Большинство читателей Интернета теперь являются машинами. Три вещи, которые, как мы считали, были решены, потихоньку переписываются в соответствии с их требованиями.
<п>Задайте вопрос чат-боту и посмотрите, что за этим происходит в сети. Он читает 30 или 40 страниц, чтобы составить ответ, удаляет то, что ему нужно, и вручает вам аккуратный абзац. Вы никогда не видите страницы, никогда не нажимаете на них. Сайт, который “победил” Что бы ни значила победа сейчас, она получает цитирование светло-серым текстом и ни одного посетителя.
Об этом сейчас читает большая часть Интернета, и компании, управляющие трубами, могут наблюдать за этим. В сети Cloudflare в этом году боты обогнали людей по количеству запросов к реальным веб-страницам — с 57,5% до 42,5%. Его исполнительный директор отметил пересечение в июне, примерно на 18 месяцев раньше, чем его собственный прогноз, и объяснил этот всплеск агентами, получающими страницы от имени людей. Искусственный интеллект на сегодняшний день является самым быстрорастущим сектором: его рост примерно в восемь раз превышает количество посещений людей за прошлый год. Интернет читают больше, чем когда-либо. Только не людьми.
Вот неудобная часть, которую никто не хочет говорить вслух. Правила, которые мы создали для Интернета, касающиеся качества, доступа и честности, были написаны для человеческой аудитории. <сильная>Аудитория изменилась. Правила повторяются для согласования, тихо, и никто не ставит их на голосование. Три из них уже идут. Вот что и почему.
Кто следит за Интернетом и почему это беспокоит
<п>На протяжении двадцати с лишним лет в сети был инспектор трафика, и им был Google. Разместите ключевые слова там, где их никто не увидит, купите тысячу ссылок, раскрутите дорвеи, и рано или поздно на вас что-то упадет с огромной высоты. Большинство людей полагали, что это гигиена. Google поддерживает порядок в сети ради всех и по доброте душевной.
Ничего подобного. Google контролировал Интернет, потому что Google продавал рекламу по его индексу, а индекс, полный мусора, менее ценен для рекламодателей. Уборка представляла собой техническое обслуживание витрины магазина.
<п>Энди Байо наблюдал ту же логику десять лет назад, когда Google позволил Books и ее архиву новостей сгнить в тот момент, когда они перестали зарабатывать себе на жизнь, и предостерег от того, чтобы доверять корпорации выполнение работы библиотеки. Он был щедр. Библиотека всегда была лишь побочным эффектом рекламного бизнеса: она сохранялась, пока приносила прибыль, и закрывалась, когда ее нет.
Я потратил большую часть шести лет на качество поиска и веб-спам в этой операции, поэтому могу сказать вам, что работа была реальной, и инженеры имели в виду именно это. Причина, по которой проект получил финансирование, никогда не вызывала сомнений.
<п>Теперь посмотрим на новых читателей. Система ответов не продает рекламу по четкому индексу, потому что она не сохраняет ее для просмотра. Он читает, взвешивает то, что находит, и повторяет нужную ему часть. Слабая сторона не подлежит наказанию. Его просто не подхватывают, что с точки зрения страницы еще хуже, потому что вместе с электронным письмом приходит как минимум штраф. Начальника больше нет. Есть швейцар, который никогда не говорит вам, почему вы не вошли. <п>И Google теперь занимает обе должности одновременно, и это действительно забавно. Он по-прежнему управляет индексом, финансируемым за счет рекламы, тем, который суд только что признал незаконной монополией как на поиск, так и на рекламу, продаваемую против него. И он создает механизм ответов, который делает этот индекс неактуальным, а затем вбивает в него рекламу так быстро, как позволяет формат: рекламные изображения смешиваются с результатами изображений, реклама внутри сводок AI, прикручивается совершенно новая торговая труба. Компания защищает свой старый бизнес, создавая то, что его положит, и продавая рекламу орудий убийства. Вам не нужна диаграмма.
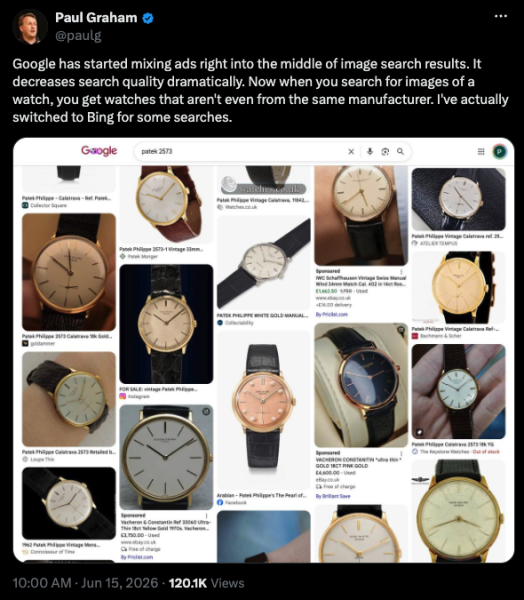
Снимок экрана X, июнь 2026 год
Кто платит, чтобы попасть
Старая сделка была справедливой и даже щедрой. Впустите нашего сканера бесплатно, сказал Google, и мы отправим читателей обратно к вам. Сайты не просто терпели сканирование; они боролись за то, чтобы их сканировали быстрее и индексировали глубже, потому что сканирование было прямым путем к аудитории.
<п>Сканирование ИИ не делает такого предложения. Он берет тот же контент, преобразует его в ответ и ничего не отправляет обратно. Ни клика, ни читателя, ни рекламы для продажи. Cloudflare, которая контролирует примерно пятую часть сети, сказала тихую часть в микрофон в июле 2025 года: старая сделка нарушена, поэтому новые сайты в ее сети теперь по умолчанию блокируют сканеры с искусственным интеллектом, а владельцы могут взимать плату за сканирование через торговую площадку, которая вручает любому боту, не желающему платить, вежливую «требуется оплата». и ничего больше. Тридцать лет умоляла Google сканировать больше, а теперь рефлексом стало установить пропускной пункт.
В Британии 31 издательство прошло блокировку. Они превратили старый файл robots.txt, вежливую фразу «пожалуйста, не надо, которую сканеры научились игнорировать», в обязательный договор: загрузите страницу, повторно используйте статью без оплаты, и вы согласились на счет на сумму 500 фунтов, который окружной суд может взыскать, как и любой другой долг. На самом деле никто еще ничего не получил от OpenAI, но этот шаг говорит вам, к чему все идет. У платы за проезд теперь есть прайс-лист.
<п>Почему сейчас, а не пять лет назад, когда началось парсинг? Потому что письмо превратилось в редкость. Когда модель хороша настолько, насколько хорош текст, из которого она учится, а открытая сеть заполняется собственными отходами модели, настоящее человеческое письмо перестает быть сырьем и становится призом. Владельцы поняли, что сидят на входе, а у входа есть цена.
<п>Так что следите за тем, что они на самом деле делают, потому что это говорит вам о реальном аргументе. The New York Times ищет OpenAI для обучения работе с ее архивом и одновременно лицензирует тот же архив для Amazon. OpenAI подписала контракты с Guardian, Atlantic, Washington Post, News Corp и рядом других. Никто из этого списка не пытается отправить машины прочь. Они торгуются по поводу ставки. Гений отсутствует, спрос носит структурный характер, и борьба никогда не шла о том, произойдет ли это. Речь идет о том, кому и сколько платят. Дорога будет построена в любом случае. Спор идет только о плате.
Что сейчас считается мошенничеством
Есть одно правило старше всех остальных: никогда не показывайте сканеру что-то отличное от того, что вы показываете человеку. Это маскировка, а маскировка стирает ваши данные. Каждый оптимизатор учится этому с первого дня.
<п>Но читайте собственное определение Google, а не фольклор. Клоакинг представляет собой предоставление различного контента пользователям и поисковым системам с намерением манипулировать рейтингами и вводить людей в заблуждение. То, что сделало это мошенничеством, не то, что две версии различались, а <сильное>намерение обмануть, находящееся под ним. Показ сканеру страницы о праздниках и человеку страницы, рекламирующей подделки фармацевтических препаратов, маскирует ситуацию. Передавать одни и те же факты в более чистой, машиночитаемой форме чему-то, что читает только машиночитаемые формы, невозможно и никогда не было. Собственные рекомендации Google говорят то же самое: адаптируйте презентацию так, как вам нравится, главное, чтобы суть оставалась той же.
<п>Поэтому, когда читатель является агентом, которому нужны структурированные данные вместо вашего главного изображения и баннера cookie, обработка структурированных данных не является уловкой. Он отвечает на языке, на котором спросил. Табу предполагало, что краулер является заменой пары человеческих глаз. Уберите это предположение, и большая часть табу останется вместе с ним.
Здесь я должен на мгновение побыть занудой, занимающейся веб-спамом, потому что линия все еще существует, и она только что переместилась. Лгите машине, чтобы изменить рейтинг, или скормите ей что-то, за что вы бы никогда не отступили перед человеком, и это все равно будет расценено как намерение обмануть, а в отношении здоровья, денег и всего остального, где неправильный ответ причиняет кому-то вред, это по-прежнему опасно. Обман – это линия. Форматирование вашего контента для читателя, который является машиной, никогда не было неправильным.
Что осталось людям
<п>Все это не является прогнозом. Это уже произошло с теми частями сети, которые больше всего волнуют машины, и оттуда это работает. Направление не подлежит обсуждению. Единственные актуальные вопросы — это условия: кому платят, кого отгораживают, и чья бизнес-модель получает право решать, как будет выглядеть хороший ответ.
Последний широко открыт, и за ним стоит внимательно следить, потому что люди, строящие новую входную дверь, не могут договориться о том, как на ней зарабатывать деньги. Google вставляет в ответы рекламу. Perplexity попробовала рекламу, убила ее и теперь клянется, что пользователь должен верить, что получает лучший ответ, а не самый высокооплачиваемый. Anthropic избавляет Клода от рекламы и говорит так громко. OpenAI тестирует рекламу, обещая, что она не исказит ответ. Это именно то обещание, которое Google дал в отношении результатов поиска, и мы все помним, как это состарилось. Тот, кто выиграет этот спор, унаследует старую работу надзирателя и сможет определять «хорошие» вещи. что касается Интернета, большинство людей теперь используют подержанные.
Что оставляет остальным из нас меньшую и незнакомую работу. Сеть с машинным чтением не заботится о том, насколько умным будет ваш заголовок или насколько привлекательно выглядит ваша страница. Его невозможно очаровать или польстить. Он сохраняет то, что полезно для ответа, и игнорирует все остальное, а это означает, что выживающая работа — это работа под прикрытием: исходный отчет и суждение, позволяющее узнать, является ли ответ на самом деле правильным, прежде чем он дойдет до того, кто будет действовать в соответствии с ним. Интернет потратил 30 лет на то, чтобы научиться работать для людей. Теперь он должен быть полезен кому-то, у кого нет больших пальцев, которые можно поднять, и нет рук, чтобы аплодировать.
Этот пост был первоначально опубликован на The Inference.