Сжатие может использоваться поисковыми системами для обнаружения страниц низкого качества. Хотя это и не широко известно, это полезные фундаментальные знания для SEO
<п>Концепция сжимаемости как сигнала качества не широко известна, но оптимизаторам следует об этом знать. Поисковые системы могут использовать сжимаемость веб-страниц для выявления дубликатов страниц, дорвеев с похожим содержанием и страниц с повторяющимися ключевыми словами, что делает эту информацию полезной для SEO.
Хотя следующая исследовательская работа демонстрирует успешное использование встроенных функций для обнаружения спама, преднамеренное отсутствие прозрачности со стороны поисковых систем не позволяет с уверенностью сказать, применяют ли поисковые системы этот или подобные методы.
Что такое сжимаемость?
В компьютерных вычислениях сжимаемость означает, насколько файл (данные) может быть уменьшен в размере, сохраняя при этом важную информацию, обычно для увеличения объема памяти или для передачи большего количества данных через Интернет.< /п>
TL/DR сжатия
Сжатие заменяет повторяющиеся слова и фразы более короткими ссылками, значительно уменьшая размер файла. Поисковые системы обычно сжимают проиндексированные веб-страницы, чтобы максимально увеличить пространство для хранения, уменьшить пропускную способность и повысить скорость поиска, а также по другим причинам.
Это упрощенное объяснение того, как работает сжатие:
<ул>
Алгоритм сжатия сканирует текст, чтобы найти повторяющиеся слова, шаблоны и фразы
<ли><сильный>Более короткие коды занимают меньше места:
Коды и символы занимают меньше места, чем исходные слова и фразы, что приводит к меньшему размеру файла.
“код” который по сути символизирует замененные слова и фразы, использует меньше данных, чем оригиналы.
<п>Дополнительным эффектом от использования сжатия является то, что его также можно использовать для выявления дубликатов страниц, дорвеев с похожим содержанием и страниц с повторяющимися ключевыми словами.
Исследовательская статья по обнаружению спама
Эта исследовательская статья имеет большое значение, поскольку ее авторами являются выдающиеся ученые-компьютерщики, известные своими прорывами в области искусственного интеллекта, распределенных вычислений, поиска информации и других областях.
<ч3>Марк Найорк <стр>Одним из соавторов исследовательской работы является Марк Найорк, выдающийся ученый-исследователь, который в настоящее время имеет звание выдающегося ученого-исследователя в Google DeepMind. Он является соавтором статей для TW-BERT, участвовал в исследованиях по повышению точности использования неявной обратной связи с пользователем, такой как клики, и работал над созданием улучшенного поиска информации на основе искусственного интеллекта (DSI++: Обновление памяти трансформатора с помощью новых документов). ), среди многих других крупных прорывов в области поиска информации.
Дэннис Феттерли
<п>Другой соавтор — Деннис Феттерли, в настоящее время инженер-программист в Google. Он указан как соавтор патента на алгоритм ранжирования, использующий ссылки, и известен своими исследованиями в области распределенных вычислений и поиска информации.
<п>Это лишь двое из выдающихся исследователей, перечисленных в качестве соавторов исследовательской работы Microsoft 2006 года об обнаружении спама с помощью функций содержимого на странице. Среди нескольких особенностей контента на странице, которые были проанализированы в исследовательской работе, была сжимаемость, которую, как они обнаружили, можно использовать в качестве классификатора для указания на то, что веб-страница является спамом.
Обнаружение спама на веб-страницах с помощью анализа контента
Хотя исследовательская работа была написана в 2006 году, ее выводы остаются актуальными и сегодня.
Тогда, как и сейчас, люди пытались ранжировать сотни или тысячи веб-страниц на основе местоположения, которые по сути были дублирующим контентом, за исключением названий городов, регионов или штатов. Тогда, как и сейчас, оптимизаторы часто создавали веб-страницы для поисковых систем, чрезмерно повторяя ключевые слова в заголовках, метаописаниях, заголовках, внутреннем якорном тексте и в содержании, чтобы улучшить рейтинг.
В разделе 4.6 исследовательской работы объясняется:
<блоковая цитата><п>“Некоторые поисковые системы придают больший вес страницам, содержащим ключевые слова запроса несколько раз. Например, для данного термина запроса страница, содержащая его десять раз, может иметь более высокий рейтинг, чем страница, которая содержит его только один раз. Чтобы воспользоваться преимуществами таких механизмов, некоторые спам-страницы копируют свое содержимое несколько раз, пытаясь занять более высокий рейтинг.”
<п>В исследовательской статье объясняется, что поисковые системы сжимают веб-страницы и используют сжатую версию для ссылки на исходную веб-страницу. Они отмечают, что чрезмерное количество избыточных слов приводит к более высокому уровню сжимаемости. Поэтому они приступили к проверке наличия корреляции между высоким уровнем сжимаемости и спамом.
Они пишут:
“В этом разделе наш подход к поиску избыточного содержимого на странице заключается в сжатии страницы; Чтобы сэкономить место и время на диске, поисковые системы часто сжимают веб-страницы после их индексации, но перед добавлением в кэш страниц.
…Мы измеряем избыточность веб-страниц по коэффициенту сжатия: размер несжатой страницы делится на размер сжатой страницы. Мы использовали GZIP …для сжатия страниц, быстрый и эффективный алгоритм сжатия”
Высокая сжимаемость соответствует спаму
<п>Результаты исследования показали, что веб-страницы со степенью сжатия не ниже 4,0, как правило, являются веб-страницами низкого качества и спамом. Однако самые высокие показатели сжимаемости стали менее последовательными, поскольку было меньше точек данных, что затрудняло интерпретацию.
Рис. 9. Распространенность спама в зависимости от сжимаемости страницы.
<п>
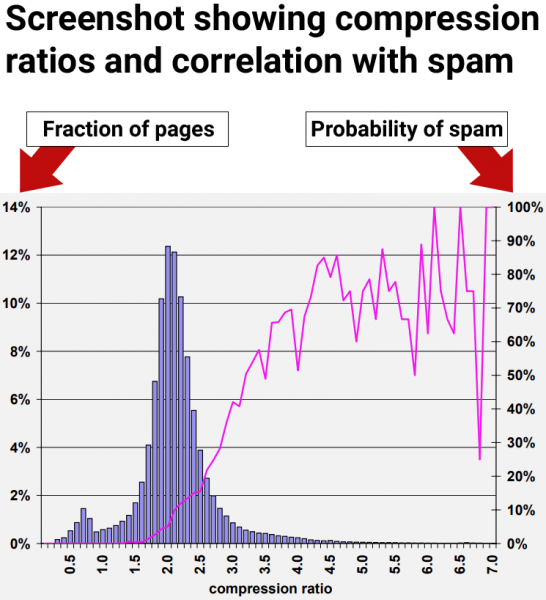
Исследователи пришли к выводу:
“70% всех выбранных страниц со степенью сжатия не менее 4,0 были признаны спамом.”
<п>Но они также обнаружили, что использование коэффициента сжатия само по себе все равно приводило к ложным срабатываниям, когда страницы, не являющиеся спамом, ошибочно идентифицировались как спам:
“Эвристика степени сжатия, описанная в разделе 4.6, показала себя лучше всего, правильно идентифицировав 660 (27,9%) спам-страниц в нашей коллекции, но ошибочно идентифицировав 2068 ( 12,0%) всех оцененных страниц.
При использовании всех упомянутых функций точность классификации после десятикратной перекрестной проверки обнадеживает:
95,4% оцененных нами страниц были классифицированы правильно, а 4,6% были классифицированы неправильно.
Точнее, для спама класса 1 940 из 2364 страниц были классифицированы правильно. Что касается класса «не спам», то 14 440 из 14 804 страниц были классифицированы правильно. Следовательно, 788 страниц были классифицированы неправильно.”
В следующем разделе описано интересное открытие о том, как повысить точность использования сигналов на странице для выявления спама.
Взгляд на рейтинги качества
В исследовательской работе изучались многочисленные сигналы на странице, включая сжимаемость. Они обнаружили, что каждый отдельный сигнал (классификатор) способен обнаружить некоторое количество спама, но использование любого отдельного сигнала приводит к пометке неспамовых страниц как спама, что обычно называют ложным срабатыванием. <п>Исследователи сделали важное открытие, которое должен знать каждый, кто интересуется SEO: использование нескольких классификаторов повышает точность обнаружения спама и снижает вероятность ложных срабатываний. Не менее важно и то, что сигнал сжимаемости идентифицирует только один вид спама, но не весь спектр спама.
Вывод: сжимаемость — хороший способ идентифицировать один вид спама, но существуют и другие виды спама, которые не улавливаются с помощью этого единственного сигнала. Другие виды спама не улавливались сигналом сжимаемости.
Это та часть, о которой должен знать каждый оптимизатор и издатель:
“В предыдущем разделе мы представили ряд эвристик для анализа спам-веб-страниц. То есть мы измерили несколько характеристик веб-страниц и обнаружили диапазоны этих характеристик, которые коррелируют с тем, что страница является спамом. Тем не менее, при индивидуальном использовании ни один метод не выявляет большую часть спама в нашем наборе данных без пометки многих страниц, не являющихся спамом, как спама.
<п>Например, учитывая эвристику степени сжатия, описанную в разделе 4.6, один из наших наиболее многообещающих методов, средняя вероятность спама для коэффициентов 4,2 и выше составляет 72%. Но только около 1,5% всех страниц попадают в этот диапазон. Это число намного ниже 13,8% спам-страниц, которые мы определили в нашем наборе данных.”
Таким образом, хотя сжимаемость была одним из лучших сигналов для идентификации спама, она все равно не смогла раскрыть весь спектр спама в наборе данных, который исследователи использовали для проверки сигналов.
Объединение нескольких сигналов
<п>Приведенные выше результаты показали, что отдельные сигналы низкого качества менее точны. Поэтому они протестировали, используя несколько сигналов. Они обнаружили, что объединение нескольких сигналов на странице для обнаружения спама привело к повышению точности и меньшему количеству страниц, ошибочно классифицированных как спам.
Исследователи объяснили, что они тестировали использование нескольких сигналов:
“Один из способов объединения наших эвристических методов — рассматривать проблему обнаружения спама как проблему классификации. В этом случае мы хотим создать классификационную модель (или классификатор), которая, учитывая веб-страницу, будет совместно использовать функции страницы, чтобы (мы надеемся, правильно) классифицировать ее в один из двух классов: спам и нежелательный контент. -спам.”
Вот их выводы об использовании нескольких сигналов:
<блоковая цитата><п>“Мы изучили различные аспекты контентного спама в Интернете, используя реальный набор данных, полученный сканером MSNSearch. Мы представили ряд эвристических методов обнаружения контентного спама. Некоторые из наших методов обнаружения спама более эффективны, чем другие, однако при использовании по отдельности наши методы могут не выявить все спам-страницы. По этой причине мы объединили наши методы обнаружения спама, чтобы создать высокоточный классификатор C4.5. Наш классификатор может правильно идентифицировать 86,2% всех спам-страниц, помечая при этом очень мало законных страниц как спам.”
Ключевая информация:
Ошибочное определение “очень немногих законных страниц как спама” был существенным прорывом. Важная мысль, которую должен вынести каждый, кто занимается SEO, заключается в том, что один сигнал сам по себе может привести к ложным срабатываниям. Использование нескольких сигналов повышает точность.
<п>Это означает, что SEO-тесты изолированных сигналов ранжирования или качества не дадут надежных результатов, которым можно доверять при принятии стратегических или бизнес-решений.
<ч2>Вынос
Мы не знаем наверняка, используется ли сжимаемость в поисковых системах, но это простой в использовании сигнал, который в сочетании с другими можно использовать для перехвата простых видов спама, таких как тысячи дорвеев с названиями городов и похожим содержанием. Тем не менее, даже если поисковые системы не используют этот сигнал, это показывает, насколько легко обнаружить такого рода манипуляции поисковых систем и что поисковые системы сегодня вполне справляются с этим.< /п>
Вот ключевые моменты этой статьи, о которых следует помнить:
<ул>