
<стр>Новые данные из 3981 домена по 115 запросам, 14 странам и 4 поисковым системам с искусственным интеллектом.
Повышайте свои навыки с помощью еженедельной экспертной информации Growth Memo. Подпишитесь бесплатно!
<п>Когда ИИ отвечает на вопрос, используя ваш контент, он обычно цитирует вас со ссылкой на источник. Чего он не делает в 62% случаев, так это произносит свое имя. Ссылка есть. Упоминания бренда нет. Это то, что я называю призрачной цитатой: ИИ, использующий ваш контент, не упоминает вас в ответе.
На этой неделе я делюсь:
<ул>
<стр>Примечание от Кевина: Я большой поклонник HubSpot Маркетинг против зерна. Еще в 2023 году Киран, один из соведущих, участвовал в моем подкасте Tech Bound. Теперь они запустили информационный бюллетень с умными экспериментами, свежими взглядами и практическими уроками о том, что работает прямо сейчас. Итак, я решил дружески поприветствовать: Посмотрите.
Этот анализ основан на 3981 домене по 115 запросам, 14 странам и четырем поисковым системам искусственного интеллекта (ChatGPT, Обзоры Google AI, Gemini, AI Mode) с использованием данных Semrush AI Toolkit. Каждое появление помечается тегом “цитируется” (присутствует ссылка на источник) и/или “упоминается” (название бренда указано в тексте ответа). Разрыв между этими двумя состояниями и есть проблема призрачного цитирования.
<сильный>1. 62% цитирований LLM вашего бренда функционально невидимы
Большинство брендов считают, что быть упомянутым означает быть увиденным. Данные говорят об обратном.
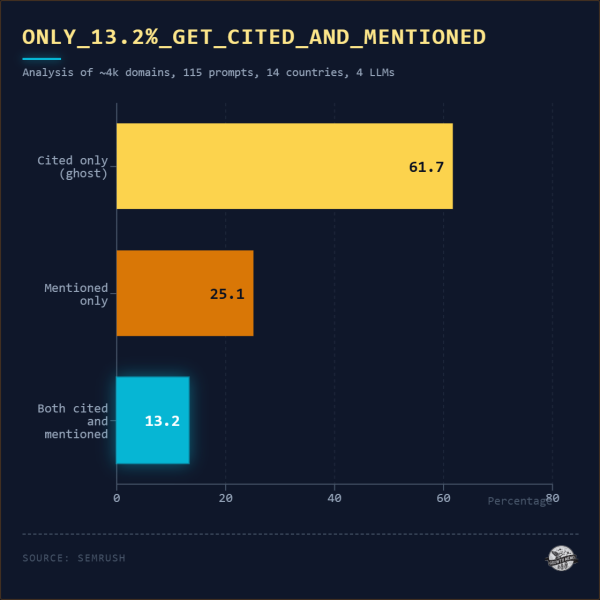
Изображение предоставлено: Кевин Индиг
74,9% доменов были процитированы и 38,3% упомянуты. 61,7% цитат являются ложными: домен получает ссылку на источник, но имя не распознается в тексте ответа.
Только 13,2% упоминаний конвертируются как в цитирование, так и в упоминание. Ни один домен не был упомянут, а вообще не упомянут, или наоборот.
<сильный>2. Каждый LLM ведет себя по-разному
<п>Четыре механизма искусственного интеллекта обрабатывают цитаты и упоминания принципиально по-разному:
<ул>
<п>Для брендов это означает, что видимость Gemini и видимость ChatGPT — не одно и то же. (Этот набор данных явно свидетельствует о том, что между цитатами/упоминаниями ChatGPT и цитатами/упоминаниями Gemini для одних и тех же запросов не было большого совпадения.) Оптимизация для одного не помогает с другим. Не существует единого «метрика видимости ИИ». Существует как минимум 4 различные поведенческие системы, работающие параллельно.
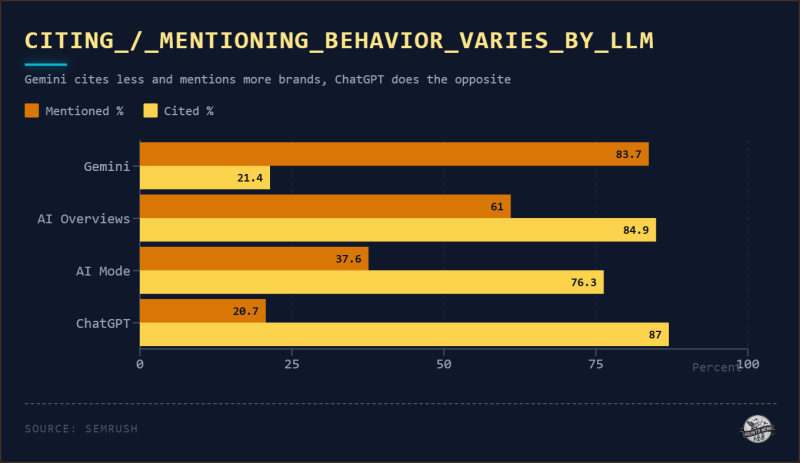
Изображение предоставлено: Кевин Индиг
<сильный>3. Сильные бренды упоминаются в тексте
Ясная закономерность проявляется среди доменов, появляющихся три или более раз: агрегаторы контента и академические источники цитируются неоднократно, но почти никогда не упоминаются.
<ул>
<п>Потребительские бренды с сильной известностью упоминаются в результатах почти на 100%. ИИ не чувствует необходимости цитировать. Вместо этого в нем прямо упоминаются потребительские бренды. Он знает, что данные о брендах откуда-то взяты, но не чувствует необходимости явно сообщать об этом пользователям. Для издателей, ценностным предложением которых является информационный авторитет, это структурная проблема.
*Коэффициент упоминаний выше 100 % означает, что бренд упоминается в тексте ответа, даже если он не упоминается в качестве ссылки на источник – движок ссылается на бренд по имени, не привязываясь к нему. Если значения в этом наборе данных превышают 100%, подумайте о том, чтобы вас цитировали 10 раз и упоминали 10 раз как = 100%. Если бренд упоминается 12 раз и цитируется 10 раз, это 120%.
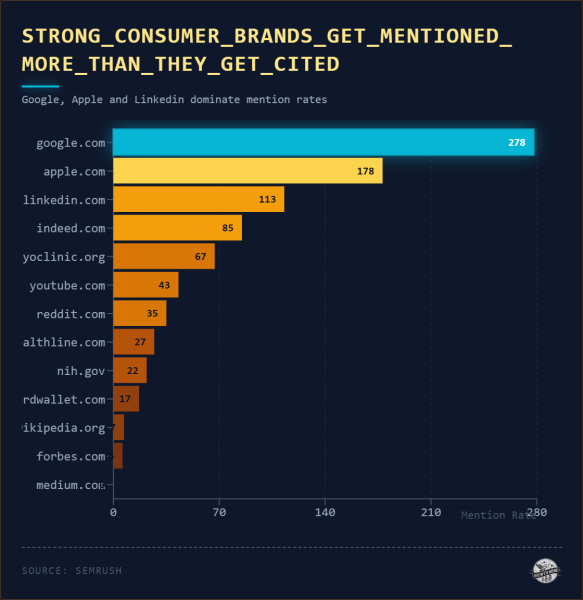
Изображение предоставлено: Кевин Индиг
<сильный>4. LLM расходятся во мнениях по поводу одного и того же бренда в 22% случаев
454 комбинации приглашения+домена были протестированы на нескольких движках. В 22% этих результатов (всего 100) участники LLM не согласились с тем, стоит ли упоминать бренд:
<ул>
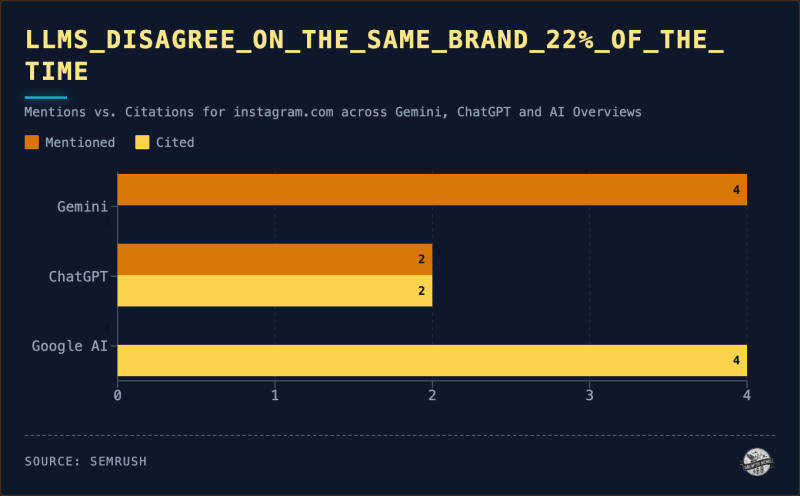
Изображение предоставлено: Кевин Индиг
<п>Тот же бренд, тот же запрос, но разные механизмы и разные результаты. Вот что важно для измерения: бренд может выглядеть “видимым” в данных одного движка и при этом полностью анонимен в другом. Совокупные показатели видимости ИИ маскируют это расхождение.
<сильный>5. Уровень упоминаемости бренда в тексте зависит от географии
С учетом LLM различия в уровне упоминаний на уровне страны значимы:
<ул> <ли>В Индии и Швеции наблюдаются самые высокие показатели упоминаний (50%), что говорит о том, что на этих рынках больше диалоговых запросов или запросов, ориентированных на бренд.
*Примечание: в наборе данных используются локализованные подсказки, подтвержденные Semrush, поэтому язык не является проблемой.
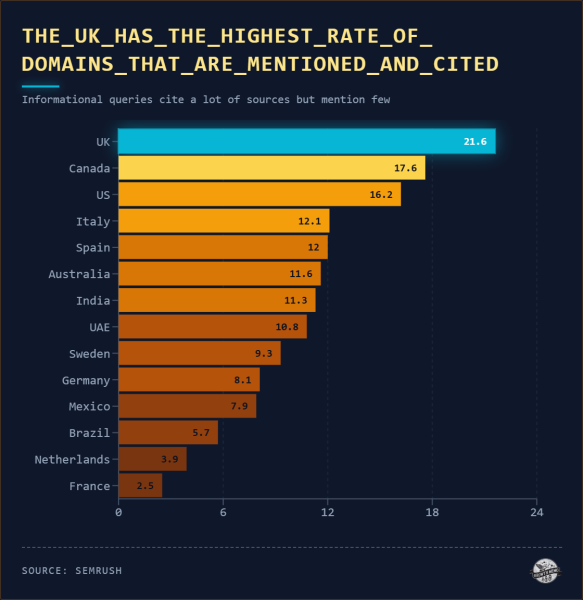
Изображение предоставлено: Кевин Индиг
Цитирование и имя — это не одно и то же, и требуют другого подхода
Из этого анализа мне больше всего запомнились четыре вывода о брендах и их контент-стратегиях:
<п><сильный>1. Упоминание означает, что ИИ использует ваш контент. Упоминание означает, что он называет вас. Мы еще недостаточно знаем о последствиях упоминаний и цитат, но можем с уверенностью сказать, что существует система, которая решает, когда вас цитируют, а когда упоминают.
<п><сильный>2. Ваша стратегия должна быть ориентирована на LLM. Стратегия, ориентированная на Gemini, отличается от стратегии, ориентированной на ChatGPT. Любой отчет о видимости ИИ, объединяемый по LLM, вводит в заблуждение.
<п><сильный>3. Сравнительный контент получает названия брендов. Информационный контент подается в машину анонимно. Если целью является упоминание бренда, а не просто цитирование, сосредоточьте свою контент-стратегию на оценке, сравнении и рекомендациях.
<сильный>4. Формат подсказки имеет значение. Бренды должны указать не только, в каких темах они хотят появиться, но и конкретно, какие фразовые шаблоны вызывают упоминания, а не призрачные цитаты. Короткие разговорные запросы и длинные структурированные запросы ведут себя как разные продукты.
<сильный>Методология
<стр>Источник данных: Semrush AI Toolkit: 3981 появление домена по 115 запросам, 14 странам и четырем поисковым системам искусственного интеллекта (ChatGPT, Обзоры Google AI, Gemini, Google).
Каждая строка в наборе данных представляет домен, который появился в ответе ИИ. Каждое появление помечается тегом “цитируется” (домен отображается как ссылка на источник) и/или “упоминается” (название бренда указано в тексте ответа). Разрыв между этими двумя состояниями — это то, что в этом анализе называется призрачной цитатой: ИИ использовал ваш контент, но не произносил ваше имя.


