
ChatGPT и Gemini не просто отвечают на вопросы. Они запускают традиционные поисковые запросы в фоновом режиме, и результаты этих поисков определяют, чей контент будет обнаружен.
<п>Когда ваши клиенты о чем-то спрашивают ChatGPT или Gemini, модель незаметно запускает в фоновом режиме ряд традиционных поисковых запросов, извлекает страницы рейтинга и синтезирует на их основе ответ. Сайты, которые ранжируются по этим скрытым запросам, цитируются. Те, кто этого не делает, не делают этого. QueryFan генерирует подсказки для конкретного человека, пропускает их через обе модели и фиксирует точные поисковые запросы, инициированные каждой из них. Этот список — ваша реальная цель видимости ИИ. Это бесплатно.
Списки ключевых слов полезны, но они пропускают половину картины
<с>Позвольте мне уточнить это, прежде чем кто-нибудь напишет яростный ответ.
Я использую термин “ключевые слова” для обозначения “one-shot” запросы, которые попадают в традиционные поисковые системы. Да, я знаю, что мы попали в “семантический” мире уже более десяти лет, но давайте просто договоримся о терминологии, которой сейчас может следовать каждый.
<стр>Основная проблема “списков ключевых слов” в контексте поиска ИИ тройной:
<ол>
По сути, поиск с помощью ИИ стал своего рода «универсальным декодером намерений». для пользователей. Эти большие, многогранные разговоры с ИИ разбиваются на подмножества решаемых запросов, которые выполняются в фоновом режиме как “традиционные” поиск в Google или Bing, а полученные сайты используются для генерации ответа. Этот процесс известен как “Поисковая дополненная генерация” (ТРЯПКА).
<п>
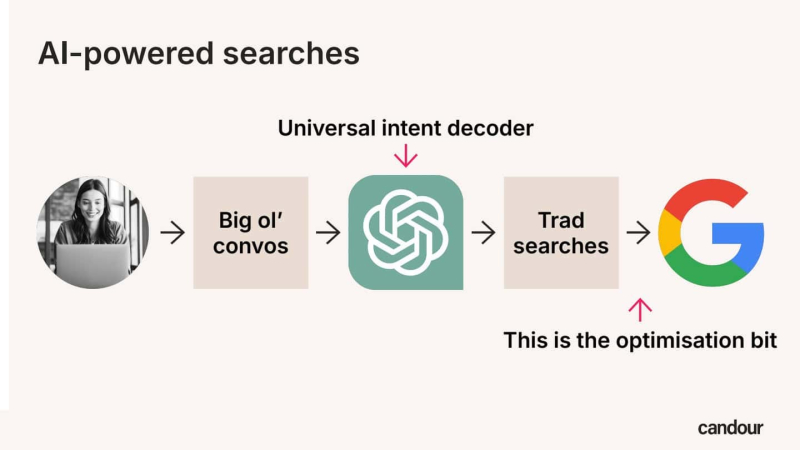
Многие пользователи не знают, что “традиционный” поиск происходит в фоновом режиме (Изображение предоставлено Марком Уильямсом-Куком)
<п>Цель оптимизации изменилась. Вы больше не оптимизируете исключительно то, что люди пишут в окне чата. Вы оптимизируете то, что агент ИИ незаметно ищет от его имени, в фоновом режиме, и пользователь не узнает, что это произошло.
Эти фоновые запросы и фиксирует QueryFan. Они часто сильно отличаются от того, что на самом деле задал пользователь. И это точный список вещей, по которым вам нужно получить рейтинг, чтобы появиться в ответах, сгенерированных ИИ.
Пример А: Reddit упал со скалы во вторник
<п>Масштабы и глубина этих тайных отношений стали очевидны, когда Reddit пережил стремительный рост популярности в Google, и 10 сентября 2026 года случилась трагедия. Согласно данным отслеживания цитирования PromptWatch, уровень цитирования Reddit в ответах ChatGPT рухнул почти за одну ночь. Его цитирование достигло 15% от всех цитирований. В течение нескольких дней он находился ниже 2%.
.
Причина была непривлекательной: в тот день Google незаметно удалил возможность запрашивать 100 результатов поиска одновременно (параметр num=100) из своего API поиска.
<п>
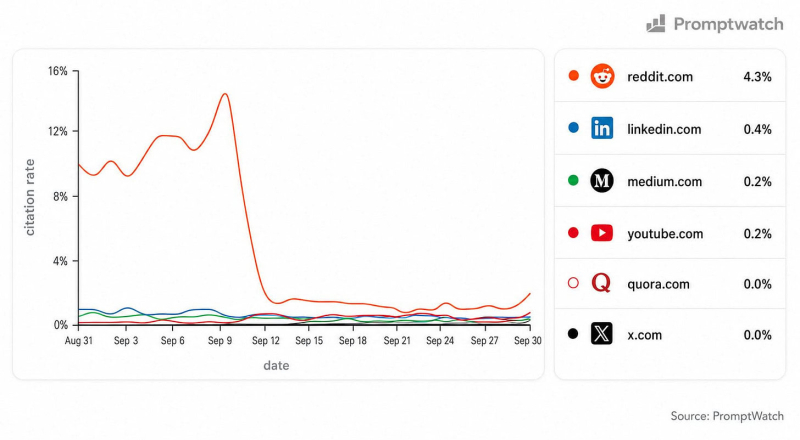
Цитации Reddit в ChatGPT аварийно завершились, когда Google удалил num=100 (Изображение предоставлено Марком Уильямсом-Куком)
<п>Подумайте, о чем это вам говорит. Видимость Reddit в ответах ChatGPT отслеживалась возможностями массового поиска Google, а Reddit не делал ничего, ни обновления обучающих данных, ни настройки выравнивания. Смысл такой же тонкий, как упавшее пианино: ChatGPT массово вытягивал результаты поиска Google, Reddit доминировал в этих результатах в то время, а когда массовое получение исчезло, исчезли и цитирования Reddit.
Как работает QueryFan
<п>
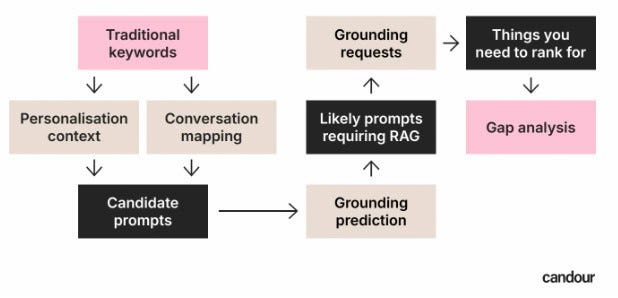
Обзор логики QueryFan.com (Изображение предоставлено Марком Уильямсом-Куком)
<сильный>Шаг 1: Ваш ‘Традиционный’ Ключевые слова
<п>Ваш традиционный список ключевых слов для термина “кроссовки” может включать различные предлагаемые варианты этого термина из такого источника, как Google Offer.
<п>
Для QueryFan.com мы можем просто взять общую тему (Изображение предоставлено Марком Уильямсом-Куком)
Для QueryFan мы можем просто взять тему “кроссовки” и используйте это как наш первый шаг, так как мы собираемся генерировать подсказки на основе этого.
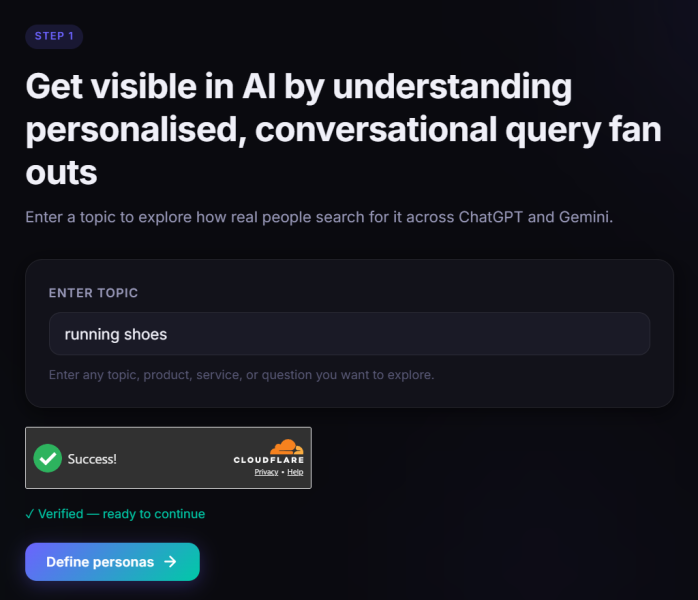
Первый шаг QueryFan для входа в тему (Изображение предоставлено Марком Уильямсом-Куком)
<сильный>Шаг 2. Определите персонажей
<п>Ваши персонажи — это то, как мы собираемся настраивать генерируемые подсказки. Это изменит наше путешествие по пространству токенов, согласовав нас с обучающими данными из миллионов сообществ, сообщений на форумах, веток Reddit и интернет-дискурса, где реальные пользователи задают реальные вопросы с этими личностями.
<п>QueryFan отправляет комбинацию вашего персонажа и темы в LLM, чтобы сгенерировать вопросы, которые персонаж на самом деле задал бы инструменту искусственного интеллекта. Не ключевые слова. Вопросы. Реальные, разговорные, контекстно-зависимые вопросы. Для примера [мужчины-вегана средних лет, который только начал бегать], он выдаст такие вещи, как:
<ул>
Шаг 3: Выбор LLM и дополнительное повышение квалификации
<п>Ветка бесед с ИИ. Тот, кто спрашивает о веганских кроссовках, задаст дополнительные вопросы: о стоимости, о брендах, о предотвращении травм. QueryFan передает сгенерированные запросы через API-интерфейс TooAsked, чтобы зафиксировать ближайшие к каждому из них дополнительные вопросы. Данные «Люди также спрашивают» являются подходящим инструментом здесь, поскольку они созданы для моделирования близости вопросов, а это именно то, что вам нужно, когда вы пытаетесь предсказать, как пойдет разговор дальше.
Например, поиск в Великобритании по запросу «кроссовки для бега»; появлялись дополнительные вопросы о конкретных брендах, вопросы о том, как выбрать обувь, и даже общие медицинские вопросы.
<п>
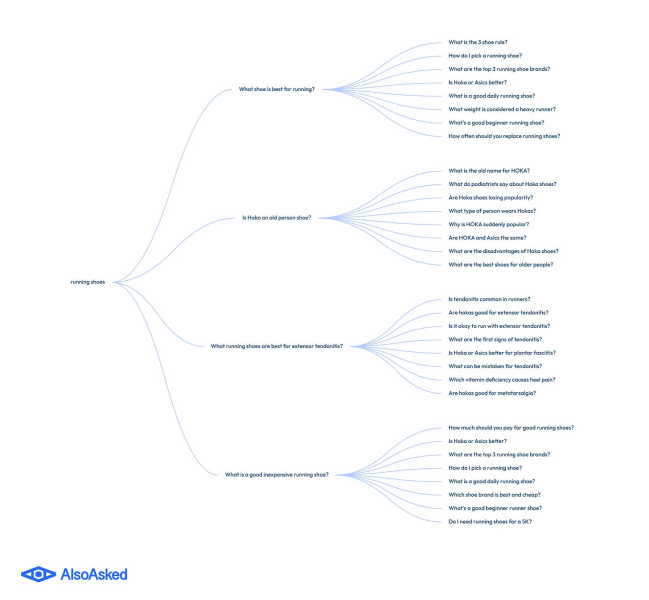
Также дерево вопросов для “кроссовок” показаны вопросы о ближайшем намерении (Изображение предоставлено Марком Уильямсом-Куком) <п>Вы также можете выбрать, хотите ли вы использовать ChatGPT, Gemini или оба. Каждый LLM обрабатывает и распределяет запросы немного по-своему, поэтому, если вы оптимизируете конкретную платформу, лучше всего получать данные оттуда.
<п>
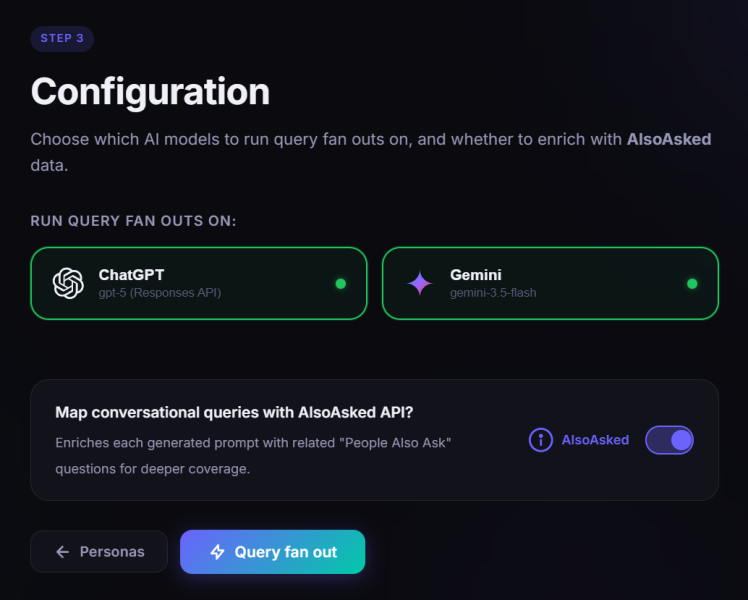
Экран конфигурации QueryFan (Изображение предоставлено Марком Уильямсом-Куком)
Шаг 4: Разветвление запроса
QueryFan отправляет расширенный список подсказок в GPT-5 с включенным веб-поиском (через API ответов OpenAI) и в Gemini с активным заземлением поиска Google (через API Gemini Grounding). Обе модели, когда решают, что для запроса требуется актуальная информация, незаметно выполняют фактический поиск в Google.
Этот процесс фиксирует разветвленные запросы, поскольку оба API, что весьма полезно, прозрачны в отношении того, что они ищут. API Gemini возвращает массив webSearchQueries в поле groundingMetadata каждого обоснованного ответа. API ответов OpenAI регистрирует фактические поисковые запросы в выходных данных web_search_call. QueryFan собирает оба значения.
. <п>В результате получается таблица: индивидуальные подсказки и реальные поисковые запросы Google, которые выдает ИИ. Не то, что напечатал ваш клиент. Что ИИ искал от их имени. Это ваши новые цели SEO, и до сих пор не было бесплатного инструмента, который бы их масштабировал.
Обоснованный вопрос: не каждая подсказка вызывает поиск
<стр>Короткое, но важное предостережение, прежде чем вы побежите классифицировать все как возможности для SEO. <блоковая цитата>
Для примера: подсказка “Что делают эритроциты?” не запускает поиск. Причина в том, что существует очень крутая кривая того, какие токены появятся в следующий раз. Среди миллиардов обучающих документов ответ остается очень стабильным, поэтому “in-model” ответ может быть сгенерирован с уверенностью.
<п>На противоположном конце шкалы находится подсказка типа «Что произошло сегодня в новостях?” вызовет поиск в Интернете. Будет очень плоская кривая «что за токены следующие?», ” поскольку нет “стабильного” ответ в рамках обучающих данных; оно всегда меняется, для этого нужны живые данные. Это еще одна версия концепции «запрос заслуживает свежести» (QDF), которую оптимизаторы используют уже много лет.
<стр>Если вас интересует заземление, Дэн Петрович проделал отличную работу в этой области и даже выпустил обученные модели на Hugging Face, позволяющие прогнозировать, будут ли запросы заземлены, когда они достигнут порога достоверности. <п>
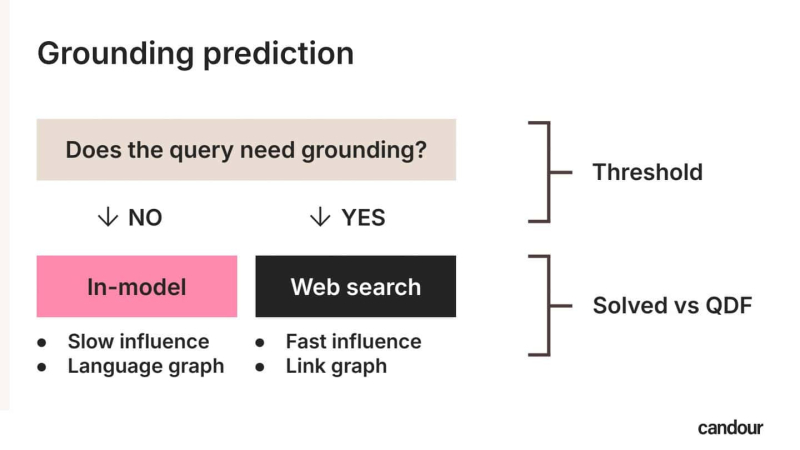
Ответы в модели меняются очень медленно (Изображение предоставлено Марком Уильямсом-Куком)
QueryFan показывает, какие запросы запускают поиск, а какие нет. Только обоснованные (те, которые фактически вызвали поиск в Google) можно использовать с помощью SEO. Ответы в модели на данный момент в значительной степени вне вашей досягаемости. Вам нужно будет повлиять на данные обучения, чтобы переместить стрелку туда, а это совершенно другой проект с гораздо более длительным горизонтом.
<сильный>Что вы делаете с результатами
Теперь у вас есть список реальных поисковых запросов, которые инструменты ИИ запускают при ответе на вопросы от ваших конкретных людей. Запустите стандартный анализ пробелов:
<ул>
Первые две категории являются диагностическими. Третий — ваш список действий.
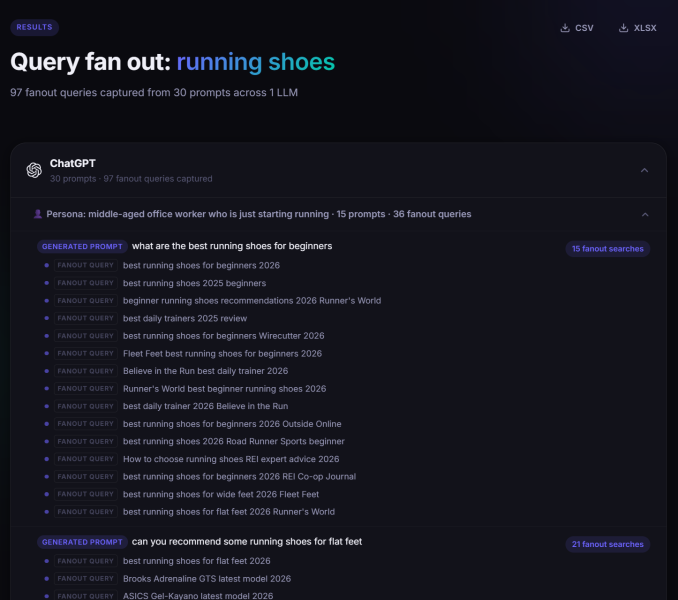
Пример результатов с QueryFan.com (Изображение предоставлено Марком Уильямсом-Куком)
<п>Одно важное отличие от традиционного SEO: ваш собственный рейтинг — не единственный путь к видимости ИИ. LLM сканируют 10, 20, а иногда и 50 лучших результатов на предмет обоснованного запроса и синтезируют их. Рейтинг доверенного сайта отзывов на позиции 3 — это законный путь к появлению в ответе, сгенерированном ИИ, даже если ваш собственный домен никогда не попадает на первую страницу. Обзор продукта на авторитетном специализированном сайте, упоминание в обзорной статье, появление в соответствующем контенте сообщества — все это имеет значение.
Видимость LLM — это фокус на нескольких сайтах. Это означает, что анализ пробелов имеет два результата: контент для создания на вашем собственном сайте и места размещения для заработка на сайтах других людей.
<сильный>Изюминка
<п>Вернитесь к графику цитирования на Reddit. Тот, который упал со скалы, когда Google изменил один параметр API. Полностью независимая компания, отслеживающая поведение искусственного интеллекта, отслеживала поведение поискового API, который она не контролировала и, вероятно, даже не знала о его существовании.
Такова форма зависимости. И это подразумевает не то, что SEO мертво; это почти наоборот. SEO теперь работает с одним дополнительным шагом: вместо оптимизации для человеческого запроса вам необходимо оптимизировать запрос, переведенный ИИ, который происходит между человеком и Google.
QueryFan дает вам возможность увидеть, что на самом деле дает этот перевод. Ваш список ключевых слов показывает, что люди вводят в строку поиска. QueryFan сообщает вам, что ChatGPT и Gemini искали от их имени, в фоновом режиме, и никто не просит их объявить об этом.
Это разные списки. Разрыв между ними не является незначительным уточнением вашей контент-стратегии. Это та часть поиска ИИ, которую никто не измерял, потому что ни у кого не было бесплатного инструмента для ее измерения.
Раскрытие информации: автор является создателем Queryfan.
<ул>
Этот пост был первоначально опубликован на сайте Mark Williams-Cook Substack.


