в традиционных страницах результатов поисковых систем (SERP) по релевантным запросам.
Почему это важно: Многие LLM используют поисковые системы в качестве источников поиска. Более высокий органический рейтинг увеличивает вероятность попадания в пул кандидатов LLM и получения цитирований.
<ли><сильный>Цель: Входите в десятку лучших в Google по разветвленным вариациям запросов по вашим основным темам, а не только по ключевым словам. Поскольку подсказки LLM носят диалоговый характер и разнообразны, рейтинг страниц для многих вариантов с длинным хвостом и вопросов, основанных на вопросах, имеет более высокую вероятность цитирования. Страницы из топ-10 демонстрируют сильную корреляцию (~0,65) с упоминаниями LLM, и 76% цитирований AI Review происходят с этих позиций. Предостережение: корреляция зависит от LLM. Например, перекрытие высокое для обзоров AI, но низкое для ChatGPT.
Выбор пользователя: завоевание доверия и действие
Доверие имеет решающее значение, поскольку мы имеем дело с одним ответом при поиске ИИ, а не со списком результатов поиска. Оптимизация доверия аналогична оптимизации рейтинга кликов в классическом поиске, только она занимает больше времени и ее труднее измерить.
<сильный>10. Продемонстрированный опыт <ул>
Определение: Видимые учетные данные, сертификаты, подписи и поддающиеся проверке доказательства, подтверждающие авторитет автора и бренда.
Почему это важно: Поиск с помощью ИИ выдает отдельные ответы, а не ранжированные списки. Пользователям, которые переходят по ссылке, требуются более сильные сигналы доверия, прежде чем предпринимать какие-либо действия, поскольку они подтверждают окончательное утверждение.
Цель: Показать на видном месте учетные данные автора, отраслевые сертификаты и проверяемые доказательства (логотипы клиентов, показатели тематического исследования, результаты сторонних испытаний, награды). Подкрепите маркетинговые заявления доказательствами.
<сильный>11. Присутствие пользовательского контента <ул>
<сильный>Определение: Представление бренда на платформах сообщества (Reddit, YouTube, форумы), где пользователи делятся опытом и мнениями.
Почему это важно: Пользователи проверяют синтетические ответы ИИ на основе человеческого опыта. Когда появляются Обзоры ИИ , клики на Reddit и YouTube вырастают с 18% до 30%, потому что пользователи ищут социальное доказательство.
Цель: Создать положительное присутствие в соответствующих категориях субреддитах, на YouTube и на форумах. YouTube и Reddit стабильно входят в тройку самых цитируемых доменов среди LLM.
<сильный>От выбора к убеждению
Поиск движется от изобилия к синтезу. На протяжении двух десятилетий рейтинговый список Google давал пользователям выбор. Поиск с помощью ИИ дает единый ответ, который объединяет несколько источников в один окончательный ответ.
Механика отличается от SEO начала 2000-х:
<ул>
Окна поиска заменяют бюджеты сканирования.
Коэффициент отбора заменяет PageRank.
Сторонняя проверка заменяет текст привязки.
Стратегический императив тот же: обеспечить видимость в интерфейсе, в котором пользователи выполняют поиск. Традиционное SEO остается основополагающим, но видимость ИИ требует разных стратегий контента:
<ул>
Охват диалоговых запросов важнее, чем рейтинг по ключевым словам.
Внешняя проверка важнее, чем собственный контент.
Структура важнее плотности ключевых слов.
Бренды, которые создают систематические программы оптимизации, теперь будут получать дополнительные преимущества по мере масштабирования трафика LLM. Переход от ранжированных списков к окончательным ответам необратим.



