
В ответе Джона Мюллера из Google на фантомные ошибки noindex в Search Console подтверждаются блоки индексирования, видимые Google.
Джон Мюллер из Google недавно ответил на вопрос о фантомных ошибках noindex, обнаруженных в консоли поиска Google. Мюллер утверждал, что эти сообщения могут быть правдой.
Noindex в консоли поиска Google
<п>Директива noindex robots — одна из немногих команд, которым должен подчиняться Google, один из немногих способов, с помощью которых владелец сайта может осуществлять контроль над Googlebot, индексатором Google.
И тем не менее, консоль поиска нередко сообщает о невозможности проиндексировать страницу из-за директивы noindex, которая, по-видимому, не имеет директивы noindex, по крайней мере, такой, которая не видна в HTML-коде.
Когда консоль поиска Google (GSC) сообщает, что “Отправленный URL отмечен ‘noindex’,” он сообщает о, казалось бы, противоречивой ситуации:
<ул>
Это сбивающее с толку сообщение из Search Console о том, что страница не позволяет Google индексировать ее, хотя издатель или оптимизатор не могут наблюдать, что это происходит на уровне кода.
<стр>Человек, задавший вопрос, опубликованный на Bluesky:
“В течение последних 4 месяцев на веб-сайте возникала ошибка noindex (в метатеге ‘robots’), которая отказывалась исчезать из Search Console. Ни на сайте, ни в файле robots.txt нет индекса. Мы уже рассмотрели этот вопрос… Что может быть причиной этой ошибки?”
Noindex показывает только для Google
<п>Джон Мюллер из Google ответил на вопрос, рассказав, что на страницах, которые он исследовал, Google всегда имелся noindex, где происходили подобные вещи.
Мюллер ответил:
“В прошлом я видел случаи, когда на самом деле существовал noindex, но иногда он показывался только Google (что все еще может быть очень сложно отладить). Тем не менее, не стесняйтесь присылать мне в DM примеры URL-адресов.”
<п>Хотя Мюллер не уточнил, что может происходить, существуют способы устранения этой проблемы и выяснения того, что происходит.
Как устранить фантомные ошибки Noindex
Возможно, где-то есть код, из-за которого индекс noindex отображается только для Google. Например, могло случиться так, что на странице когда-то был noindex, а кеш на стороне сервера (например, плагин кеширования) или CDN (например, Cloudflare) кэшировали заголовки HTTP с того времени, что, в свою очередь, привело бы к показу старого заголовка noindex роботу Googlebot (поскольку он часто посещает сайт) при предоставлении новой версии владельцу сайта.
Проверить HTTP-заголовок легко, существует множество средств проверки HTTP-заголовков, таких как этот на KeyCDN или этот на SecurityHeaders.com.
Код ответа заголовка сервера 520 — это тот код, который отправляется Cloudflare, когда он блокирует пользовательский агент.
Снимок экрана: 520 Код ответа Cloudflare
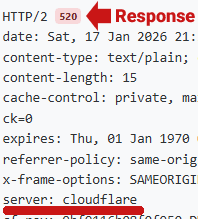
Ниже приведен скриншот кода ответа сервера 200, сгенерированного Cloudflare:
Скриншот: Код ответа сервера 200
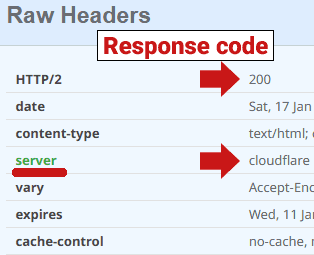
Я проверил один и тот же URL-адрес, используя два разных средства проверки заголовков: одно средство проверки заголовков вернуло код ответа сервера 520 (заблокировано), а другое средство проверки заголовков отправило код ответа 200 (ОК). Это показывает, насколько по-разному Cloudflare может реагировать на что-то вроде проверки заголовка. В идеале попробуйте проверить несколько средств проверки заголовков, чтобы увидеть, есть ли последовательный ответ 520 от Cloudflare.
<п>В ситуации, когда веб-страница показывает что-то исключительно Google, что иначе не видно тому, кто просматривает код, вам нужно заставить Google просмотреть страницу за вас, используя настоящий сканер Google и с IP-адреса Google. Чтобы сделать это, добавьте URL-адрес в тест расширенных результатов Google. Google отправит сканер с IP-адреса Google, и если на сервере (или CDN) есть что-то, что показывает noindex, это будет обнаружено. В дополнение к структурированным данным тест расширенных результатов также предоставит HTTP-ответ и снимок веб-страницы, показывающий именно то, что сервер показывает Google.
Когда вы запускаете URL-адрес через тест Google RichResults, запрос:
<ул>
Если страница заблокирована noindex, инструмент не сможет предоставить какие-либо структурированные данные. Он должен иметь статус «Страница не соответствует критериям»; или «Сканирование не удалось». Если вы это видите, нажмите на ссылку “Просмотреть подробности” или разверните раздел ошибок. Должно отображаться что-то вроде “Метатег роботов: noindex” или ‘noindex’ обнаружен в ‘robots’ метатег”.
<п>Этот подход не отправляет пользовательский агент GoogleBot, он использует строку пользовательского агента Google-InspectionTool/1.0. Это означает, что если сервер блокируется по IP-адресу, этот метод его перехватит.
Еще один аспект проверки — в ситуации, когда мошеннический тег noindex специально написан для блокировки GoogleBot, вы все равно можете подделать (имитировать) строку пользовательского агента GoogleBot с помощью собственного расширения User Agent Switcher от Google для Chrome или настроить такое приложение, как Screaming Frog, для идентификации себя с пользовательским агентом GoogleBot, и оно должно его перехватить.
Снимок экрана: переключатель пользовательского агента Chrome
Фантомные ошибки Noindex в консоли поиска
<стр>Диагностика подобных ошибок может показаться трудной, но прежде чем поднимать руки вверх, потратьте некоторое время и посмотрите, поможет ли какой-либо из описанных здесь шагов выявить скрытую причину, ответственную за эту проблему.


