
<стр>Раскройте секреты видимости ИИ, чтобы адаптировать свой веб-сайт к будущим тенденциям поиска и улучшить технические методы SEO.
Спонсором этого поста является JetOctopus. Мнения, выраженные в этой статье, принадлежат спонсору.
<стр>Как мне оптимизировать свой сайт для ChatGPT и Perplexity, а не только для Google? <стр>Как мне узнать, действительно ли боты ИИ сканируют мой сайт? <стр>Как должна измениться моя техническая стратегия SEO для AI Search? <п>Значительная часть поисковых показов вашего сайта в 2026 году будет генерироваться машинами, проводящими исследования от имени людей.
Эти машины не заботятся о рейтинге ваших ключевых слов. Их волнует, есть ли у вас:
<ул>
Это не предположения. Это то, что данные журналов наших серверов на сотнях корпоративных веб-сайтов постоянно показывают нам с середины 2025 года.
В этом руководстве:
- 1. Что на самом деле происходит на вашем сайте
- 2. Как убедиться, что ChatGPT, Perplexity &amp;amp;amp;amp;amp;amp;amp;amp; LLM могут получить доступ к вашему контенту
- 3. Технический аудит: с чего начать
- 4. Новый ключевой показатель эффективности: техническая доступность
Что на самом деле происходит на вашем сайте
Мой коллега Стэн отметил в сообщении Slack закономерность: длина запросов росла со скоростью, которая не коррелировала с поведением человека.
Темп роста запросов из 10 слов на 161% по сравнению с прошлым годом не обусловлен пользователями, которые внезапно стали более многословными. Он управляется агентами ИИ, которые быстро разлагают одного пользователя на десятки параллельных подзапросов, этот процесс исследователи теперь называют «разветвлением».
Рост длины запроса в 2025 году
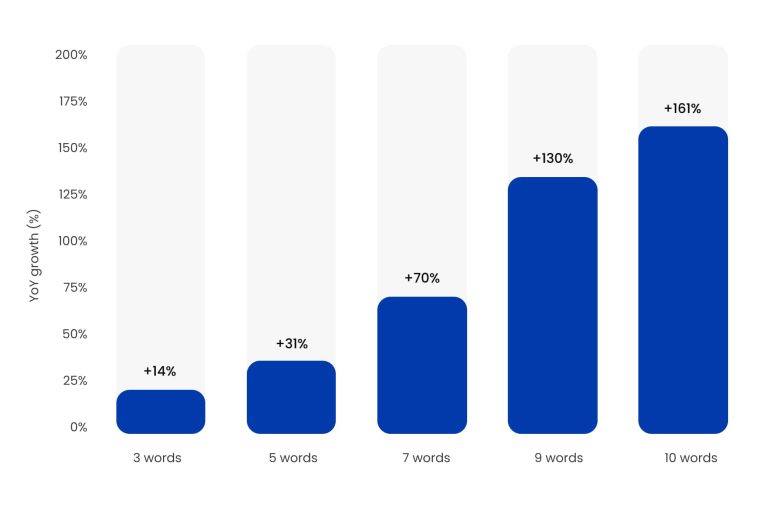
Изображение создано JetOctopus, агрегированные данные GSC по сотням предприятий недвижимость, 2025 г. <п>Градиент – вот что говорит. Человеческое поведение при поиске не позволяет точно оценить это по количеству слов. Машины делают. К октябрю 2025 года запросы длиной более 7 слов достигли почти 1% от общего объема запросов, что примерно в три раза превышает их историческую долю.
Более показательным, чем объем, является CTR. В то время как количество показов по запросам из 10 слов выросло на 161%, рейтинг кликов упал до 2,26% по сравнению с 8–11% в 2023 году.
ИИ читает вашу страницу, извлекает ответ и синтезирует его для пользователя. Ваш сайт никогда не посещают.
Мы называем это «фантомными впечатлениями». Это реальные сигналы того, что ваш контент оценивается в цепочках рассуждений ИИ. Если вы отфильтровываете их из своих отчетов, потому что они не привлекают трафик, вы летите вслепую.
Три бота, посещающие ваш сайт & Их влияние на видимость в поисковой выдаче
<п>Не все сканеры с искусственным интеллектом одинаковы, и рассматривать их как одну категорию — первая ошибка, которую допускает большинство технических оптимизаторов поисковой оптимизации.
Обучающие боты сканируют в широком диапазоне и игнорируют глубину клика. Учебное посещение означает, что ИИ знает, что ваш контент существует, а не то, что пользователи когда-либо его увидят.
Поисковые боты с искусственным интеллектом быстро отключаются после двух-трех кликов с главной страницы и обычно посещают каждую страницу только один раз в месяц.
Пользовательские боты с искусственным интеллектом запускаются, когда реальный человек задает вопрос в ChatGPT, Perplexity или Claude, а ИИ ищет ответ от его имени. Это единственные посещения, которые приводят к реальной видимости ИИ.
<таблица> <тело> <тр>
<тр>
<тр>
<тр>
<п>Ваш сайт может подвергаться интенсивному сканированию обучающими и поисковыми ботами, но при этом полностью отсутствовать в ответах, генерируемых ИИ. Если при анализе журналов вы не сегментируете трафик ИИ-ботов по типам, вы понятия не имеете, какую треть айсберга вы измеряете.
Какие SEO-сигналы уважают LLM?
Robots.txt — ваш основной рычаг.
Большинство основных платформ ИИ (ChatGPT, Claude, Gemini) следуют директивам robots.txt. Perplexity является частичным исключением: PerplexityBot уважает robots.txt, а Perplexity-User, бот, запускаемый пользователем, – нет. Cloudflare подтвердила это в ходе расследования. Большинство сайтов не проверяют свой файл robots.txt с учетом доступа ИИ. Сделай это.
Карты сайта широко поддерживаются. <п>ChatGPT, Claude и PerplexityBot используют карты сайта XML для обнаружения URL-адресов. Следите за точностью.
Сигналы, которые лучше всего сохранять для SEO &amp;amp;amp;amp;amp;amp;amp;amp;amp;amp; Усилия по ранжированию
Приведенные ниже сигналы, похоже, не влияют на видимость ИИ, но по-прежнему являются ключевыми для ранжирования по запросам, которые все еще вызывают традиционные результаты поиска.
Канонические теги и директивы noindex ничего не делают для ботов ИИ.
Сканеры с искусственным интеллектом не создают поисковый индекс, поэтому им не нужны эти метасигналы. Контент, скрытый от Google с помощью noindex, полностью виден сканеру ChatGPT.
LLM.txt ничего не делает.
Наши данные журнала показывают, что основные ИИ-боты не читают этот файл. Не тратьте здесь время.
Рендеринг на JavaScript — критическая слепая зона. <п>Большинство сканеров искусственного интеллекта (ChatGPT, Claude, Perplexity) не обрабатывают JavaScript. Если страницы вашего продукта загружают ключевой контент на стороне клиента, эти агенты читают пустую оболочку. Рендеринг на стороне сервера — единственная архитектура, которая работает универсально. Исключением является Google Gemini, который использует ту же службу веб-рендеринга, что и Googlebot.
Как убедиться, что ChatGPT, Perplexity & LLM могут достичь вашего контента
Поисковые боты с искусственным интеллектом посещают глубокие страницы примерно раз в месяц и резко исчезают после трех кликов с главной страницы. Страницы с наиболее конкретной и ответственной информацией зачастую труднее всего доступны агентам.
Исправление: поднимите наиболее ценные глубокие страницы с помощью внутренних ссылок, гарантируя, что к ним можно будет получить доступ за четыре клика.
<п>Страницы, просматриваемые обучающими ботами, но никогда не достигаемые пользовательскими ботами, являются вашими приоритетными целями. Страницы, которые часто посещают пользовательские боты с искусственным интеллектом, подсказывают вам, что нужно масштабировать: больше контента, охватывающего ту же тематику и глубину.
Оптимизация контента для более длинных и разветвленных запросов
95% запросов, приводящих к цитированию AI, имеют нулевой ежемесячный объем поиска. Это синтетические подзапросы, созданные моделями ИИ. Но они отображаются в GSC: показы, отсутствие кликов, длина запроса, на которую вы никогда не будете ориентироваться добровольно.
Как найти возможности разветвления запросов
<п>Чтобы выявить запросы, которые стоит отслеживать, подключите свой GSC API к JetOctopus (чтобы обойти ограничение пользовательского интерфейса в 1000 строк) и отфильтруйте по: длине запроса более 7 слов, показам менее 50, кликам 0 за последние 3 месяца. Это ваша матрица возможностей для раздачи — точные вопросы, которые агенты ИИ задают о вашем контенте.
Типы подсказок, которые больше всего расходятся
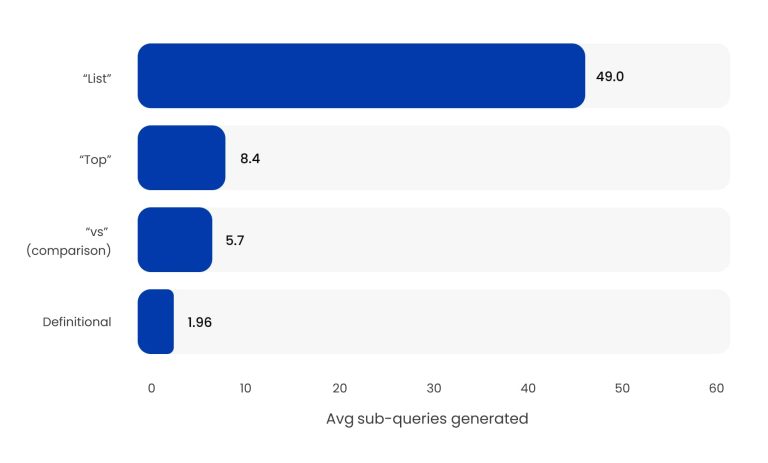
Изображение создано JetOctopus, 2025 г.
Если ваш контент не структурирован по списку ответов и сравнительным запросам, с явным рейтингом, плюсами и минусами и параллельными характеристиками, вы оставляете самую большую площадь разветвления неоптимизированной.
“Обзор продукта” Число запросов о намерениях выросло с 239 в июне 2025 года до более чем 40 000 к сентябрю 2025 года. Увеличение на 16 000 % произошло благодаря тому, что агенты ИИ систематически собирали структурированные данные о мнениях. Если страницам вашего продукта не хватает такой глубины, вы невидимы для этого урожая.
Технический аудит: с чего нужно Начать
Шаг 1. Определите трафик ботов пользователей AI в журналах
Извлеките необработанные журналы сервера (Apache/Nginx) и экспортируйте все строки, содержащие эти пользовательские агенты: OAI-SearchBot и ChatGPT-User, PerplexityBot и Perplexity-User, Claude-SearchBot и Claude-User. Затем вручную сгруппируйте обращения по шаблонам пользовательских агентов и конечным точкам в электронной таблице. Чтобы научиться отличать ботов от пользовательских, вам необходимо вести собственный классификационный список — тот, который часто меняется и не стандартизирован.
В JetOctopus Log Analyser встроена такая сегментация: фильтруйте по типу бота (обучающий, поисковый и пользователь) за несколько кликов и сразу же смотрите, какие страницы посещают пользовательские боты с искусственным интеллектом (ваш видимый для искусственного интеллекта контент, готовый к масштабированию) по сравнению со страницами, которые обучающие боты посещают, но пользовательские боты никогда не достигают (ваши приоритетные цели исправления).
Шаг 2. Проверка технической доступности глубоких страниц
Выберите образец глубоких URL-адресов и проверьте размер полезной нагрузки HTML, убедитесь, что ключевой контент не внедрен через JavaScript, просмотрев необработанный HTML-код, смоделируйте глубину сканирования, подсчитав клики с главной страницы, и проверьте время загрузки в Chrome DevTools или Lighthouse. Также проверьте, скрыт ли важный контент за аккордеонами или тегами “View More” элементы — Для этого требуется выполнение JavaScript, которое боты ИИ полностью пропускают. Для больших сайтов с тысячами глубоких страниц этот подход к выборке не дает многого. Агенты ИИ не щелкают мышью. Если информация появляется только после взаимодействия с пользователем, для этих сканеров она не существует.
Шаг 3. Очистите файл robots.txt
<п>Откройте файл robots.txt и просмотрите все директивы Disallow и Allow для каждого пользовательского агента построчно. Боты ИИ следуют правилам Disallow, поэтому убедитесь, что вы случайно не блокируете важные URL-адреса. Вручную проверьте ключевые URL-адреса, чтобы убедиться, что они не заблокированы. 30-минутный аудит может помешать вам заблокировать нужных вам сканеров или раскрыть контент, который вы предпочитаете не допускать.
Шаг 4. Составьте карту своих фантомных впечатлений
Экспортируйте данные из отчетов GSC Performance, отфильтрованных по показам с нулевым количеством кликов. Из-за ограничения пользовательского интерфейса на 1000 строк вам придется использовать GSC API или экспортировать фрагменты по дате и запросу, а затем объединять наборы данных в электронных таблицах или BigQuery. Также учитывайте частоту запросов: длинные запросы, появляющиеся ежедневно, скорее всего, не будут разветвленными.
<п>Подключите API GSC к JetOctopus, чтобы обойти ограничение на количество строк и автоматически построить матрицу возможностей разветвления — точные вопросы, которые агенты ИИ задают о вашем контенте и готовы действовать.
Шаг 5: Отслеживайте изменения
Настройте повторяющийся процесс экспорта — ежемесячно извлекайте данные GSC и сравнивайте показы с течением времени, повторно запускайте сценарии анализа журналов и сравнивайте активность ботов, отслеживайте основные веб-показатели отдельно в PageSpeed Insights или CrUX. В конечном итоге вам придется объединить несколько источников данных без единого оповещения, что затруднит раннее обнаружение регрессий.
Новый ключевой показатель эффективности: техническая доступность
SEO в 2026 году реструктурируется вокруг одного ограничения: может ли ИИ-агент просканировать, получить доступ и извлечь информацию с вашей 50-тысячной страницы продукта менее чем за 200 миллисекунд?
Если ответ отрицательный, ваш рейтинг, обратные ссылки и качество контента становятся нерелевантными для растущей доли поисковых взаимодействий. Машины ищут. Вопрос в том, как быстро вы сможете увидеть, что происходит на самом деле.
<стр>Начните с журналов. Все остальное следует оттуда.
<таблица> <тело> <тр>
ПРОВЕРЬТЕ ВИДИМОСТЬ МОЕГО ИИ <стр>Авторы изображений
Рекомендуемое изображение: Изображение JetOctopus. Используется с разрешения.


