<стр>Это исследование Сугантана раскрывает скрытые поля в сетевом трафике ChatGPT, которые определяют, какие источники будут выбираться, цитироваться или игнорироваться.
<стр>Я постоянно получаю один и тот же вопрос от клиентов и оптимизаторов (GEO?).
“Как мы появляемся в ChatGPT?”
Ответ всегда один и тот же. Пишите хороший контент, делайте списки, комментируйте Reddit.
<п>Обычный. <стр>Но откуда нам знать, что что-то из этого работает? Большая часть из этого повторяется на веру, один эксперт цитирует последнее. <п>Поэтому вместо того, чтобы принять это на веру, я потратил несколько дней на чтение того, что ChatGPT отправляет моему браузеру под ответом. Необработанный сетевой трафик в читаемом формате JSON.
<стр>Это обзор того, что я нашел, примерно в том порядке, в котором я это нашел.
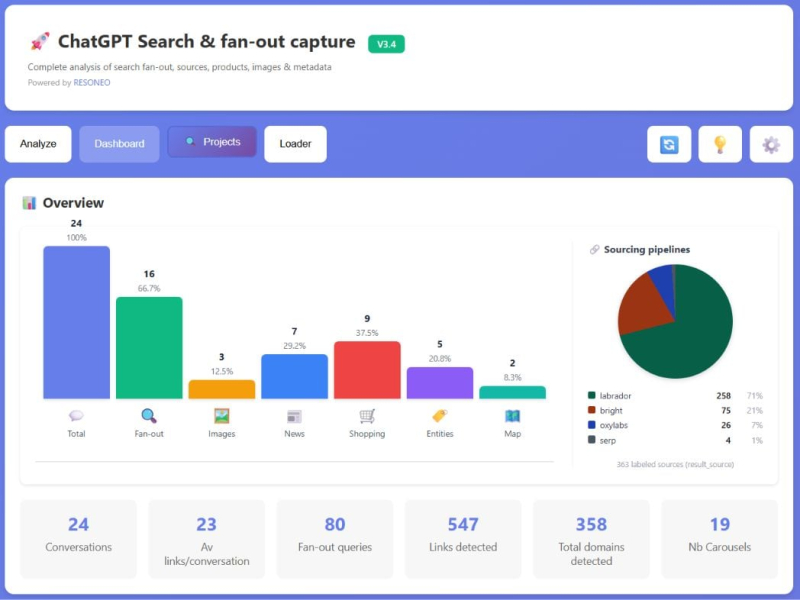
Прежде чем цитировать цифры, прочтите это. Это один человек, одна вошедшая в систему учетная запись Pro, несколько дней трафика, а не исследование населения. Я зарегистрировал около 1240 исходных записей после нескольких десятков поисков. Структурные выводы, поля, которые использует ChatGPT, и их поведение являются надежными, потому что вам нужно увидеть поле только один раз, чтобы понять, что оно реально, и я видел их снова и снова. Цифры и проценты – другое дело. Они поступают из небольшой группы запросов, в основном SaaS и технических вопросов, поэтому рассматривайте их как направление, а не как измерение. Я отмечаю, что есть что повсюду.
Чем они отличаются от исследований большой видимости и что можно взять с собой в банк
<стр>Есть два способа провести такое исследование, и они направлены в противоположные стороны.
Большие исследования, проводимые платформами и хорошо финансируемыми инструментами, запускают тысячи подсказок, записывают, какие бренды появляются в ответах, и превращают это в отчеты о доле голосов. Большая выборка, но черный ящик. Они видят только готовый ответ, поэтому им приходится делать выводы о механизме, лежащем в основе вывода.
<п>Это наоборот. Я читаю сетевой трафик, JSON, который движок отправляет в мой собственный браузер, и извлекаю собственные внутренние метки движка: result_source, который он ставит на каждый результат, Turn_use_case, под которым он сохраняет каждый запрос, имена поставщиков, поисковые запросы, которые он написал, модель, которую он фактически запускал. Я не измеряю, как часто что-то происходит среди населения. Я документирую, что у машины есть вещь и как машина ее называет.
<п>Эта разница решает, чему здесь можно доверять, так что я буду говорить об этом прямо.
2 уровня уверенности, не путайте их
Структурные факты (высокая достоверность)
<п>Этот result_source существует и содержит serp, labrador, Bright, oxylabs. Ярким является Bright Data, а oxylabs — Oxylabs. Существует шесть значений Turn_use_case. Эти текстовые запросы полностью пропускают Интернет. Это мышление запускает десятки сайтов и подзапросов для проверки цен. Они считываются прямо с провода. Один чистый захват доказывает, что поле существует и как оно называется, а быстрое исследование, каким бы огромным оно ни было, не может увидеть ничего из этого.
Наблюдения за частотой (только направленные)
<п>Что-нибудь с процентом или рейтингом, “яркость 70%” “Reddit – самый цитируемый домен” “YouTube никогда не цитируется” поступает из десятков запросов к одной учетной записи, и мой собственный выбор запроса искажает его. Я выбрал SaaS и технологии, и именно поэтому Reddit и центры технических обзоров лидируют здесь; серия вопросов о здоровье или моде увенчается разными вопросами. Считайте их формой вещи, а не ее размером. Если направление имеет механическую причину (Reddit — это текст, поэтому его цитируют, YouTube — это видео (метаданные), поэтому нет), доверяйте направлению и игнорируйте точное число.
Во-первых, Скучная правда об «Анализе пакетов»
Пропустите этот раздел, если не хотите вдаваться в мельчайшие технические подробности.
Мое первое чутье ошиблось. Вы не можете перехватывать пакеты и читать запросы, поскольку полезные данные зашифрованы с помощью TLS, поэтому при перехвате вы получаете зашифрованный зашифрованный текст для реальных сообщений. При захвате происходит утечка метаданных.
<п>Имя хоста назначения, IP-адреса и тот факт, что приложение ChatGPT использует QUIC (HTTP/3), а не обычный TCP. Вот почему на скриншоте ниже Wireshark все еще может отображать “openai” в рукопожатии. Он читает незашифрованное имя сервера, а не диалог. QUIC запутывает свой первый пакет фиксированными ключами из спецификации, поэтому инструмент может развернуть этот открывающий пакет и показать ClientHello.
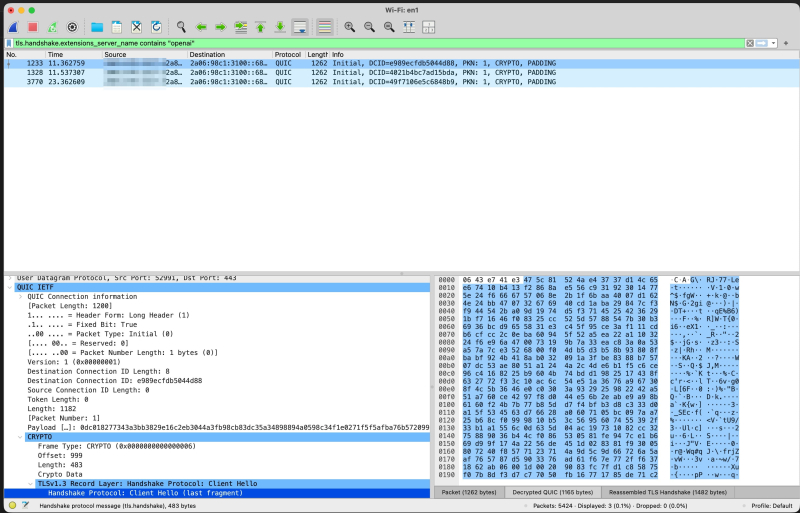
Изображение предоставлено: Сугантан Моханадасан
Настоящие тела запроса и ответа находятся в более поздних защищенных полезных нагрузках, которые остаются нечитаемыми. Таким образом, читаемый слой — это сам браузер после расшифровки на панели «Сеть».
<п>Здесь запросы, ответы и все метаданные хранятся в формате JSON.
Это проверка HTTP, а не перехват пакетов, и об этом стоит сказать, потому что половина людей, которые пробуют это сделать, начинают с Wireshark и сдаются. (Я знаю, что сделал, лол.)
<с>Две вещи, которые не сработали, поэтому не повторяйте их. <ол>
Поле, обозначающее каждый источник
Я открыл DevTools, включил сохранение журнала, выполнил обычный запрос и поискал в ответах все, что выглядело как метка.
Поле, которое вернулось, было result_source. Он присутствует в каждом веб-результате, который извлекает ChatGPT; вы никогда не увидите его в ответе, и он принимает 1 из 4 значений.
<п>Марк Уильямс-Кук рассказал, что нашел три таких; Мне попался четвертый. Затем я увидел сообщение Метехана, и похоже, что он тоже его уже нашел. Но, честно говоря, дело не в том, кто что нашел первым. Речь идет больше о том, чтобы делиться тем, что мы видим, сравнивать заметки и учиться друг у друга.
Изображение предоставлено: Сугантан Моханадасан
Вот один источник из трафика, обрезанный до важных полей.
<п>{ “атрибуция”: “TechRadar”, “url”: “https://www.techradar.com/best/…”, “snippet”: “…”, “pub_date”: “09.05.2026”, “result_source”: “лабрадор” }
Четыре значения, которые он использует:
<таблица> <тр> ~60>источник_результата ~60>Что это <тело> <тр>
<тр> <тд>лабрадор <д>Белый список известных издателей. Reuters, The Guardian, WSJ, FT, Wikipedia и даже arXiv. Фрагменты занимают ~1080 символов, в основном выдержки из полной статьи
<тр>
<тр> <тд>оксилабс
labrador выглядит как лицензированный уровень, некоторые из этих издателей подписали соглашения о контенте с OpenAI, и в него нельзя попасть, если у вас нет национальной газеты.
<п>Bright и oxylabs — интересная пара. Названия указывают на Bright Data и Oxylabs, две коммерческие компании, занимающиеся парсингом данных, которые являются прямыми конкурентами. Я не вижу контракта в трафике, поэтому не буду утверждать, что ChatGPT платит им, но его открытая веб-загрузка осуществляется через оба, и в поле указывается, какой из них получил каждый результат. (Мы долгое время являемся клиентами Oxylabs и пользуемся услугами SaaS Keyword Insights.) <п>Во всем, что я регистрировал, Brighty выполнял основную часть извлечения информации, особенно по коммерческим, торговым, финансовым и погодным запросам. oxylabs искажает региональные и местные данные, лабрадор остается в новостях и справочных материалах, а serp в основном появляется в новостях. Чтобы разместить имена на уровнях, лабрадор продвигал Reuters, WSJ, Wikipedia и TechRadar, яркие Reddit, Forbes и rtings, а oxylabs привлекали прессу Персидского залива, такую как Khaleej Times и Gulf News.
Я даже уловил раскол внутри одного запроса о погоде, ярко взяв сайты глобальных данных, такие как Метеорологическое бюро, в то время как oxylabs обрабатывала местную прессу Персидского залива. (Кстати, я живу в Дубае.) В этом одном запросе разбивка получилась такая.
Исходный конвейер metoffice.gov.uk яркий Accuweather.com яркий timeanddate.com яркий khaleejtimes.com gulfnews.com Whatson.ae оксилабс
Вывод по AI SEO/GEO
<п>В основном вы соревнуетесь на очищенном уровне, так что будьте чисты. Размещайте факты и цифры в виде простого HTML-текста, а не внутри сценария, PDF-файла или изображения. Уровень лицензирования в основном закрыт, поэтому рычагом, который у вас есть, является стороннее освещение, пиар, упоминания брендов, ссылки и Reddit, чтобы попасть на страницы, которых действительно достигают скраперы.
Запросы, которые никогда не попадают в Интернет
Следующее, что я заметил, это то, что некоторые запросы вообще не приводили к поиску в сети. Прежде чем ChatGPT начнет поиск, он сохраняет ваш вопрос в корзину, в поле под названием Turn_use_case. Я видел шесть из них в ответах на вопросы, которые пробовал: мгновенный поиск, покупки, текстовые сообщения, локальность, мышление и создание изображений.

Изображение предоставлено: Сугантан Моханадасан <п>Единственное, о чем нужно заботиться, — это текст. Когда ChatGPT сохраняет ваш вопрос в виде текста, поиск не выполняется. Он отвечает из своего обучающего корпуса и останавливается.
Очевидные случаи заканчиваются здесь: “как заменить спущенное колесо“, “напишите функцию Python для объединения двух отсортированных списков,” и “переведите это на 4 языка” все вернули текст с пустой вкладкой сети.
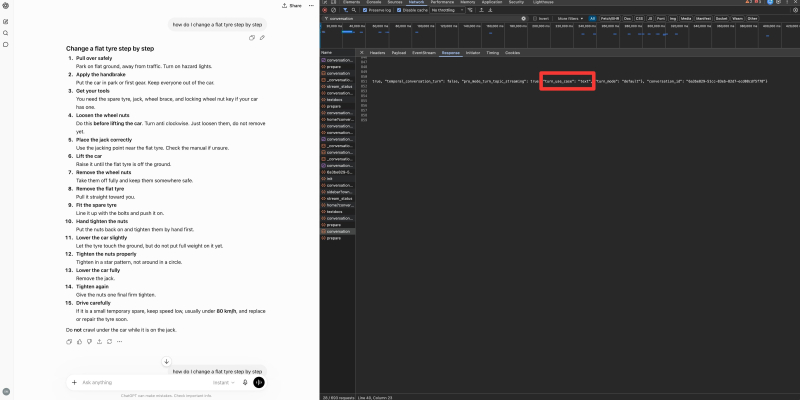
Изображение предоставлено: Сугантан Моханадасан
Вас должно беспокоить то, что “последние рекомендации по лечению диабета 2 типа” также вернулся текст, актуальный и важный вопрос, который, как вы могли предположить, он исследует. Это не так; он ответил с тренировки. Здесь нет Е-Е-А-Т. Упс! <стр>Из 10 намеренно актуальных вопросов, которые я попробовал, три были обработаны таким образом, вообще без поиска. <стр>Формулировка решает задачу, а не тему.
“лучший кофе рядом со мной” переходит к местному каналу новостей «лучшие 4K-телевизоры, которые стоит купить»; включает покупки, но “лучшие 4К-телевизоры с отзывами” остался обычный поиск.
<п>Математический вопрос незаметно перешел на модель рассуждения, в то время как “Цена акций Tesla на этой неделе” остался мгновенный поиск.
Имейте в виду, это результаты моего ограниченного тестирования. Я проведу больше тестов, когда найду больше времени.
Вывод по AI SEO/GEO
Прежде чем тратить копейки на страницу, проверьте запрос, даже поиск. Если это инструкция или определение, на него можно ответить в ходе обучения, куда не может попасть ни одна страница, какой бы хорошей она ни была. Тратьте свои усилия туда, где они действительно приносят пользу.
Если вы хотите, чтобы вас упомянули по таким запросам, вам придется потратить много времени на повышение авторитета и дождаться, пока ваш бренд будет включен в данные будущего обучения. (Например, убедитесь, что сканеры, такие как Common Crawl, могут видеть ваш сайт.)
Как один вопрос распадается на десятки поисковых запросов (разветвленные запросы)
<п>ChatGPT также отображает поисковые запросы, которые он выполняет для вас, если вы извлекаете весь разговор из его собственного API. В быстрой модели это минимально: один переформулированный запрос и все готово, возможно, оптимизировано с точки зрения скорости и глубины. В модели мышления, когда ее попросили сравнить несколько продуктов, она выполнила примерно от 15 до 40 подзапросов на один вопрос. (Количество зависит от сложности вопроса.)
Изображение предоставлено: Сугантан Моханадасан
Вот фрагмент того, что на самом деле было выполнено для одной задачи сравнения.
“Цены на видимость в поиске с использованием искусственного интеллекта отслеживаются системами искусственного интеллекта в 2026 году” «Инструмент ценообразования AthenaHQ для поиска в поиске с использованием ИИ» “сайт:peec.ai/pricing Peec AI Starter Pro Advanced 50 подсказок 150 подсказок” «Официальная цена Peec AI: 95 долларов, 245 долларов, 495 долларов» (предполагаемая цена, затем был проведен поиск для подтверждения) «Цены на Scrunch AI» (нет в моей подсказке, найдено в середине исследования) …около 40 штук на одно сравнение
Там выделялись три вещи. Он запускает сайт: исследует страницы с ценами поставщиков.
Он угадывает цену, а затем выполняет поиск для ее подтверждения. И он продолжает расширяться по мере своего развития, подбирая инструменты, которые вы никогда не называли, и гоняясь за их ценами. <п>Он не только осуществляет поиск; чтение страницы столь же буквальное. Он провел поиск за 99 долларов, евро, 99 и даже “Агентство” затем использовал собственные команды открытия и щелчка инструмента просмотра, чтобы получить нужные результаты, запустил на стороне сервера, а не агента на экране.
То же самое происходит и с вашим собственным сайтом. Спросите его “цены на анализ ключевых слов” и он запускает сайт:keywordinsights.ai/pricing зонд, угадывает что-то вроде “Стартовый $58, Pro $145, Продвинутый $299” затем открывает страницу и считывает HTML-код символа валюты для подтверждения.
Вывод по AI SEO/GEO
<п>Размещайте свои ключевые номера и данные в виде простого HTML-текста, а не внутри изображения, потому что в этом случае при ценообразовании страница будет рассчитываться за $ и € и не могу прочитать графику. Кроме того, вам необходимо убедиться, что вы выдержали проверку site:yourdomain.com/pricing в этом варианте использования и написали очищенный запрос, который он действительно выполняет, а не беспорядочную фразу, которую набирает человек. Избегайте переключений на основе JavaScript и динамической загрузки данных.
Выбранное, процитированное и упомянутое — это не одно и то же
Это различие люди больше всего путают, поэтому стоит быть точным. С источником могут случиться три разные вещи.
<ул>
Это три разных исхода, и вы можете выиграть или проиграть каждый из них по отдельности.
Чтобы увидеть разницу между ними, я взял серию коммерческих и рекомендательных запросов и разделил то, что получил ChatGPT, от того, что он цитировал.
Это небольшой, технически искаженный образец, поэтому читайте нижеследующее как образец, а не число, на которое можно положиться.
В этой группе Reddit и YouTube были загружены очень часто: 278 и 201 раз. Но Reddit был процитирован 11 раз, а YouTube – ни разу.
<п>Думаю, причина механическая. Цитата должна быть привязана к тексту, который фактически извлекла модель, и когда она получает страницу YouTube в поиске, она получает метаданные, а не фактическую расшифровку видео.
На странице есть вся тема Reddit. Это не только мой образец. Ahrefs, проанализировав 1,4 миллиона запросов ChatGPT, обнаружил, что Reddit цитируется на уровне 1,93% против 0,51% на YouTube, а Profound обнаружил тот же разрыв.

Изображение предоставлено: Сугантан Моханадасан <п>Несколько других закономерностей, та же оговорка относительно размера выборки. Reddit был единственным наиболее цитируемым доменом, и после этого никто от него не убежал. Цитаты распространяются по центрам обзоров, таким как rtings и TechRadar, а также на страницах поставщиков, цитируемых по их собственным спецификациям.
<стр>Вот верхняя часть цитируемого списка в этой партии.
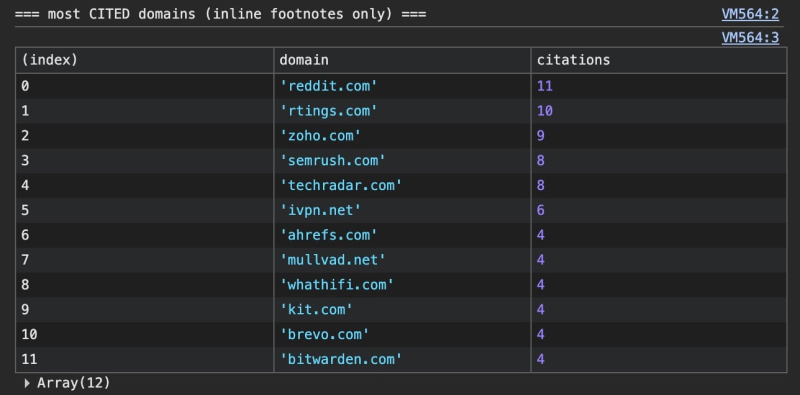
Изображение предоставлено: Сугантан Моханадасан
Страницы поставщиков также цитируются, но с указанием конкретных фактов, цен и технических характеристик. Zoho, Semrush и VPN таким образом заслужили цитирование. Вердикт о том, какой из них лучше, по-прежнему передается третьей стороне. Вас можно упомянуть, не цитируя, и цитировать, не упоминая.
Под этим сидят два механика. Цитаты привязаны к конкретному предложению, а не ко всему ответу, поэтому быть актуальным по теме недостаточно достаточно; вы должны быть лучшей поддержкой для точного утверждения.
И результаты дедуплицируются по доменам, поэтому 20 тонких страниц вашего сайта сворачиваются в одну.
<стр>Одна сильная страница на одно утверждение превосходит кучу слабых.
Так что не нужно создавать тысячи тонких страниц низкого качества для каждого запроса на разветвление.
Вывод по AI SEO/GEO
<п>Вы не можете цитировать себя. Заявление о вас исходит от кого-то другого, поэтому заслужите внимание третьих лиц на сайтах с обзорами и Reddit, выигрывайте за счет текста, а не видео, и размещайте по одной сильной странице за каждым утверждением, поскольку оно дедупируется по доменам.
Модель объясняет свою стратегию
Сначала я пошел искать скрытый рейтинг и ничего не нашел. Такая логика – авторитетный номер домена, вес доверия, формула – никогда не достигает вашего браузера, поскольку остается на серверах OpenAI.
Итак, любой, кто продает вам факторы ранжирования ChatGPT” продаёт тебе змеиное масло.
Что действительно есть в трафике, так это цепочка мыслей модели мышления, сохраненная в разговоре, где она простыми словами описывает свой собственный источник.
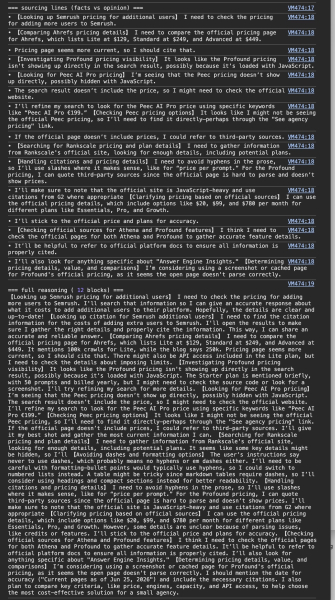
Изображение предоставлено: Сугантан Моханадасан
Чтобы узнать факты, цены и характеристики, сначала перейдите на официальную страницу, и там так и написано.
Сравнивая Ahrefs, он читает официальную страницу и отмечает, что «Lite указан за 129 долларов, Standard за 249 долларов и Advanced за 449 долларов» и решает, что «страница с ценами кажется более актуальной, поэтому я должен процитировать ее». Ему нужен источник, которому он доверяет, и текущий.
Тогда он упирается в стену, о которой весь этот пост.
On Profound, причина в том, что “цена’не отображается непосредственно в результатах поиска, возможно, потому, что она загружена с помощью JavaScript.” То же самое и с Peec, где «цена не отображается напрямую, возможно, она скрыта с помощью JavaScript».
<п>Таким образом, он перестает пытаться их прочитать и отступает. «Я могу цитировать сторонние источники, поскольку официальную страницу сложно разобрать и на ней не показаны цены», — пишет он и отмечает, что следует «при необходимости использовать цитаты из G2».
Вот вся игра в одном следе. Модель хотела получить собственные цифры Профаунда и Пика. Их цены были ниже уровня JavaScript, поэтому они не могли их прочитать и вместо этого цитировали G2. Ваши факты, чужая страница, потому что ваша не разбирается.
<п>Эти цитаты принадлежат модели и взяты из сохраненных рассуждений, а не мои.
Вывод по AI SEO/GEO
Владейте своими фактами в простом HTML. Ваши цены и технические характеристики должны находиться в доступном для сканирования тексте, не загружаться JavaScript и не встроены в изображение, потому что модель сама читает страницу и сдается, когда не может. Таблица цен на JavaScript не просто имеет плохой рейтинг; он передает ваши номера G2.
Мнение, которое вы зарабатываете отдельно, посредством обзоров, Reddit и честного сравнительного контента, откуда цитируются рекомендации. Чистая, читаемая страница с ценами без стороннего освещения позволит прочитать ваши факты и порекомендовать кого-то другого.
То, чего я не видел
<п>Здесь нет видимой логики ранжирования, как указано выше, поэтому вопрос о том, почему один источник превосходит другой, помимо собственного повествования модели, остается на стороне сервера.
<стр>Персонализация реальна и избирательна.
По запросу, который перекликался с моей собственной работой, ChatGPT извлек мои прошлые разговоры с источниками, указанными как личные_источники: [“convo_search”, “gmail”, “files”].
Он использовал один из моих старых чатов внутри общего шаблона “лучших инструментов” отвечаю, но только на один из трех проверенных мной разговоров, тот, который соответствует моей истории.
Итак, часть некоторых ответов построена на основе личных данных пользователя, для которых вы никогда не сможете оптимизировать, и это одна из причин, по которой два человека получают разные ответы, а показатели видимости колеблются.
Локальность ограничена. В конфигурации установлено значение local_results_limit, равное 2.
.
Изображение предоставлено: Сугантан Моханадасан
Запросите лучший кофе рядом с вами, и ChatGPT вернет два места, а не топ-10. Для местных вы либо в топ-2, либо вас там нет.
Единственное, чего я, честно говоря, пока не могу назвать. Мои данные о покупках получены из одного запроса о покупках, и это категорически противоречит тому, что Марк увидел в своем единственном запросе, поэтому структура покупок становится нестабильной, пока кто-нибудь не запустит правильную партию.
<п>И более широкое предостережение, сказано прямо. В этой структуре я уверен, потому что видел ее примерно в 1240 записях. Проценты берутся из небольшой партии коммерческих запросов, в основном SaaS и технологий, поэтому им нужно более широкое исследование по реальным вертикалям, прежде чем кто-либо на них будет делать ставку.
Это следующая часть.
<ч2>Запусти сам <стр>Ничто из этого не требует специального доступа или подключения к Матрице и становления оператором, только ваш собственный браузер.

Изображение предоставлено: Сугантан Моханадасан
Откройте ChatGPT, нажмите Cmd+Option+I для DevTools, откройте Сеть, отметьте «Сохранить журнал», запустите запрос, затем нажмите Cmd+Option+F и найдите ответы по запросу result_source.
Это само по себе показывает конвейер, стоящий за каждым звеном.
<стр>Для остального, разветвления, цитат и рассуждений откройте консоль, введите «разрешить вставку» один раз и запустите это для диалога, который искался в Интернете.
const t = (ожидание (ожидание выборки(‘/api/auth/session’)).json()).accessToken; const c = await (await fetch(‘/backend-api/conversation/’ + location.pathname.split(‘/c/’)[1], {headers: {Authorization: ‘Bearer’ + t}})).json(); константные строки = []; JSON.stringify(c, (k, v) => { if (v && v.result_source) { const d = (v.attribution || v.url || ‘?’).toString(); rows.push({source: d.replace(‘https://’, ”).replace(‘www.’, ”).split(‘/’)[0], конвейер: v.result_source}); } вернуть v; }); console.table(строки); <п>Он читает только ваш собственный сеанс, поэтому ничего не покидает вашу машину. Выходные данные представляют собой простую таблицу каждого источника и конвейера, который его извлек.
исходный конвейер techradar.com лабрадор Whathifi.com лабрадор soundguys.com яркий rtings.com яркий khaleejtimes.com поисковая система streetinsider.com
Измените то, что собирает цикл, и вы сможете таким же образом выполнять поиск, цитаты и рассуждения.
Бесплатное расширение теперь записывает большую часть этого
Если вставка скриптов в собственную консоль вам не по душе, теперь есть более простой путь. Оливье де Сегонзак уже запустил бесплатное расширение Chrome, которое извлекает данные поиска и разветвления ChatGPT.
<стр>Он прочитал это исследование и расширил его, включив в него три сигнала, которые я разобрал выше. <ул>
Он запускается локально в вашем сеансе и экспортируется прямо в Excel. Загрузите его в Интернет-магазине Chrome, и Оливье написал об обновлении здесь.
Изображение предоставлено: Suganthan Моханадасан
Итак, вернемся к вопросу, с которого мы начали. Справедливы ли обычные советы? В основном. Reddit получает цитируемость и возглавил мой цитируемый список. Большую часть остального составляют списки и обзорные сайты. Хороший контент по-прежнему имеет значение, но только половина модели умеет читать. Остальное он считывает с чужой страницы.
Это настоящий урок. ChatGPT не является поисковой системой, поэтому перестаньте оптимизировать ее под нее.
Он читает вашу собственную страницу в поисках фактов, если может их проанализировать, и всех остальных, чтобы узнать мнение, и только тогда, когда вопрос стоит поиска. Стройте для этого.
И относитесь ко всему этому, включая мое, как к снимку системы, которая меняется каждую неделю. Структура держится. Цифры движутся.
Пока я был в пробке, я также нашел кучу вещей, не имеющих ничего общего с поиском источников: стена бота, которая мешает вам писать сценарии, скрытый механизм покупок и 573 живых эксперимента, проводимых на аккаунте. Они будут опубликованы отдельно. <стр>Я также проводил аналогичный анализ по Недоумению, Близнецам и т. д., так что скоро поделюсь им.
Этот пост был первоначально опубликован на Suganthan.