
<стр>Разбираем утечку Google, чтобы показать вам, насколько черным на самом деле является Discover Box (подсказка: это не так).
<стр>Все это основано на утечке информации из Google и соответствует моему опыту работы с контентом, который со временем стал успешным в Discover. Я выбрал, по моему мнению, наиболее известные прокси-серверы Discover и сгруппировал их в соответствующий рабочий процесс.
<с>Как опальный сотрудник BBC, мысли принадлежат мне.
TL;DR
<ол>

Изображение предоставлено: Гарри Кларксон-Беннетт
Я насчитал 15 различных прокси, которые Google использует, чтобы насытить думскроллеров’ отчаянная потребность в качественном контенте в ленте Discover. Это не, а отличается от того, как работает традиционный поиск Google.
Но традиционный поиск (высококачественный канал извлечения) совершенно не похож на Discover. Зрители убивают время в поездах. У своих родственников. Туалет. Поскольку они являются частью одной экосистемы, они объединены в одно монолитное целое.
И вот как это работает.
Изображение предоставлено: Гарри Кларксон Беннетт
Правила Google Discover
Этот раздел скучный, а правила Google относительно соответствия требованиям крайне расплывчаты:
<ул>
“…Discover использует многие из тех же сигналов и систем , используемых Поиском, чтобы определить, что является… полезным, надежным и ориентированным на людей контент.”
<п>Затем они дают несколько солидных, хотя и мрачных советов по поводу качественных игр – – щелкающий, а не приманка, как сказал бы Джон Шехата. Убедитесь, что ваше избранное изображение имеет ширину не менее 1200 пикселей, и создайте актуальный и ценный контент.
<п>Но мы можем лучше.
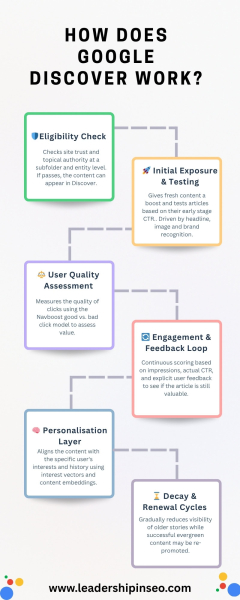
Откройте для себя шестичастный конвейер контента
<стр>От колыбели до могилы: давайте рассмотрим, как именно ваш контент отображается или, в большинстве случаев, не отображается в Discover. Как всегда, помню, что я составил эти кластеры, хотя и на основе реальных прокси Google из утечки Google.
<ол>
Доступность и базовая фильтрация
<п>Для начала ваш сайт должен иметь право на Google Discover. Это означает, что вас считают “доверенным источником” по теме, и у вас достаточно низкий показатель СПАМА, поэтому порог не срабатывает.
Существует три основных показателя, учитывающих право на участие и базовую фильтрацию:
<ул>
Репутация и тематический авторитет сайта оцениваются по рассматриваемой теме. Эти три показателя помогают оценить, может ли ваш сайт появиться в Discover.
<ч3>Первоначальное воздействие и тестирование <стр>Это в значительной степени стадия свежести, когда свежий контент получает временный импульс (потому что современный контент с большей вероятностью насытит ум, зависимый от дофамина). <ул>
Я предполагаю, что, используя прогностическую модель в байесовском стиле, Google применяет полученные знания на уровне сайта и подпапки для прогнозирования вероятного CTR. Чем больше качественного контента вы публикуете с течением времени (предположительно на уровне сайта, подпапки и автора), тем больше вероятность, что вы будете представлены.
Потому что здесь меньше двусмысленности. Ключевая особенность SEO сейчас.
<ч3>Оценка качества пользователя
Статья в конечном итоге оценивается по качеству взаимодействия с пользователем. Google использует модель хороших и плохих стилей кликов из Navboost, чтобы определить, что работает, а что нет для пользователей. Низкий CTR и/или поведение в стиле «пого-залипания» снижают шансы статьи на показ.
<ул> <ли>discover_blacklist_score: Штраф за спам, дезинформацию или кликбейт.
Качество статьи затем измеряется вовлеченностью пользователей. Поскольку Discover — это персонализированная платформа, это можно делать точно и в большом масштабе. Когорты пользователей могут быть сгруппированы вместе. Контент предоставляется людям с одинаковыми общими интересами, если по стандарту алгоритма они должны быть заинтересованы.
<п>Но если слишком кликабельный или вводящий в заблуждение заголовок приводит к плохой вовлеченности (время пребывания и взаимодействие на странице), тогда статья может быть понижена. Со временем такая практика может усугубить и полностью ослабить ваш сайт.

Подобные заголовки — билет в один конец к обесцениванию вашего бренда в глазах людей и поисковых систем (Изображение предоставлено: Гарри) Кларксон-Беннетт)
Важно отметить, что данные о кликах не обязательно должны поступать из Discover. Как только статья выходит в эфир – его опубликовали, поделились в социальных сетях и т. д. – Данные о кликах Chrome сохраняются и применяются к алгоритму.
Итак, чем больше качественных данных о кликах и репостах вы сможете создать на ранних этапах жизненного цикла статьи (с учетом важности актуальности), тем выше ваши шансы на успех в Discover. Относитесь к этому как к вирусной платформе. Поднимите шум. Занимайтесь маркетингом.
Взаимодействие и обратная связь
<п>Как только статья вступает в пресловутую борьбу, начинается цикл оценки и повторной оценки. Постоянный CTR, показы и явные отзывы пользователей (например, «ненавижу» и «не показывайте мне это снова, пожалуйста» в стиле кнопок) позволяют моделям, таким как Navboost, уточнять то, что показывается.
<ул>
Эти поведенческие сигналы определяют успех статьи. Он живет или умирает в зависимости от относительно простых показателей. И чем больше вы его используете, тем лучше он становится. Потому что он знает, что вы и ваши коллеги с большей вероятностью нажмете и получите удовольствие.

Это верно как для Discover, так и для основного алгоритма. Google признал это в постановлениях Министерства юстиции. (Изображение предоставлено: Гарри Кларксон-Беннетт) <блоковая цитата><п>Я предполагаю, что данные заголовков и изображений хранятся так, что алгоритм может применять некоторые строгие стандарты к статистическому моделированию. Как только он узнает, какие типы заголовков, изображений и статей лучше всего подходят для конкретных групп, персонализация становится эффективной быстрее.
Слой персонализации
Google знает о нас много. Это то, на чем построен ее бизнес. Он собирает много неанонимных данных (данные кредитной карты, пароли, контактные данные и т. д.) при каждом возможном взаимодействии с веб-страницами.
Discover выводит персонализацию на новый уровень. Я думаю, это может дать представление о том, как часть результатов поиска может выглядеть в будущем. Персонализированный набор статей, видеороликов и публикаций в социальных сетях, предназначенный для того, чтобы зацепить вас, встроенный где-то рядом с результатами поиска и режимом AI. <п>Все это сделано для того, чтобы вы дольше оставались на ресурсах, принадлежащих Google. Потому что так они зарабатывают больше денег.
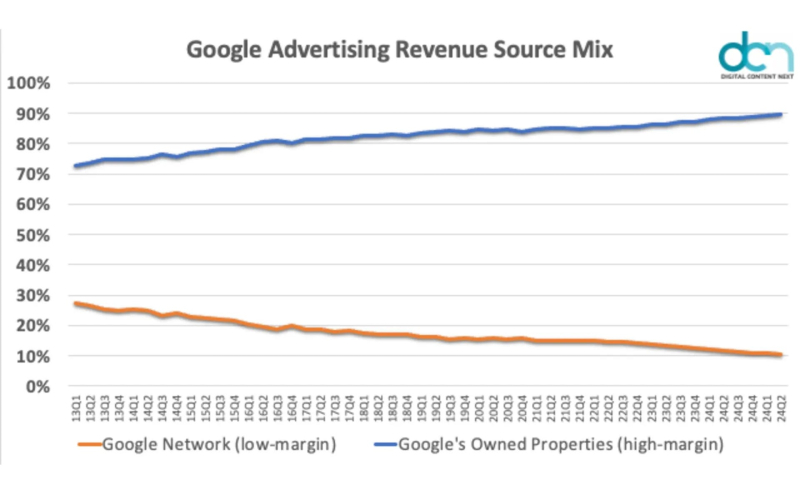
Подсказка: они хотят, чтобы вы были рядом, потому что зарабатывают больше денег (Изображение предоставлено: Гарри Кларксон-Беннетт) <ул>
Контент, который хорошо соответствует вашим личным интересам и интересам группы, будет размещен в вашей ленте.
<п>Вы можете просмотреть сайты, которыми вы часто пользуетесь, используя страницу взаимодействия с сайтом в Chrome (на панели инструментов: chrome://site-engagement/), а также каждое сохраненное взаимодействие с помощью гистограмм. Эти данные гистограммы косвенно показывают ключевые точки взаимодействия с веб-страницами, измеряя реакцию и производительность браузера при этих взаимодействиях.
Там прямо не говоритсяпользователь A нажал X, но регистрируется техническое воздействие, т. е. сколько времени браузер потратил на обработку указанного щелчка или прокрутки.
Циклы распада и обновления
Discover повышает свежесть, потому что люди жаждут этого. Благодаря увеличению количества свежего контента старые или насыщенные истории естественным образом исчезают по мере продвижения новостного цикла и снижения вовлеченности статей.
Для успешных историй это достигается за счет насыщения рынка.
<ул>
Discover — это ответ Google социальной сети. Никто из нас не проводит время в Google. Это не весело. Я использую слово «веселье» в широком смысле. Он не предназначен для того, чтобы зацепить нас и разрушить наше внимание постоянным выбросом дофамина.
<п>Но Google Discover ясно указывает путь к этому. Они хотят сделать его местом назначения. Отсюда и все последние изменения, где можно «наверстать упущенное»; с авторами и издателями, которые вам интересны на разных платформах.
Видео, посты в социальных сетях, статьи … целых девять ярдов. Однако мне бы хотелось, чтобы они перестали суммировать буквально все с помощью ИИ.
Мой рабочий процесс из 11 шагов, позволяющий получить максимальную отдачу от Google Discover
Следуйте основным принципам, и вы принесете себе хорошую пользу. Поймите, в чем тематика вашего сайта сильна, и сосредоточьте свое время на контенте, который будет приносить пользу. Это можно сделать несколькими способами.
<п>Если у вас мало информации в Discover, вы можете использовать данные о кликах и показах в Search Console, чтобы определить области, в которых вы приносите наибольшую ценность. Где вы тематически авторитетны. Я бы сделал это на уровне подпапки и объекта (например, политика и Рэйчел Ривз или Лейбористская партия).
Также стоит разбить это в целом и по статьям. Или вы можете использовать что-то вроде Ahrefs’ Отчет о доле трафика для определения вашей доли голоса через сторонние данные.
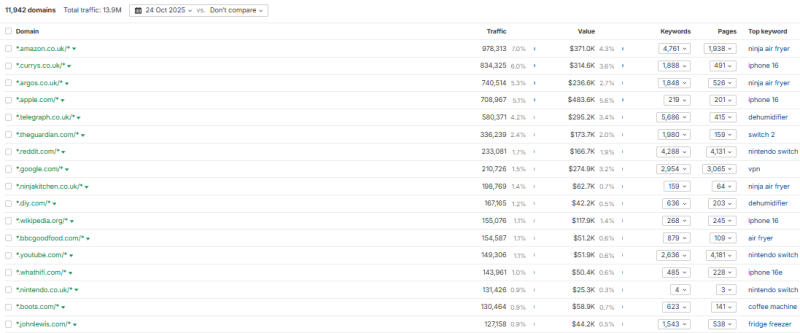
По сути доля голосовых данных (Изображение предоставлено Гарри Кларксоном-Беннеттом)
Тогда сосредоточьте свое время на а) областях, в которых вы уже авторитетны, и б) областях, которые создают ценность для вашей аудитории.
<стр>Предполагая, что вы не сосредотачиваетесь на контенте NSFW и у вас есть смутные основания для этого, вот что бы я сделал: <ол>
<ли>Создайте хорошее качество страницы. Ваша страница (и сайт) должна быть быстрой, безопасной, рекламной и запоминающейся по правильным причинам.
*Я имею в виду, что если прогнозируется, что ваш контент будет набирать три репоста и две ссылки, если вы поделитесь им в социальных сетях и в информационных бюллетенях, и он наберет семь репостов и девять ссылок, у него больше шансов стать вирусным.
Поэтому алгоритм определяет его как ‘достойный открытия’
Первоначально это было опубликовано на сайте Leadership in SEO.


