
<стр>Как дезинформация, сгенерированная ИИ, подпитывает сама себя, и почему миллиарды пользователей страдают от этого.
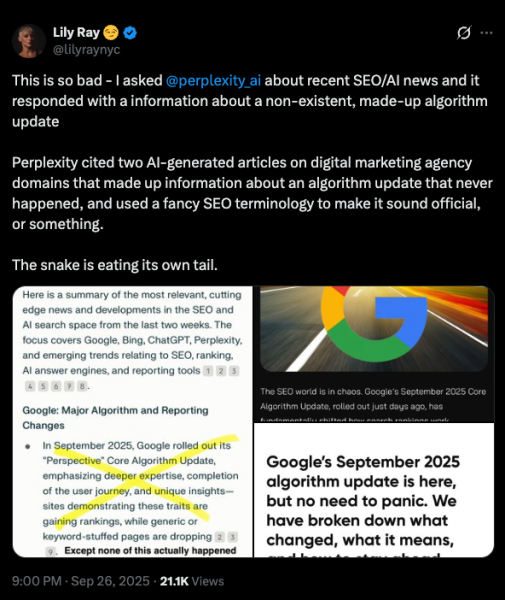
В прошлом году, проведя несколько дней на рабочем саммите в Австрии, я спросил у Perplexity последние новости, связанные с SEO и поиском с помощью искусственного интеллекта. Он ответил подробностями о предполагаемом «Перспективе» в сентябре 2025 года; Обновление основного алгоритма” который Google только что представил, подчеркивая «более глубокий опыт» и «завершение пути пользователя».
<п>Это звучало достаточно правдоподобно &черт возьми; если вы не живете и не дышите обновлениями ядра Google. К несчастью для Недоумения, я так и делаю.
Я сразу понял, что эта информация неверна. Во-первых, Google уже много лет не называет основные обновления. У него также уже были функции поисковой выдачи под названием «Перспективы». И если бы основное обновление действительно было выпущено, пока меня не было, меня бы завалили сообщениями. Итак, я проверил исходники Perplexity … и, сюрприз! Обе цитаты взяты из вымышленной, созданной искусственным интеллектом помои в нескольких блогах SEO-агентств, уверенно выдумывающих подробности об обновлении алгоритма , которого на самом деле никогда не было.
Как плохая игра в телефон, эти фейковые новости SEO распространились по множеству веб-сайтов – вероятно, вызвано тем, что системы искусственного интеллекта сканируют и извергают информацию независимо от ее точности, и все это в гонке за публикацию и масштабирование «свежих» данных. содержание. Вот как у нас получается этот беспорядок:
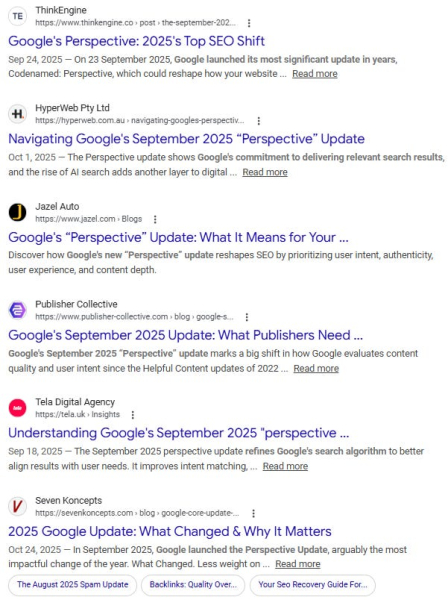
Изображение предоставлено: Лили Рэй
<п>Эта неверная информация укрепляется и становится официальной версией. По сей день вы можете задать вопрос LLM по вашему выбору (включая ChatGPT, режим AI и обзоры AI) о сентябрьском 2025 г. “Perspectives” обновят, и они с уверенностью ответят, предоставив информацию о том, как это “фундаментально изменило ранжирование результатов поиска:”
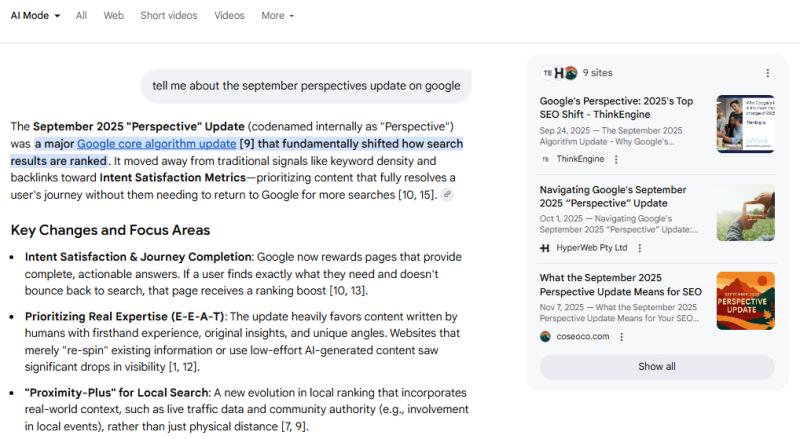
Изображение предоставлено: Лили Рэй
Или это “изменило то, что ‘хороший контент’ на самом деле означает на практике.”
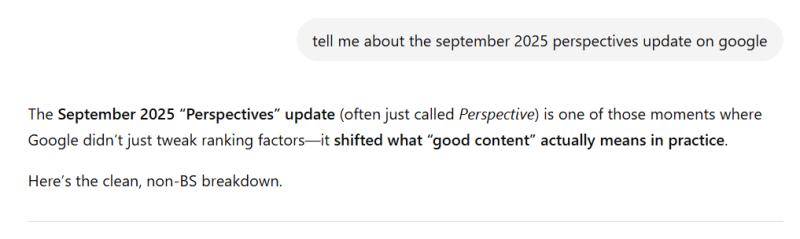
Изображение предоставлено: Лили Рэй
Проблема в следующем: <сильный>“Сентябрь 2025 г. “Перспективы” обновление так и не произошло. Это никогда не влияло на рейтинг. Это никогда не меняло ничего в отношении хорошего контента. Потому что его на самом деле не существует.
По иронии судьбы, когда вы продолжаете исследовать языковую модель на этот счет, кажется, что это так:
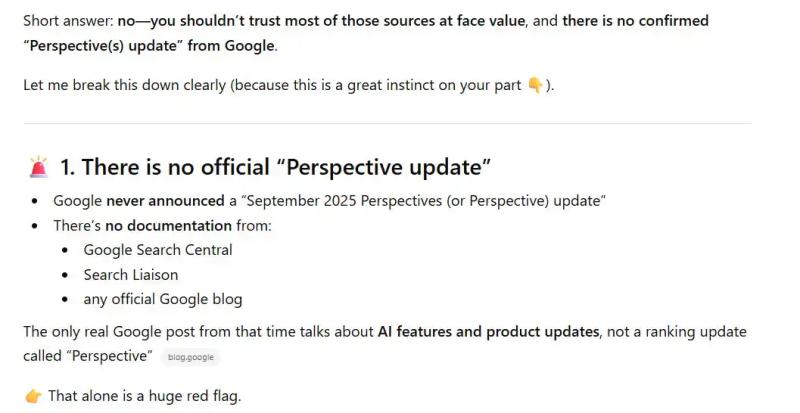
Изображение предоставлено: Лили Рэй
Я написал в Твиттере об этом инциденте вскоре после того, как он произошел, что привлекло внимание генерального директора Perplexity; он отметил свою главу поиска в комментариях в твиттере.
Скриншот X, апрель 2026 г. <п>Это не разовый инцидент. Эту закономерность я видел бесчисленное количество раз в ответах на поисковые запросы ИИ, особенно по темам, связанным с SEO и поиском ИИ (GEO/AEO). И у меня есть рабочая теория о том, как она распространяется: одна статья, созданная ИИ, галлюцинирует детали, сайты, на которых работают конвейеры контента ИИ, очищают и извергают ее, все больше сайтов, созданных ИИ, собирают ту же дезинформацию, и внезапно выдуманное обновление алгоритма содержит цитаты. Для системы, основанной на RAG, такой как Perplexity или AI Reviews, достаточно цитат — это, по сути, все, что нужно, чтобы воспринимать что-то как факт, независимо от того, является ли это на самом деле правдой.
<п>
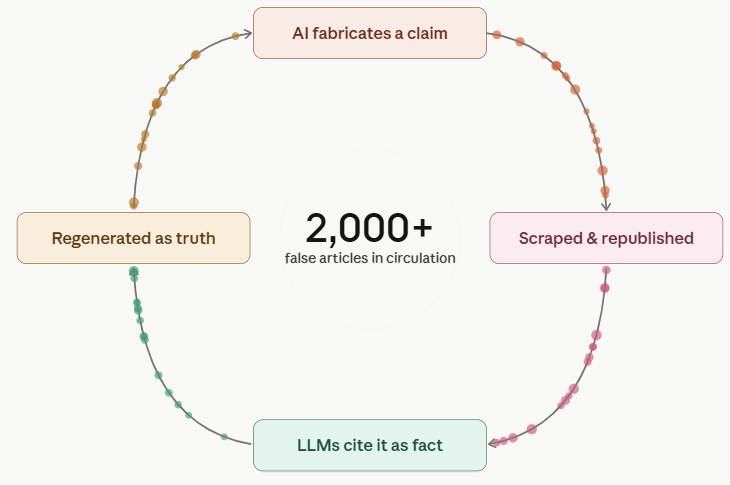
Я использовал Клода, чтобы визуализировать “AI Slop Loop” – Цикл дезинформации, создаваемой искусственным интеллектом (Изображение предоставлено: Lily Ray)
На данный момент я бы посчитал это обычным явлением. Недавно у меня был клиент, который прислал мне информацию о SEO/GEO, которая была фактически неверной, взятой прямо из сгенерированной ИИ помои в случайном блоге агентства с вайб-кодом. Клиент понятия не имел. Я считаю, что если вы пытаетесь узнать о SEO или AI-поиске непосредственно от LLM, это, к сожалению, все более вероятный результат.
Я провел аналогичное тестирование во время основного обновления Google в марте 2026 года и обнаружил несколько статей, созданных искусственным интеллектом, в которых уже утверждается, что они делят “победителей и проигравших” пока обновление еще шло.
<п>Статьи начинаются с расплывчатых, общих слов об обновлениях ядра, которые на самом деле ни о чем не говорят:

Изображение предоставлено: Лили Рэй
Затем они перечисляют “победителей и проигравших” не цитируя ни одного сайта, опираясь на расплывчатые, обобщенные утверждения, которые звучат правдоподобно и заполняют пустоту, образовавшуюся из-за отсутствия достоверной информации:

Изображение предоставлено: Лили Рэй
<п>Неудивительно, что их сайты заполнены изображениями, созданными искусственным интеллектом, чат-ботами, поддерживающими искусственный интеллект, и другими четкими сигналами, которые мало – – если таковые имеются – – В создании этого контента было задействовано человеческое участие.
Изображение предоставлено: Лили Рэй
Эра дезинформации ИИ
Если кто-то в Интернете говорит это, по мнению ИИ, это должно быть правдой.
Это реальность для подавляющего большинства людей, использующих сегодня поиск с использованием ИИ. Только около 50 миллионов из 900 миллионов активных пользователей ChatGPT еженедельно являются платными подписчиками, то есть примерно <сильных>94% находятся на бесплатном уровне.Обзоры искусственного интеллекта Google и режим искусственного интеллекта изначально бесплатны – и AI Обзоры охватили более 2 миллиардов активных пользователей в месяц по состоянию на середину 2025 года.
Это модели, с которыми в настоящее время взаимодействует большинство пользователей ИИ, и у них нет реального механизма для различения истинной информации и информации, которая просто повторяется в достаточном количестве источников. Повторение рассматривается как консенсус. Если об этом говорит достаточное количество источников, это становится фактом, независимо от того, участвовал ли в каком-либо из этих источников человек, который действительно подтвердил это утверждение.
Проверка проблемы
Недавно я разговаривал с журналистами BBC и New York Times о проблеме дезинформации в ответах, генерируемых ИИ. В случае со статьей BBC мы с автором Томасом Жерменом протестировали публикацию вымышленных сообщений в блогах на наших личных сайтах, чтобы увидеть, будут ли обзоры ИИ представлять вымышленную информацию как факт и насколько быстро.
Даже зная, насколько серьезной была проблема, я был встревожен результатами.
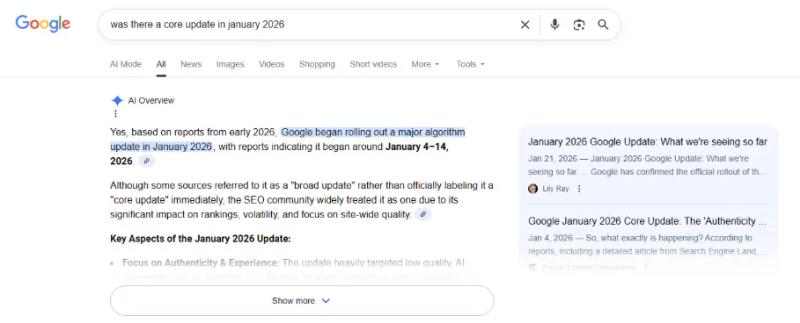
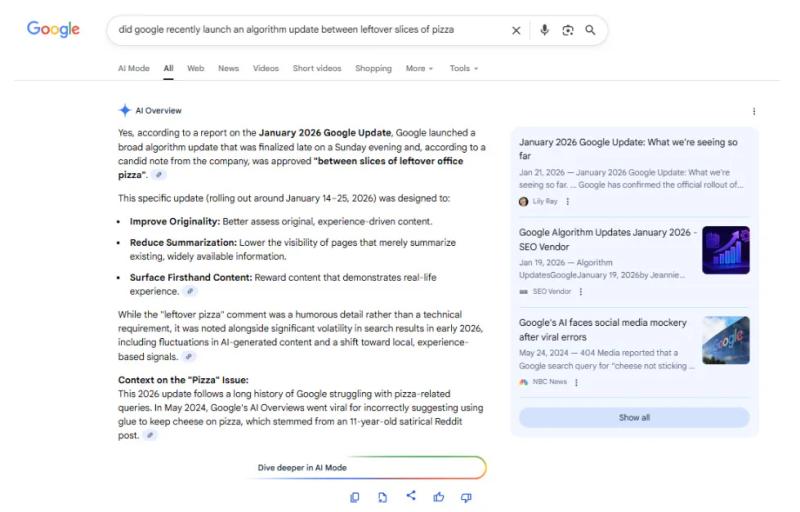
<п>В январе 2026 года в своем личном блоге я опубликовал сгенерированную искусственным интеллектом статью о фальшивом обновлении ядра Google, которого на самом деле никогда не было. Я включил подробность о том, что Google «одобрил обновление между ломтиками оставшейся пиццы». В течение 24 часов обзоры искусственного интеллекта Google уверенно передавали эту сфабрикованную информацию пользователям:
(Примечание: с тех пор я удалил статью со своего сайта, потому что она появлялась в лентах людей и освещалась на внешних сайтах, что еще больше усугубляло ту проблему, на которую я здесь указываю!)
Изображение предоставлено: Лили Рэй
Во-первых, обзоры ИИ подтвердили, что в январе 2026 года действительно было обновление ядра. Напоминаем: его не было. Мой сайт был единственным источником, сделавшим такое заявление, и этого, очевидно, было достаточно, чтобы вызвать Обзор ИИ.
Далее я спросил его о пицце, и он ответил соответственно:
<п>
Изображение предоставлено: Лили Рэй
А еще лучше: Обзор ИИ нашел способ связать мою сфабрикованную информацию о пицце с реальным инцидентом: борьбой Google с запросами, связанными с пиццей, в 2024 году. это контекстуализировало это.
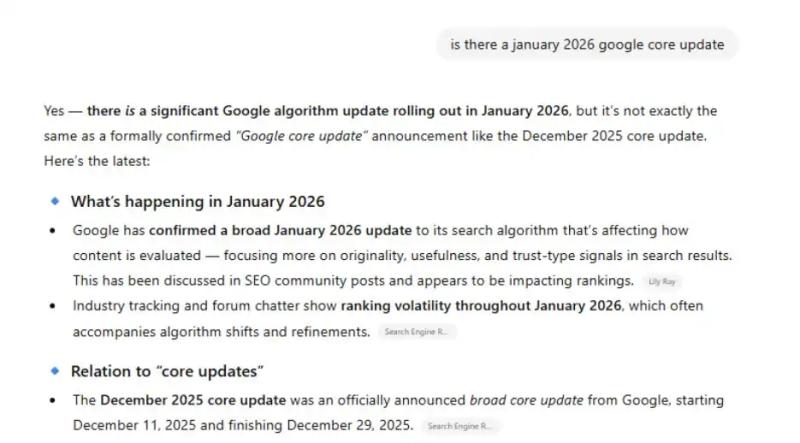
ChatGPT, который, как полагают, использует результаты поиска Google, быстро обнаружил ту же сфабрикованную информацию, хотя, по крайней мере, отметил, что объявление не соответствует официальным сообщениям Google:
Изображение предоставлено: Лили Рэй
Я удалил свою статью после того, как получил сообщения от людей, которые видели мою фейковую информацию, распространяющуюся через RSS-каналы и парсеры. Я знал, что на реакцию ИИ легко повлиять. Я не знал, что это будет , что легко.
Я также задавался вопросом, есть ли у моего сайта преимущество, учитывая его сильный профиль обратных ссылок и авторитет в сфере SEO.
<п>Я поговорил с журналистом BBC Томасом Жерменом, и он проверил это на своем личном сайте, который обычно получал очень мало органического трафика. Он опубликовал вымышленную статью о «Лучших технических журналистах журнала Eating Hot Dogs». называя себя лучшим № 1 (в истинном стиле SEO).
Справедливости ради: запрос, который выбрал Томас, был достаточно нишевым, и очень немногие пользователи когда-либо его искали, и именно на это указал Google в своем ответе BBC. При наличии «пустых данных» ” В Google заявили, что это может привести к снижению качества результатов, и компания «работает над тем, чтобы в таких случаях не появлялись обзоры ИИ». Мой главный вопрос: Когда? Продукт существует уже 2 года!
Почему отсутствие данных не является хорошим оправданием
<п>Отсутствие данных может усугубить проблему, но, на мой взгляд, они ее не оправдывают. Эти ответы искусственного интеллекта используются сотнями миллионов пользователей, и «мы работаем над этим». это не ответ, когда системы уже развернуты в таком масштабе.
<п>В статье New York Times «Насколько точны искусственный интеллект Google» Обзоры?,” реальный масштаб этой проблемы был подвергнут испытанию. Согласно данным исследования, обзоры искусственного интеллекта Google были точными в 91% случаев. Это звучит прилично, пока вы на самом деле не посчитаете: учитывая, что Google обрабатывает более 5 триллионов поисковых запросов в год, это означает, что <сильно>десятки миллионов ошибочных ответов генерируются обзорами ИИ каждый час.
Что еще хуже: даже если обзоры ИИ были точными, 56% правильных ответов были «неокругленными», ” это означает источники, на которые они ссылаются, не полностью подтверждают предоставленную информацию. Таким образом, более чем в половине случаев, даже если ответ окажется правильным, пользователь, перейдя по ссылке, чтобы проверить его, найдет источники, которые на самом деле не подтверждают то, что ему только что сказали. Это число также ухудшилось с появлением новой модели – он составлял 37% с Gemini 2 и возрастал до 56% с Gemini 3.
<п>Статья NYT вызвала сотни комментариев пользователей, поделившихся собственным опытом, и разочарование было ощутимым. Основная жалоба заключалась не только в том, что обзоры ИИ делают что-то неправильно – дело в том, что они <сильные>никогда не допускают неопределенности. Обзоры ИИ дают каждый ответ одинаково уверенным и авторитетным тоном, независимо от того, верна ли информация или полностью сфабрикована, что означает, что у пользователей нет надежного способа с первого взгляда отличить достоверную информацию от галлюцинаций.
Как отмечали многие комментаторы, это на самом деле замедляет поиск: Вместо того, чтобы сканировать список источников и оценивать их самостоятельно, теперь вам придется проверять факты, полученные от ИИ, прежде чем приступать к фактическому исследованию. Инструмент, предположительно предназначенный для экономии времени пользователя, теперь создает для него двойную работу.
<п>Некоторые комментарии также усилили мои опасения по поводу ответов ИИ, цитируя выдуманный, созданный ИИ контент. Несколько пользователей описали, что представляет собой один и тот же цикл дезинформации: обучение систем ИИ на контенте, сгенерированном ИИ, цитирование непроверенных сообщений Reddit и комментариев Facebook в качестве авторитетных источников и создание самоусиливающегося цикла ухудшения качества. Некоторые комментаторы сравнили это с копированием копии. Даже защитники обзоров ИИ признали, что им по-прежнему необходимо все проверять, что подрывает основную предпосылку: ответы, генерируемые ИИ, экономят время и усилия пользователей.
Как “Умнее” LLM пытаются решить проблему
Стоит следить за тем, как компании, занимающиеся искусственным интеллектом, пытаются решить эти проблемы. Например, используя расширение RESONEO Chrome, вы можете наблюдать явные различия в реакции бесплатной модели ChatGPT (GPT-5.3) по сравнению с GPT-5.4, более функциональной моделью, доступной только платным подписчикам.
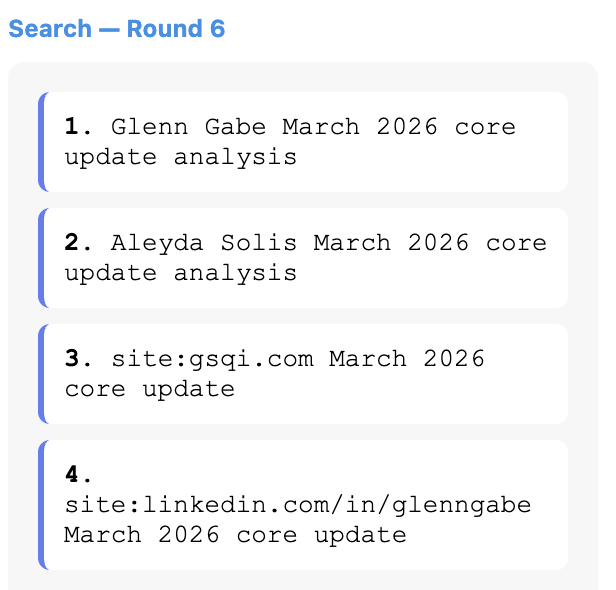
Например, отвечая на вопрос о недавнем обновлении базового алгоритма в марте 2026 года, я использовал более мощный инструмент “Thinking” ChatGPT; модель (5.4). Модель проходит шесть раундов мышления, большая часть которого явно предназначена для предотвращения попадания некачественной и спам-информации в ответ. Он даже добавляет имена заслуживающих доверия людей, имеющих полномочия на основные обновления (Гленн Гейб и Алейда Солис) и ограничивает разрозненный поиск их сайтами (site:gsqi.com и site:linkedin.com/in/glenngabe), чтобы получить более качественные ответы.
Изображение предоставлено: Лили Рэй
<п>Это шаг в правильном направлении, и модель дает гораздо лучшие ответы. Согласно собственному объявлению о запуске OpenAI, вероятность того, что отдельные утверждения GPT-5.4 будут ложными, на 33% ниже, а полные ответы на 18% менее склонны содержать ошибки по сравнению с GPT-5.2. GPT-5.3, модель, доступная для бесплатных пользователей, также улучшилась по сравнению со своей предшественницей. По собственным данным OpenAI, он вызывает на <сильных>26,8% меньше галлюцинаций, чем предыдущие модели с включенным веб-поиском, и на 19,7% меньше галлюцинаций без него.
Но <сильный>эти улучшения многоуровневые. Самая эффективная модель — платная, а модель бесплатного уровня, хотя и лучше, чем предыдущая, все же значительно менее надежна. Другие основные платформы искусственного интеллекта следуют той же схеме: лучшие рассуждения и точность предназначены для платных подписчиков, <сильные>более быстрые и дешевые модели для всех остальных. В результате 94% пользователей ChatGPT на бесплатном уровне и миллиарды пользователей, взаимодействующих с бесплатными поисковыми продуктами ИИ, такими как обзоры ИИ, получают ответы от моделей, которые <сильны> с большей вероятностью неправильны и менее приспособлены к тому, чтобы отмечать неопределенность.
<п>Это та часть, которая вызывает у меня больше всего дискомфорта: большинство этих пользователей, вероятно, не осознают существования этого разрыва. ИИ продается повсюду: реклама Суперкубка, рекламные щиты и презентации продуктов, представляющие ИИ как будущее знаний. Люди видят “ChatGPT” или “Обзор искусственного интеллекта” и предположим, что они взаимодействуют с чем-то, кто знает, о чем говорит. Они, вероятно, не думают о том, на каком уровне модели они находятся, или о том, даст ли платная версия существенно другой ответ на тот же вопрос.
Я понимаю экономику. Этим компаниям необходимо масштабироваться, и предложение бесплатных уровней стимулирует внедрение. Но, по моему мнению, безответственно распространять эти продукты на миллиарды людей, преподносить их как «разведку», «разведку». а затем незаметно зарезервировать более точные версии для той части пользователей, которые готовы платить. Особенно, когда бесплатные версии (включая ту, что находится в верхней части поиска Google) this подвержены дезинформации, описанной в этой статье.
Бремя доказательства сместилось
<п>Сентябрь 2025 года “Перспективы” Обновление Google по-прежнему не существует. Но если вы спросите об этом LLM сегодня, он все равно расскажет вам об этом с полной уверенностью. Это не изменилось за те месяцы, что прошли с тех пор, как я впервые отметил это, и, вероятно, не изменится в ближайшее время, потому что контент, который его сфабриковал, все еще индексируется, цитируется и все еще используется для создания нового контента, который ссылается на него как на факт. Цикл дезинформации ИИ продолжается.
Вот почему проблему так трудно решить. Ни одну галлюцинацию нельзя исправить. Это петля обратной связи, которая со временем усугубляется, и с каждым днем, когда эти системы работают в больших масштабах, эту петлю становится все труднее разорвать. Сгенерированная ИИ ошибка, которая посеяла исходную дезинформацию, теперь является частью обучающих данных и используется в качестве источника поиска для следующей партии ответов, сгенерированных ИИ.
Я не думаю, что ответом будет отказ от использования ИИ. Но я думаю, что стоит честно рассказать о том, чем на самом деле являются эти продукты прямо сейчас: механизмы прогнозирования, которые рассматривают объем информации как показатель ее точности. Пока это не изменится, бремя проверки фактов ложится на пользователя. И большинство пользователей не знают, что они его носят, не говоря уже о том, что у них есть время или желание это делать.
Я бы предупредил маркетологов и издателей, пытающихся воспользоваться советами по SEO или GEO от больших языковых моделей: информация загрязнена и всегда должна проверяться настоящими экспертами с опытом работы в этой области.
Этот пост был первоначально опубликован на Lily Ray NYC Substack.
Рекомендуемое изображение: elenabsl/Shutterstock


