Масштабирование контента с помощью ИИ может показаться победой, пока Google в конце концов не догонит.
За последние несколько лет я наблюдал, как инструменты создания контента с использованием искусственного интеллекта быстро набирают популярность в индустрии SEO/GEO. Эти инструменты обещают использовать ИИ для автоматизации создания контента, сокращения численности персонала, сокращения затрат и масштабирования выпуска.
<п>Как человек, который последние десять лет помогал компаниям восстанавливаться после обновлений алгоритмов Google, мое паучье чутье начало покалывать в ту минуту, когда я услышал предложения по многим из этих инструментов. Еще до того, как ИИ стал частью разговора, у Google уже была долгая история снижения видимости автоматизированного контента в результатах поиска.
Несмотря на недавние улучшения качества результатов искусственного интеллекта, я по-прежнему скептически отношусь к тому, что публикация контента, созданного или с помощью искусственного интеллекта, в больших масштабах может обеспечить устойчивую производительность результатов поиска Google. Это особенно актуально сейчас, учитывая, что в последние годы Google обновил свои системы ранжирования специально для понижения уровня чрезмерно оптимизированного, ориентированного на SEO контента. src=”https://www.searchenginejournal.com/wp-json/sscats/v2/tk/Middle_Post_Text”>
За последние несколько месяцев я отслеживал более 220 веб-сайтовкоторые были публично идентифицированы либо ими самими, либо поставщиками ИИ-контента как клиенты различных платформ создания, автоматизации и масштабирования ИИ-контента. Эти инструменты полностью пишут статьи, помогают в их написании или используют автоматизацию и рабочие процессы искусственного интеллекта для поддержки создания контента. Многие из этих инструментов теперь также ориентированы на повышение видимости, упоминаний и цитирований в результатах поиска ИИ (AEO/GEO).
<п>Я хотел проанализировать, что происходит после заявлений о крупных выигрышах. <п>На более чем 220 сайтах, которые я отслеживаю, возникла последовательная закономерность, и я считаю, что она достаточно тревожна, чтобы о ней стоит написать: он работает, пока не работает.
Ниже я расскажу о некоторых тенденциях, которые наблюдаю, а также о различных распространенных подходах к SEO/GEO, которые, по моему мнению, могут привести к снижению видимости в органическом поиске (и, следовательно, поиске с помощью ИИ). Напоминаем: то, что опасно для SEO, может быть опасно и для поиска ИИ, во многом из-за RAG.
<сильный>Методология и усилитель; Отказ от ответственности
<стр>Прежде чем мы углубимся, важно подготовить почву для моего подхода и сделать несколько важных заявлений об отказе от ответственности.
Этот анализ основан на сторонних данных SEO-измерений: оценках органического трафика и данных временных рядов количества органических страниц от Ahrefs, подтвержденных данными индекса видимости Sistrix для подтверждения более широких моделей видимости. URL-адреса с наибольшим трафиком были определены с помощью Ahrefs’ экспорт верхних страниц. Когда я описываю шаблоны URL-адресов или процентные изменения, я цитирую непосредственно эти сторонние инструменты по состоянию на май 2026 года.
Набор данных охватывает более 220 клиентских доменов, которые отслеживаются на общедоступных страницах историй клиентов более чем дюжины платформ искусственного контента. Для многих из этих сайтов я сузил анализ до <сильных>конкретная подпапка, в которой был опубликован контент с помощью ИИ, либо указанный непосредственно в самом тематическом исследовании, либо выведенный из резкого увеличения количества новых страниц примерно во время публикации тематического исследования.
<п>Анализ, выводы и рекомендации в этой статье отражают мое собственное профессиональное мнение, основанное на более чем десятилетнем опыте помощи компаниям в восстановлении после обновлений алгоритмов Google. Другие специалисты по SEO/GEO могут не согласиться с моими выводами и подходами, а отдельные сайты и стратегии всегда будут иметь свой собственный контекст.
3 Важные заявления об отказе от ответственности в отношении этих данных:
Во-первых, это сторонние оценки, а не собственная аналитика. Это хорошо проверенные инструменты в SEO-индустрии, но они не являются идеальными показателями эффективности органического поиска.
<п>Во-вторых, описанное здесь снижение трафика может отражать множество факторов, включая, помимо прочего, корректировку алгоритмов со стороны Google, изменения на сайте самих операторов сайта, динамику конкуренции за пределами сайта, изменения бренда, приобретения, сезонность и изменения во внутренней архитектуре сайта. Я не утверждаю, что какой-либо контент-инструмент с искусственным интеллектом напрямую вызвал какой-либо результат трафика, описанный в этой статье. Я описываю корреляцию, наблюдаемую на многих сайтах, включенных в список, которые имеют схожие шаблоны контента и траектории органического трафика.
В-третьих, здесь намеренно не указаны производители и конкретные домены. Образец – это история, а не конкретные действующие лица. Любое сходство с конкретной компанией, поставщиком или практическим примером является второстепенным по отношению к более широкому описанному шаблону.
Что показывают данные: быстрый рост перед резким спадом
Если есть что-то, что проясняют данные, то это: <сильный>масштабирование производства контента с помощью ИИ не является стратегией с низким уровнем риска для органического поиска. Это может принести реальную краткосрочную выгоду как в SEO, так и в поиске с использованием искусственного интеллекта (LLM используют поисковые системы), но в этом наборе данных эти выгоды редко сохраняются. Во многих случаях возможные потери превышали первоначальный пик.
По группе из более чем 220 сайтов и подпапок, которые я проанализировал:
<ул>
<п>В рамках этого снижения появляется повторяющаяся траектория: быстрый рост органических страниц в течение шести-12 месяцев; пик органического трафика примерно через три-шесть месяцев после пика контента; а затем резкий спад трафика, который сводит на нет большую часть прироста (и часто падает ниже предыдущего базового уровня) в течение следующего года.
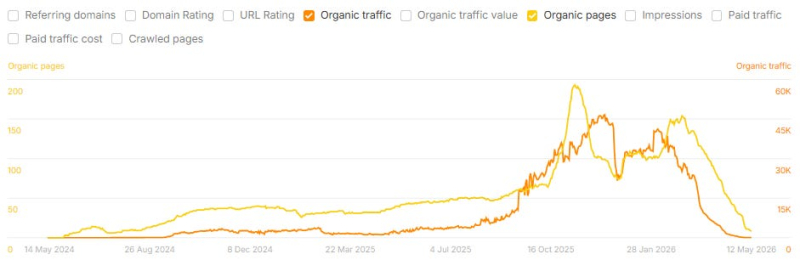
Изображение предоставлено: Лили Рэй
Большая часть этих падений трафика произошла <сильно>после публикации тематических исследований ( что также заставляет меня задаться вопросом, могли ли сами тематические исследования способствовать снижению). В приведенном ниже примере тематическое исследование было опубликовано в январе 2025 года, что обозначено черной звездочкой ниже:
.
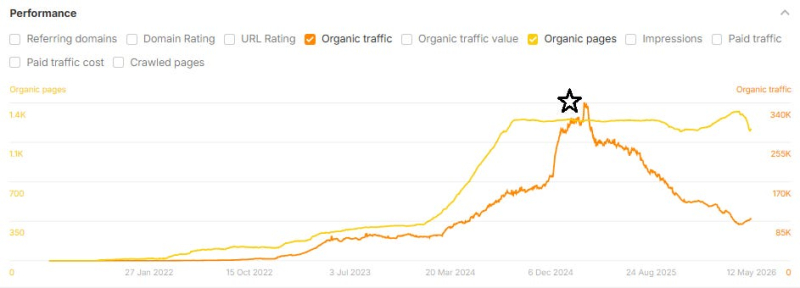
Изображение предоставлено: Лили Рэй
Я также постоянно отслеживаю изменения в органическом росте страниц и органическом трафике на эти сайты и подпапки с течением времени. Судя по обновленным данным, у значительного числа этих брендов <сильных>существенно сократили объем своего контента в 2025 и 2026 годах, часто удаляя, перенаправляя или 410’многие из тех же страниц, которые фигурировали в качестве историй успеха в опубликованных тематических исследованиях. Это может объяснить недавнее падение количества страниц (желтая линия), показанное на скриншоте выше (и, возможно, соответствующее увеличение органического поискового трафика).
<стр>Во многих случаях эти тематические исследования остаются опубликованными и по сей день, но страницы, на которые они ссылаются, нет.
<сильный>Знакомый ранг & Танковая инструкция
Когда трафик на сайте начинает падать из-за проблем с качеством контента в масштабе всего сайта, это редко бывает плавным снижением. По словам Гленна Гейба, лучшим ярлыком было бы «Гора искусственного интеллекта»: резкий рост, за которым следует аналогичное падение органического трафика, как только системы Google соберут достаточно сигналов, чтобы определить, что происходит.
Ниже приведены несколько примеров сайтов, посвященных тематическим исследованиям, которые использовали ИИ для масштабирования создания контента и столкнулись с огромным падением органического трафика после публикации их тематических исследований:
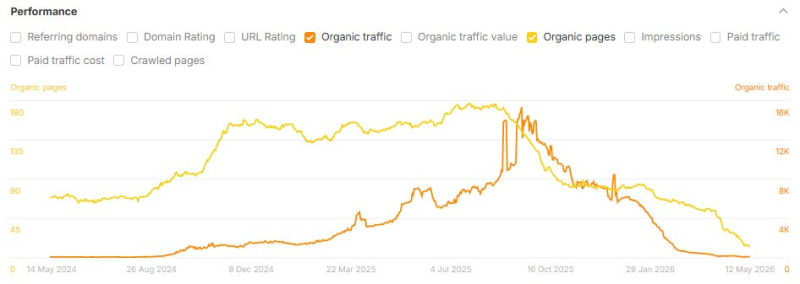
Изображение предоставлено: Лили Рэй
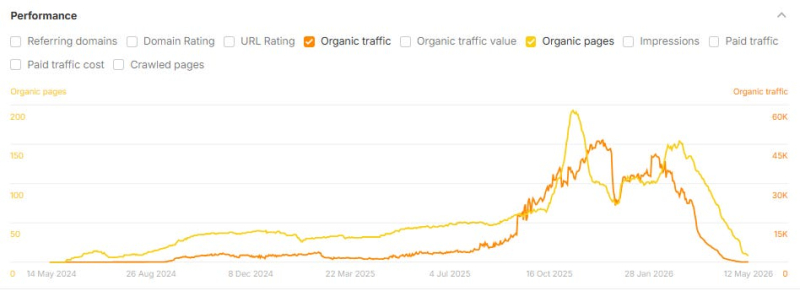
Изображение предоставлено: Лили Рэй
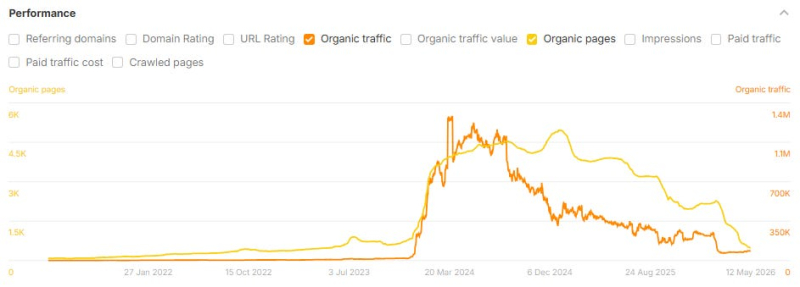
Изображение предоставлено: Лили Рэй
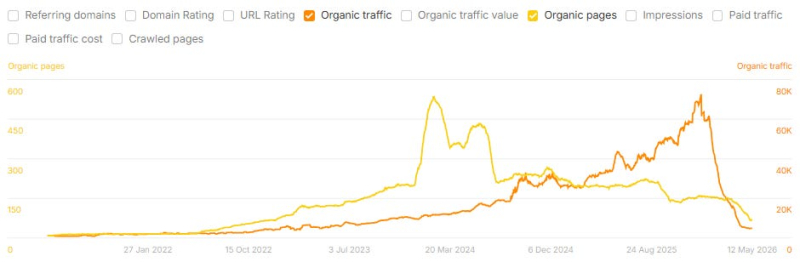
Приход этого сайта в упадок начался во время неподтвержденного “обновления списка саморекламы Google” в январе 2026 года, о чем я также писал в своем Substack (Изображение предоставлено: Lily Ray)
Эта закономерность характерна для всех отраслей, включая кибербезопасность, путешествия, маркетинг, SaaS, здравоохранение, услуги B2B, криптовалюту и потребительские товары, и она проявляется у разных поставщиков.
<п>Форма линии на диаграмме аналогична траекториям, которые мы видели на многих сайтах, пострадавших от обновлений алгоритма Google в последние годы. Это тот же цикл бума и спада, который индустрия SEO неоднократно наблюдала в разных формах, на этот раз ускоренный скоростью, с которой инструменты искусственного интеллекта позволили владельцам сайтов масштабировать контент.
Индустрия SEO только что прошла через это
Что трудно переоценить, так это то, как недавно индустрия SEO наблюдала почти идентичный цикл. Многие оптимизаторы и владельцы сайтов до сих пор зализывают раны после жестоких обновлений Google и новых политик в отношении спама, которые уничтожили многие сайты. трафик несколько лет назад.
В сентябре 2023 года Google запустил обновление полезного контента — самую агрессивную за последние годы борьбу с контентом, который, согласно его объявлению, «кажется, будто он создан для поисковых систем, а не для людей».
Примерно шесть месяцев спустя, в марте 2024 года, последовало самое продолжительное обновление ядра в истории Google, которое, по утверждению Google, было разработано, чтобы «сократить бесполезный, неоригинальный контент в результатах поиска на 45%.» В течение двух последовательных циклов обновлений заявленная цель Google была одной и той же: контент создавался в больших масштабах, независимо от того, использовался ли метод производства человеком, искусственным интеллектом или комбинацией того и другого.
<п>Наряду с обновлением от марта 2024 года Google официально утвердил новую политику в отношении спама под названием «Масштабное злоупотребление контентом». явно называя практику, над пресечением которой они работали: создание множества страниц для манипулирования рейтингом в поисковых системах, независимо от авторства.
Индустрия SEO все еще преодолевает побочный ущерб от этих обновлений, включая значительные потери для многих мелких издателей, некоторые из которых публиковали оригинальный, написанный людьми контент, но использовали чрезмерные SEO-фреймворки, что, вероятно, отмечалось в обновлениях. В список пострадавших также вошли некоторые издатели, которые сотрудничали с рекламными сетями и другими новыми инструментами <сильно>предлагая создание и масштабирование ИИ-контента как услугу.
Потратив сотни часов на анализ и представление этих двух основных обновлений, я могу сказать, что контент, который я вижу, опубликованный с помощью многих из этих новых инструментов искусственного интеллекта часто выглядит и ощущается очень похоже на тот тип контента, который был стерт с лица земли с этими обновлениями Google 2023 и 2024 годов.
8 повторяющихся шаблонов контента, которые опасны для SEO и поиска с помощью искусственного интеллекта
Итак, какие типы контента я вижу, опубликованные компаниями, использующими инструменты ИИ для создания статей, которые, по моему мнению, в конечном итоге опасны для SEO? Я считаю, что ответ кроется в шаблонах страниц, которые призваны влиять на SEO-рейтинг, ответы поиска ИИ и/или цитируемость в поиске ИИ, но являются <сильными>очень шаблонный и легко повторяемый конкурентами.
То, что начинается как искренний подход к созданию полезного контента (и получению упоминания/цитирования), в конечном итоге становится легко обнаруживаемым Google следом, когда достаточное количество сайтов публикует похожие страницы, и индекс переполняется десятками или сотнями тысяч таких похожих страниц, что проще, чем когда-либо, сделать с помощью ИИ.
Именно это имеет в виду Google, когда говорит о писательстве для поисковых систем, а не людей.
<п>Просматривая URL-адреса с наибольшим трафиком в сокращающихся доменах, неоднократно обнаруживаются восемь различных шаблонов контента. Большинство сайтов, где наблюдается снижение результатов анализа, используют комбинацию как минимум из трех или четырех. Самые агрессивные используют все восемь. Как правило, на затронутых сайтах также есть сотни или тысячи таких статей, что усугубляет проблему и обычно приводит к еще большим потерям трафика.
<х3>1. Страницы сравнения в масштабе
<п>Шаблон: /blog/[product-A]-vs-[product-B] публикуется в большом масштабе для наиболее разумных личных встреч в категории. Наблюдается в наборе данных для пар «продукт/продукт», пар «фреймворк/фреймворк» и, по крайней мере в одном случае, пар «концепция/концепция», не связанных с реальным бизнесом издателя.
<х3>2. <сильный>The “What Is X” Глоссарий
Страницы с одним термином и одним вопросом, предназначенные для цитирования системами искусственного интеллекта. Шаблон: /resources/what-is-[термин] или /glossary/[term]. Наблюдается во всем наборе данных, включая программные глоссарии, масштабированные для нескольких языков из одного исходного шаблона. Масштабирование переводов с помощью ИИ и без проверки человеком также часто может приводить к проблемам с качеством контента на всем сайте.
<х3>3. <сильный>The “Лучший [X] для [Y]” Листик
<п>Самый знакомый шаблон AI-контента, берущий свое начало в эпоху партнерского контента. Эта закономерность наблюдалась во всем наборе данных как в вариантах с широкой категорией, так и с узкой нишей.
<х3>4. Список саморекламы
<п>Вариант № 3, в котором издатель сам является конкурентом в рейтинговой категории и часто называет себя лучшим среди конкурентов. На этих страницах обычно отсутствуют реальные доказательства того, что компания действительно протестировала всех конкурентов в списке, рекомендованном Google для страниц обзора.
Я писал об этом “списке” шаблон страницы, вызвавший проблемы с SEO/GEO в феврале 2026 года, когда я обнаружил, что многие компании, публикующие десятки, сотни или даже тысячи саморекламных списков, столкнулись с резким падением трафика, начавшимся в один и тот же день (примерно 21 января 2026 года). Эта закономерность наблюдалась на нескольких сайтах в наборе данных, наиболее активно в сфере B2B-услуг.
<х3>5. Страница «Конкуренты против альтернатив»
Шаблон: /blog/[бренд-конкурент]-альтернативы или, в более программной форме, специальные целевые страницы, созданные для каждого названного конкурента в категории. Этот подход широко наблюдался во всем наборе данных, включая один случай, когда большинство страниц с максимальной посещаемостью сайта были посвящены торговым маркам отдельных конкурентов.
<х3>6. Программное расположение и масштабирование языка
Это один из старейших трюков в книге по SEO, и я видел, как сайты сталкивались с проблемами при обновлении алгоритмов в течение как минимум 10 лет. Подход: используйте один шаблон для каждого региона или языка, который индексирует поисковая система, с очень небольшим количеством уникального контента на локальную целевую страницу.
<п>Во многих случаях компания, публикующая эти страницы, часто не имеет реальных офисов в каждой из страниц района/города/штата, на которые они ориентируются.
Этот тип страниц наблюдался во всем наборе данных, включая контент по штатам, страницы услуг по странам и многоязычные программные глоссарии, описанные выше.
<х3>7. Ферма FAQ
Каждая страница отвечает ровно на один вопрос. Шаблон: /faq/[полный вопрос]. Предназначен для извлечения с помощью механизмов искусственного интеллекта: четкий вопрос в URL-адресе, ответ в первом абзаце, маркеры в тексте, разметка схемы внизу.
Проблема? Этот подход создает много некачественного контента и мусора на сайте при масштабном внедрении. Масштабирование часто задаваемых вопросов также широко наблюдалось в наборе данных, в том числе в отраслях, где шаблонный тон заметно не соответствовал контексту бренда издателя.
Вот скриншот моей статьи на Amsive за март 2024 года, в которой я советую не делать то же самое:
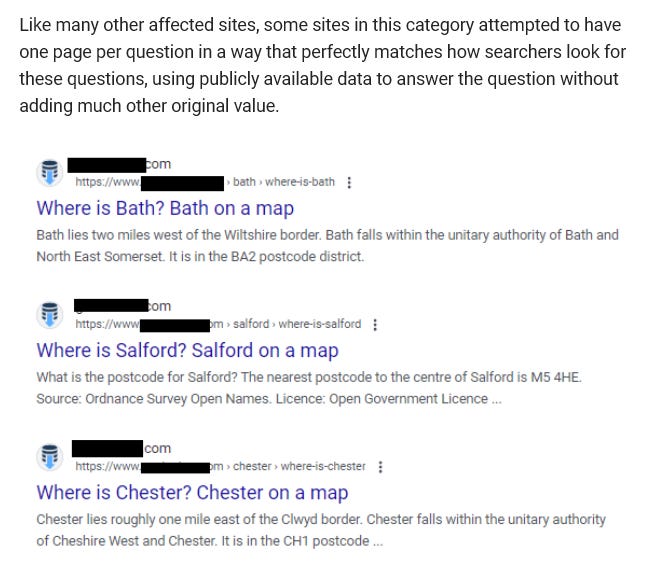
Изображение предоставлено: Лили Рэй
<п>Также стоит отметить, что буквально на прошлой неделе Google объявил об отказе от поддержки расширенных результатов часто задаваемых вопросов, что, как я полагаю, может иметь какое-то отношение к этому новому притоку схемы часто задаваемых вопросов, направленной на попытку заработать цитирования и упоминания в поиске ИИ.
<х3>8. Контент не по теме, опубликованный в масштабе
Публикация контента, не относящегося к теме, без явной связи с реальным бизнесом издателя, в больших объемах, является одним из самых быстрых способов столкнуться с проблемами с алгоритмами поисковых систем. Это также было огромной проблемой во время обновления полезного контента и основных обновлений в марте 2024 года, когда многие сайты экспериментировали с публикацией контента не по теме, такого как забавные цитаты, шутки, детские имена, гороскопы и другие объемные статьи, которые на самом деле не имели актуального значения для издателя.
<п>Этот метод использовался на нескольких сайтах в наборе данных, включая статьи на развлекательные темы на платформе услуг, списки имен и шуток, мемы из социальных сетей на веб-сайтах B2B, а также исторический или биографический контент на сайтах, ориентированных на бизнес.
Неподтвержденное обновление Google от конца января 2026 г.
Вторичная закономерность появляется в данных примерно в конце января 2026 года: на волне сайтов с явно GEO-оптимизированными списками саморекламы, а также с другими рискованными подходами SEO/GEO органический трафик снизился на 40–95 % за период с января по апрель 2026 года.
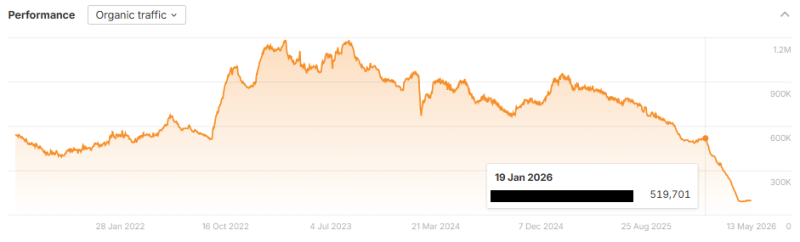
Подпапка блога крупной B2B-компании пострадала от неподтвержденного обновления Google от конца января 2026 года. (Изображение предоставлено: Лили Рэй)
Google не объявлял и не подтверждал обновление по имени в январе 2026 года, но по крайней мере на 40 сайтах, которые я идентифицировал, наблюдалась негативная тенденция, начиная примерно с 20 января 2026 года. Во многих случаях влияние ограничивалось блогом компании или другой подпапкой, содержащей много нового SEO-контента. Мой анализ показал, что некоторые из этих компаний размещали десятки, сотни или даже тысячи таких саморекламируемых списков, в которых они называли свою компанию лучшей по сравнению с конкурентами.
Я подозревал, что эта корректировка со стороны Google была <сильная>только началоGoogle (и, вероятно, провайдеры LLM, опирающиеся на поиск) начали понижать этот тип контента в результатах поиска, и похоже, что влияние было больше, чем просто сами списки. На затронутых сайтах часто снижался весь блог или подпапка, содержащая эти статьи. В других случаях воздействие распространялось на весь домен.
Как безопасно использовать инструменты AI-контента
Я верю, что существует способ безопасного использования инструментов искусственного интеллекта для создания контента, а также способ, с помощью которого эти инструменты могут поддерживать создание высококачественного контента. Сами инструменты не являются проблемой, но реализация может быть проблемой.Я считаю, что эти инструменты должны использоваться и контролироваться опытными профессионалами в области SEO, которые понимают ландшафт подходов к контенту, которые Google стал чрезвычайно изощренным в наказании и понижении в должности за последние 10 с лишним лет. Проблема часто возникает из-за того, что вы «поставили и забыли». подход или когда цель состоит в том, чтобы как можно быстрее масштабировать как можно больше страниц без участия человека.
Использование инструментов искусственного интеллекта для создания контента для исследований, организации, составления кратких обзоров контента, получения собственных данных и идей компании и т. д. может иметь неоценимое значение для ускорения процесса создания контента. Но когда статьи просто публикуются “для SEO/GEO” Без учета рисков, связанных с системами ранжирования поисковых систем, контент, созданный с благими намерениями, может фактически иметь неприятные последствия как для SEO, так и для поиска AI.
<п>Чтобы работать хорошо, я рекомендую, чтобы любой контент, созданный с помощью ИИ, по-прежнему демонстрировал E-E-A-T, добавлял оригинальную или уникальную информацию помимо той, что предлагается на конкурирующих страницах (прирост информации), и рассматривал возможность прозрачности использования ИИ для создания контента (что рекомендовано Google).
<сильный>Итог
Если и есть один вывод из мониторинга этих более чем 220 сайтов за последние несколько месяцев, так это то, что сборники инструкций, продаваемые как “AI-first SEO” или “ГЕО-оптимизированный контент в любом масштабе” выглядят удивительно похожими на сборники пьес, которые уничтожили сайты в результате обновления полезного контента и основного обновления за март 2024 года. Упаковка новая, но узора нет.
Во всем наборе данных продолжают расти бренды, как правило, те, чей контент не соответствует восьми шаблонам, приведенным выше. Многие бренды, которые внедрили эти шаблоны, теперь удаляют страницы, перенаправляют подпапки и предпринимают другие шаги, чтобы попытаться смягчить недавние потери трафика.
<п>Если вы в настоящее время оцениваете поставщика контента для искусственного интеллекта или запускаете собственную программу, вот несколько практических вопросов, которые, я думаю, стоит задать, прежде чем публиковать следующую страницу: <ул>
Ничто из этого не означает, что инструменты искусственного интеллекта для создания контента непригодны для использования. Они могут быть действительно полезны для исследований, кратких обзоров, внутреннего синтеза данных и ускорения рабочих процессов, в которых все еще участвует человек-эксперт. Проблемы начинаются, когда объем цели становится больше или когда люди, наиболее близкие к контенту, перестают просматривать то, что выходит за дверь.
Индустрия SEO уже переживала этот цикл один раз за последние несколько лет. Лучше всего из этого вышли сайты, которые отдавали предпочтение качеству, оригинальности и тематической направленности над масштабом. Я ожидаю, что то же самое будет справедливо и в отношении этого цикла, и я буду продолжать отслеживать данные по мере их реализации.
Этот пост был первоначально опубликован на Lily Ray NYC Substack.
Рекомендуемое изображение: Stokkete/Shutterstock


