
<стр>Я проанализировал более 21 000 цитат, чтобы понять влияние длины, глубины и направленности контента.
<п><эм>Повышайте свои навыки с помощью еженедельной экспертной информации Growth Memo. Подпишитесь бесплатно!
<стр>В книге «Наука о том, как ИИ обращает внимание» Я проанализировал 1,2 миллиона ответов ChatGPT, чтобы понять, как именно ИИ читает страницу. Это часть 2.
Там, где в части 1 говорилось где на странице, которую смотрит ИИ, в этой части рассказывается, какие страницы ИИ обычно рассматривает.
Данные уточняют:
<ул>

Изображение предоставлено: Кевин Индиг <х2>1. ~30 доменов владеют 67% цитирований AI по теме
Классический поиск – это игра, в которой победитель получает все. Верхний результат получает непропорционально больше кликов, чем второй. Верно ли это и для ответов ChatGPT? Является ли распределение цитируемых доменов демократическим или тоталитарным?
<сильный>Подход:
<ол>
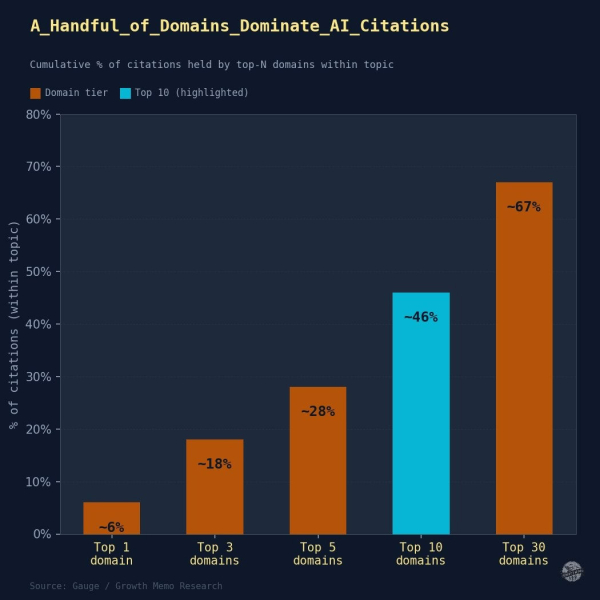
Результаты: Топ-10 доменов занимают 46% всех цитирований в теме. Топ-30 получают 67%.
.
Изображение предоставлено: Кевин Индиг
Цитируемость AI немного менее концентрирована, чем традиционный органический поиск, но все же экстремальна:
<ул> <ли>Фактически в таблице цитирования по любой теме имеется около 30 мест (доменов). Все остальное почти невидимо.
Мы подтвердили эти выводы в вертикалях сравнения продуктов (инструменты SaaS, финансовые консультанты). Однако ниже вы увидите, что эта закономерность слабее в сфере здравоохранения и открытых веб-темах, где не доминирует ни один домен. Примечательно, что сектор образования получает больше всего упоминаний об ИИ среди всех изученных нами отраслей.
Что показали тенденции в отрасли
<п>Вышеприведенные выводы основаны на сравнении продуктов по вертикалям (SaaS, финансовые консультанты), но эта закономерность слабее в сфере здравоохранения и открытых веб-темах, где не доминирует ни один домен, и сильнее в секторе образования.
Изображение предоставлено: Кевин Индиг
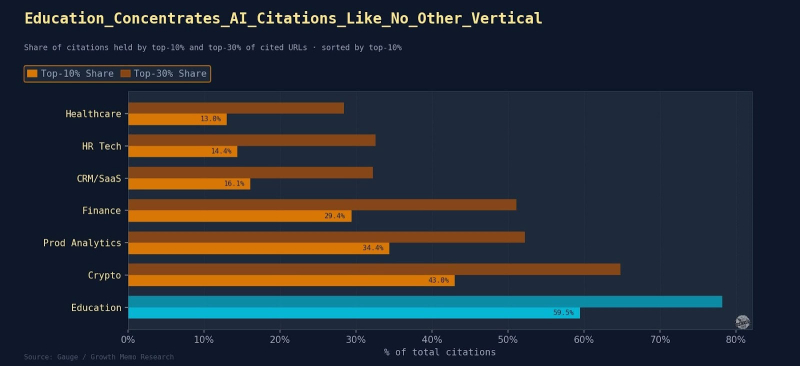
Образование – это принцип, в котором победитель получает больше всего: верхние 10% доменов получают 59,5% всех цитирований.
<ул> <ли>Если вы еще не входите в топ-5-10 областей образования, добиться широты цитирования будет исключительно сложно.
Только
Криптовалюта занимает второе место по концентрации с 43,0% для верхних 10%.
<ул>
Финансы находятся на уровне 29,4% для топ-10%.
<ул>
Здравоохранение является наименее концентрированным: 13,0% для верхних 10%.
<ул>
CRM/SaaS и HR Tech одинаково разбросаны (16,1% и 14,4% топ-10%).
<ул> <ли>Это категории программного обеспечения, состоящие из нескольких продуктов, где десятки сайтов сравнения, платформ обзора и страниц поставщиков разделяют цитирования.
<ч3>Лучшие блюда на вынос <п><сильный>1. Широта тематического охвата важнее, чем авторитет домена. Одна хорошо структурированная страница сравнения (learn.g2.com: 65 уникальных запросов, 495 цитирований) по-прежнему может превзойти все портфолио доменов известного бренда. Цель состоит не в том, чтобы ранжироваться по одному запросу, а в том, чтобы ответить на кластер.
<п><сильный>2. Концентрация отражает зрелость категории. <сильный>Фрагментация – это возможность.Education и Crypto имеют узкие, четко определенные пространства запросов, которым доверяют несколько авторитетных источников. Здравоохранение и CRM — это широкие, фрагментированные категории, в которых не доминирует ни одна область. Эта фрагментация — ваше открытие.
<п><сильный>3. Охват цитирования (количество отдельных запросов, на которые отвечает домен) является более полезным стратегическим показателем, чем простое количество цитирований. В вертикалях с низкой концентрацией внимания, таких как здравоохранение и CRM, сфокусированная стратегия на 30–50 страниц может реально претендовать на место за столом. В вертикалях с высокой концентрацией, таких как образование и криптография, путь уже: станьте исчерпывающим ресурсом по определенной подтеме или смиритесь с тем, что вы боретесь за остатки.<х2>2. Преимущество цитирования начинается с 10 000 слов
В классическом поиске количество слов и длина страницы составляют приблизительно, что указывает на рейтинг, если качество высокое. Я снова задался вопросом, верно ли это и для отображения в ответах ChatGPT?
<п><сильный>Подход <ол>
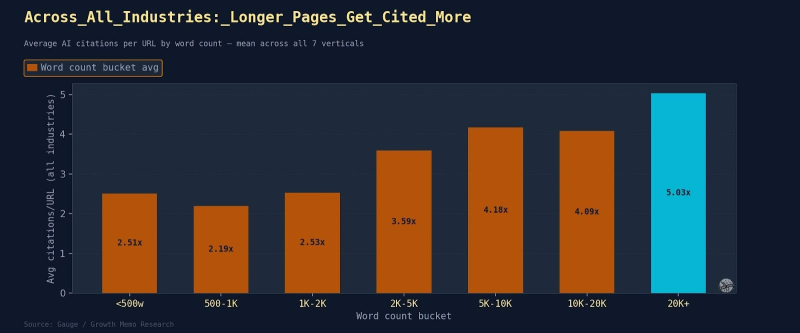
Результаты: Больше слов действительно коррелирует с большим количеством цитирований, но есть потолок.
Изображение предоставлено: Кевин Индиг
Прыжок с 5000 на 10 000 — это самый большой шаг за один шаг – почти в 2 раза. Страницы длиной более 20 000 символов в среднем получают 10,18 цитирований каждая по сравнению с 2,39 для страниц длиной менее 500 символов.
Что показали тенденции в отрасли
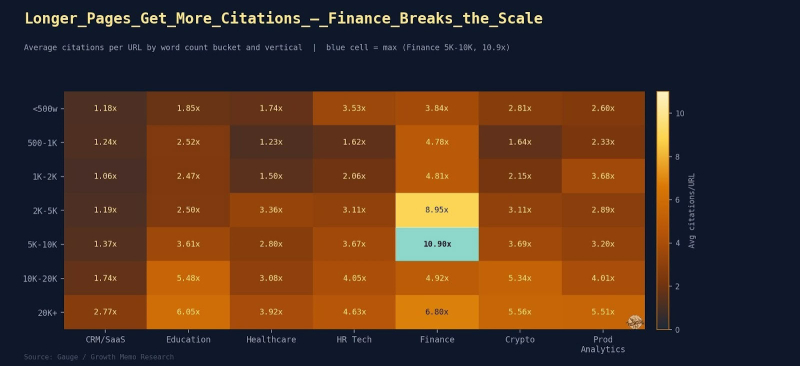
<п>Эффект длины зависит от вертикали: финансы полностью меняют его. На страницах, посвященных финансам, в среднем содержится 1783 слова по сравнению с 2084 словами на страницах с низкой цитируемостью – подъем 0,86х. Авторитетные компактные источники, таблицы тарифов и сводки нормативных документов здесь превосходят полные руководства. Правило 10 000 символов справедливо для SaaS и редакционного контента.
Изображение предоставлено: Кевин Индиг
Финансы достигают пика на уровне 5000-10000 слов (10,9 цитирований/страницу), затем резко падают на уровне 10000-20000 (4,92 цитирования/страницу).
<ул> <ли>Финансы также демонстрируют самый резкий абсолютный прирост: страницы объемом менее 500 слов приносят только 3,84 цитирования на страницу, тогда как 5 000–10 000 страниц приносят 10,9, что составляет 2,8-кратный множитель только за счет оптимизации длины.
Образование демонстрирует наиболее четкую закономерность: длина выигрывает все.
<ул>
Криптовалюта и аналитика продуктов ведут себя аналогично образованию.
<ул>
SaaS демонстрирует самый слабый эффект длины: количество цитирований на страницу варьируется от 1,06 (1000–2000 слов) до 2,77 (более 20 000 слов).
<ул> <ли>Даже самые длинные страницы CRM получают в среднем только 2,77 цитирований на страницу.
Здравоохранение демонстрирует умеренный эффект длины (от 1,74 до 3,92 цитирований на страницу).
<ул>
<ч3>Лучшие блюда на вынос <п><сильный>1. Универсальный вывод: очень короткие страницы (менее 1000 слов) отстают по каждой вертикали. Недостаточная эффективность небольшого контента постоянна, но награда за длинный контент зависит от вертикали.
<п><сильный>2. Выбирайте длину в зависимости от отрасли, типа контента и цели запроса, а не универсального количества слов. Для финансовых отраслей: стремитесь к 5000–10 000 слов. Образование, криптография и продуктовая аналитика: работайте как можно дольше. CRM/SaaS: структура важнее количества слов.
<х2>3. 58% цитируемых URL-адресов цитируются один раз
Когда мы смотрим на цитирование внутри темы, мы часто видим, что цитируется много страниц в домене. Итак, сколько цитирований может получить одна страница?
<п><сильный>Подход <п>1. Подсчитайте количество уникальных подсказок на каждой странице.
<ул>
Результаты: В среднем 67% цитируемых URL-адресов появляются только в одном запросе.
<стр>Думайте об этом как об игре со следами. Первичное количество цитирований показывает, насколько популярна страница. Широта цитирования говорит о том, насколько это стратегически ценно. Вечнозеленая страница в цитировании ИИ — это не та страница, которую цитируют много; он постоянно появляется в различных запросах.
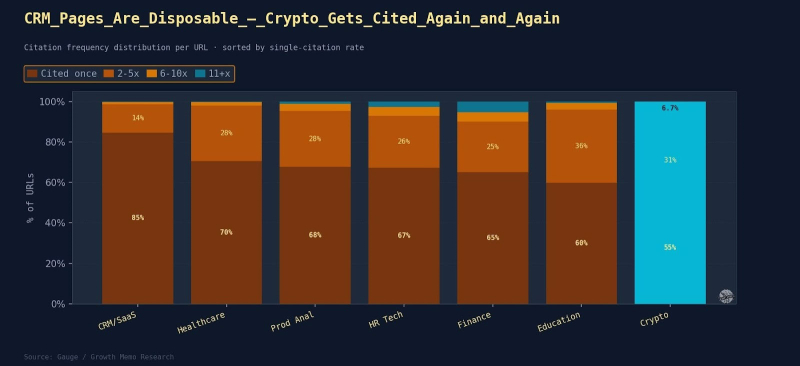
Изображение предоставлено: Кевин Индиг
Верхние 4,8% URL-адресов (цитируется более 10 цитированных) — это сравнения на уровне категорий или руководства, отвечающие на вопрос «что это такое?» “кто этим пользуется” “как выбрать” и “цены” в одном URL.
Что показали тенденции в отрасли
Пул цитирования не является меритократией лучшего ответа, но степень его резко варьируется.
<ул>
<ли>Crypto генерирует наиболее концентрированные вечнозеленые страницы (55,4%) на техническом уровне: Chainstack.com/best-solana-rpc-providers-in-2026 (63 запроса), alchemy.com/overviews/solana-rpc (62 запроса) и rpcfast.com/blog/rpc-node-providers (61 запрос). Все три страницы представляют собой страницы сравнения, освещающие ситуацию с поставщиками Solana RPC под несколько разными углами.
Главные выводы
<п><сильный>1. Страницы Evergreen имеют одинаковые структурные шаблоны: формат руководства на уровне категорий (лучший X для 2025/2026 гг.), широкий охват тем на одной странице (что такое X, как выбрать X, основные поставщики X, цены) и явная привязка года к URL-адресу или заголовку. Страницы, отвечающие на определенный класс вопросов, увеличивают цитируемость.
<п><сильный>2. Пять лучших вечнозеленых страниц в каждой вертикали — это либо сравнительные обзоры, авторитетные руководства или страницы каталогов/списков. Ни одна тонкая однотематическая страница не достигает уровня подсказки 11+ ни в одной вертикали.
<п><сильный>3. Одна вечнозеленая страница, охватывающая более 10 намерений запроса, приносит больше цитируемости с точки зрения ИИ, чем 10 страниц с одним намерением. Окупаемость инвестиций в комплексный контент имеет первостепенное значение: одна хорошо построенная страница со временем увеличивает цитируемость. Длинный хвост существует, но верхние 5% страниц захватывают непропорционально большую долю текущей активности цитирования.
<х2>4. Лыжный спуск на некоторых вертикалях круче
Подход: повторите тот же позиционный анализ по 7 вертикалям с 42 460 совпадающими цитатами.
Результаты: Тенденция реальна, но зависит от темы. Везде справедлива одна цифра: нижние 10% любой страницы получают 2,4–4,4% цитирований, что примерно четверть того, что зарабатывает пиковая группа. Заключительная часть почти невидима для ИИ, независимо от вертикали.
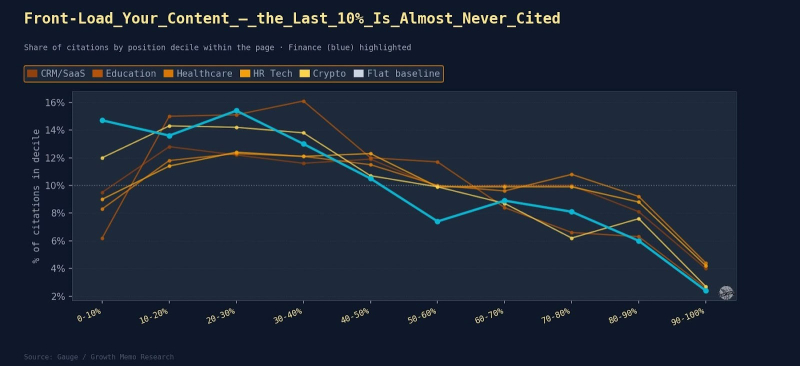
Изображение предоставлено: Кевин Индиг
Что показали тенденции в отрасли
Истинный пиковый дециль по всем вертикалям — это не самое открытие. В диапазоне 10–20% ИИ читает труднее всего по каждой вертикали. Первые 10% обычно составляют навигацию, заголовки и вступительную информацию, которую ИИ пропускает.
<ул> <ли><сильный>Финансы – это крайний случай. 43,7% ссылок приходится на первые 30% страницы. На финансовых страницах отображаются данные о скорости начальной загрузки, проценты и ключевые цифры. ИИ хватает их и редко читает дальше середины.
<ч3>Лучшие блюда на вынос <п><сильный>1. Поместите наиболее цитируемые утверждения и данные в первые 30% страницы– независимо от того, в какой отрасли вы работаете. Резюме и выводы цитируются редко. <п><сильный>2. Для финансовых брендов: Загрузите как можно больше диссертации и статистики.
Что это означает для повышения видимости LLM
Домены, владеющие долей цитирования, не достигли этого благодаря написанию лучших предложений. Они создали страницы, обладающие истинным тематическим авторитетом, отвечая на множество запросов в одном месте, а затем повторили этот авторитет в достаточном количестве подтем, чтобы занять несколько мест за столом.
<п>Для цитирования по 30, 60 или 100 различным запросам требуется целевая архитектура контента: страницы построены на основе кластеров запросов и содержат целые темы, а не отдельные ключевые слова. Команды, которые придерживаются традиционного принципа «одно ключевое слово, одна страница»; модель будет структурно заблокирована для цитирования ИИ, даже если ее отдельные страницы красиво написаны.
Но, как показывают данные, универсального сценария не существует. Тактика, которая работает на широкой CRM-платформе, может серьезно навредить финансовому бренду.
<сильный>Методология
Мы проанализировали около 98 000 строк цитирования ChatGPT, взятых примерно из 1,2 миллиона ответов ChatGPT от Gauge.
Поскольку ИИ ведет себя по-разному в зависимости от темы, мы изолировали данные по 7 различным проверенным вертикалям, чтобы гарантировать, что результаты не будут искажены какой-либо одной конкретной отраслью.
Проанализированные вертикали:
<ул>
<ли>Крипто
Чтобы перепроектировать выбор цитат, я прогнал данные через несколько уровней анализа:
<ул>
<ли><сильный>Entity & Извлечение тональности: Я пропустил начальный текст уникальных цитируемых URL-адресов через Google Natural Language API, чтобы классифицировать именованные объекты (даты, цены, продукты), и использовал TextBlob для оценки тональности, сравнивая производительность корпоративного контента с контентом, созданным пользователями (UGC).


