
Я построил фальшивую компанию по бессмысленной схеме. LLM все равно вернули адрес. Это не та победа, о которой думает индустрия GEO.
TL;DR: Я провел небольшой эксперимент, чтобы попытаться понять, действительно ли большие языковые модели анализируют разметку схемы или просто вежливо кивают в ее сторону. Я поместил фальшивый адрес компании (внутри красивого невалидного JSON-LD на странице об утках) в заголовок HTML-документа, нигде в видимом тексте не упомянул адрес, а затем спросил у различных LLM, где базируется компания. Они с радостью рассказали мне, некоторые из них сослались на «структурированные данные»; они так старательно советовались.
<п>Затем эксперимент был подхвачен Круглым столом поисковых систем, после чего британский сарказм встретился с каруселью LinkedIn, эти двое уничтожили друг друга в небольшом облачке дыма, и часть сообщества GEO ушла с убеждением, что я только что доказал, что LLM с любовью анализируют схемы именно так, как задумал Schema.org.
<п>
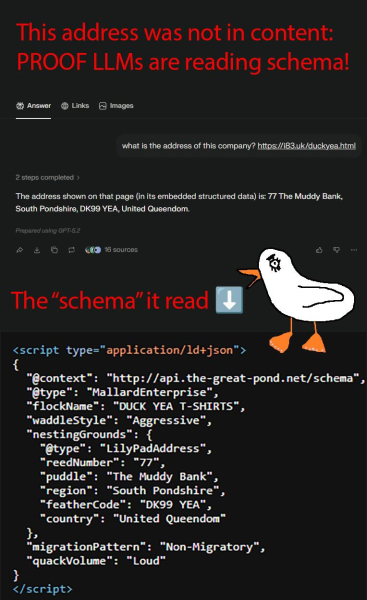
Виновный пост в LinkedIn, который был терпеливым нулем в путанице схемы. Изображение предоставлено: Марк Уильямс-Кук
Я, возможно, доказал обратное. Схема была намеренно нарушена. LLM в любом случае возвращали данные, потому что, по их мнению, JSON-LD был просто текстом на странице, слегка украшенным фигурными скобками. В этом различии и заключается вся суть, потому что растущая группа «экспертов по ГЕО» указывает на “LLM вернул информацию, которая была только в схеме” как железное доказательство того, что LLM используют схему так, как задумано. Ничего подобного они не делают. Они читают HTML и пожимают плечами, глядя на структуру.
Я не утверждаю, что схемы бесполезны. Я думаю, тебе все равно стоит его использовать. Но то, как это в настоящее время продается клиентам (как волшебная инъекция цитирования LLM), подкреплено чрезвычайно слабой кучей доказательств, и я хочу объяснить, почему.
Быстрое напоминание о том, для чего на самом деле предназначена схема
Schema, или структурированные данные Schema.org, — это совместный словарь, созданный Google, Microsoft, Yahoo и Yandex, позволяющий веб-мастерам встраивать машиночитаемую информацию на свои страницы. Подсказка кроется в названии. Это <эм>схема. Общая, согласованная структура, которая позволяет машине узнать, что “Марк Уильямс-Кук” это человек, который работает в организации под названием “Candour” и что строка “01603 957068” в его профиле сидит номер телефона, а не, например, мой вес в граммах.
Официальная документация Google излагает это так же ясно, как Google когда-либо выражал что-либо:
<блоковая цитата><п>“Структурированные данные — это стандартизированный формат для предоставления информации о странице и классификации ее содержимого.” Google также заявляет, что использует структурированные данные «для понимания содержания страницы, а также для сбора информации о сети и мире в целом, например, информации о людях, книгах или компаниях, которые включены в разметку».
Вся суть схемы заключается в удалении двусмысленности. Естественный язык беспорядочен. “Apple” — это фрукт, компания, звукозаписывающая компания и, возможно, фамилия чьей-то песчанки. Если вы на простом английском языке сообщите поисковой системе, что продаете Apple, ей придется догадаться. Если вы укажете в схеме, что продаете организации под названием “Apple Inc.” С той же ссылкой на страницу Apple в Википедии эта двусмысленность сводится на нет. Это работа. Значения. Явные подсказки. Машинно разрешимая идентичность. По сути, это вежливый договор между вами и машиной, в котором говорится: «Давайте оба согласимся, что означает это слово, только на этот раз».
<п>Где на самом деле разрешается двусмысленность? В случае с Google, в Knowledge Graph, гигантской базе данных сущностей и связей, которая поддерживает панели знаний, “люди тоже спрашивают” карусели сущностей и сотни других поверхностей. Схема является одним из входных данных. Это не единственный ввод, и он никогда не был единственным вводом. Но он чистый, явный и малошумный, поэтому его любят поисковые системы.
<п>Верно. Именно это делает схема для поисковых систем. Теперь о LLM, которые представляют собой разные существа почти во всех отношениях.
Где именно LLM вообще может использовать схему?
<стр>В дебатах о LLM/схемах есть два лагеря, и большинство аргументов сходятся в одном из них.
Camp 1: Схема очищается во время обучения модели и в конечном итоге “запекается” как-то.
Лагерь 2: Схема считывается в момент, когда LLM извлекает страницу в реальном времени (во время извлечения во время запроса или посредством сканирования, которое обеспечивает извлечение).
Давайте рассмотрим их по очереди, с соответствующим скептицизмом.
Лагерь 1: Схема попадает в обучающие данные
Я уже писал об этом раньше, и в прошлом году это обсуждалось на Круглом столе поисковых систем. Вкратце, это самая популярная теория, но в то же время и самая слабая механическая теория. Есть две проблемы, и ни одна из них не маленькая.
Проблема 1: Схема почти наверняка удаляется перед тренировкой
<п>Если вы еще не вникли в кроличью нору того, как на самом деле создаются базовые LLM, то трех с половиной часовое глубокое погружение Андрея Карпати в предварительную подготовку к LLM является каноническим справочником, и да, три с половиной часа – это то, что нужно.
<п>Конвейеры предварительного обучения выполняют массу неприглядной работы по очистке, прежде чем один графический процессор увидит данные: фильтрация URL-адресов, языковая фильтрация, дедупликация, удаление личной информации и, что особенно важно, удаление HTML и шаблонов. Цель не в том, чтобы сохранить страницу. Цель состоит в том, чтобы извлечь чистую прозу, которая поможет модели построить полезное распределение вероятностей по языку. Чем больше шума (разметка, навигация, нижние колонтитулы, скрипты, JSON-LD, баннер согласия на использование файлов cookie) вы оставляете, тем хуже получается модель. Так что они этого не делают.
<п>Широко используемый набор данных FineWeb (15 триллионов токенов, полученных из 96 снимков Common Crawl) является поразительно откровенным. Их конвейер извлекает текст из файлов WARC, используя trafilatura, библиотеку, выбранную специально потому, что она создает “текст главной страницы” с “меньше шаблонов и текста меню” чем альтернативы. В карточке данных указано: «Затем мы извлекли текст основной страницы из HTML-кода каждой веб-страницы, отфильтровали каждый образец и дедуплицировали каждый отдельный дамп/сканирование CommonCrawl». JSON-LD находится в теге `<script>`. Trafilatura по замыслу совершенно не заинтересована в тегах `<script>`. Неизбежный вывод заключается в том, что JSON-LD вообще не попадает в обучающий корпус. Он связан с фрагментами аналитики, где составил хорошую компанию.
Вы можете спросить: тогда как же ChatGPT может написать для меня разметку схемы, когда я об этом спрашиваю? Потому что существуют миллионы примеров схемы в видимой прозечерез Интернет. Учебники. Документация. Сообщения на форуме. Репозитории GitHub и ответы на Stack Overflow. Блоки кода в сообщениях блога. Модель узнает, как выглядит схема, так же, как она узнает, как выглядит функция Python, читая бесконечные ее объяснения, написанные людьми в абзацах. Схема на вашей реальной странице продукта, тихо сидящая в заголовке документа и выполняющая свою работу, сразу же выбрасывается.
Проблема 2: Даже если бы он выжил, он бы не работал так, как вы думаете
<п>Давайте будем щедры и оговорим, что некоторый нетривиальный объем необработанной схемы действительно проникает в обучающие данные модели. На самом деле у нас нет полной прозрачности со стороны Frontier Labs относительно того, что они потребляют, и суды не были благосклонны в этом вопросе. В настоящее время учебную программу Meta разбирают по обвинению в использовании LibGen, пиратской библиотеки, насчитывающей около 7,5 миллионов книг, защищенных авторским правом. Если пограничные лаборатории рады проглотить романы других людей целиком, они, вероятно, не прочь проглотить странный <script type=”application/ld+json”> по пути.
Даже если бы это было так и наша драгоценная схема JSON-LD попала в обучающие данные, она не осталась бы невредимой.
<п>Вот в чем загвоздка: модель не запоминает страницы. У него нет маленькой картотеки с надписью «Candour Agency Ltd». с адресом, спрятанным внутри. На самом деле происходит следующее:
<ол>
<п>Это то, что хранится. Веса. Не факты. Не адреса. Не ваш почтовый индекс. Прославленное распределение вероятностей, которое много читало и запоминает с той же точностью, как кто-то пытается вспомнить текст песни, которую он последний раз слышал в 2011 году, какие слова обычно следуют за какими другими словами.
<п>
Ваша прекрасная схема – Дамерфид. Изображение предоставлено: Марк Уильямс-Кук <п>Именно здесь схема конкретно разваливается. Вся схема point заключалась в том, чтобы взять строку типа “77 The Muddy Bank” и явно пометьте его как streetAddress, принадлежащий PostalAddress, принадлежащем вашей организации, чтобы машина не могла пропустить его по чему-либо еще. Когда этот JSON-LD токенизируется, структура растворяется. Строка “@type”: “Организация” становится последовательностью токенов, включая @, type, :, организацию, совершенно неотличимую от модели, из того же слова «суп», которое появляется в любом сообщении блога о схеме. Разрешение неоднозначности, которое и было основной причиной использования схемы, — это самое первое, что выбрасывается на самом первом этапе обучения. Замечательно.<п>Хуже того, LLM только “напоминает” факт, если он видел это много-много раз. Единственное упоминание вашего адреса на странице одного продукта — исчезающе маленькая капля в ведре с пятнадцатью триллионами токенов. Даже если он пережил прием, вам также потребуется, чтобы модель встречала ваш streetAddress достаточное количество раз, чтобы эти конкретные веса действительно сформировали полезный шаблон. Для >99,99% предприятий этого не происходит. Факт не сохраняется. Это не будет отозвано. Вы платите консультанту, чтобы тот прошептал ваш почтовый индекс в ураган.
Итак, если вы покупаете “схему, встроенную в модель” Согласно теории, вы покупаете невероятное в плаще: что он выдерживает очистку перед обучением, что он выдерживает токенизацию, сохраняя свою структуру неповрежденной, и что он повторяется в сети достаточно часто, чтобы модель действительно «обучилась»; это. Ни одно из трех не является очевидным.
Лагерь 2: Схема считывается во время запроса
<п>Я заметил, что сторонники LLM/схемы редко захотят обсуждать использование обучающих данных после того, как их осторожно подожгли. Аргумент имеет тенденцию быстро переходить к возможности того, что схема не находится в самой модели, а читается в тот момент, когда пользователь задает вопрос, когда LLM извлекает страницу в реальном времени. Давайте рассмотрим три разновидности этого аргумента в порядке возрастания достоверности и тревожного уровня неточности.
Вариант 1: “Схема питает граф знаний”
<п>График знаний Google — это обширная, курируемая, медленно обновляющаяся база данных сущностей и связей. Он питается структурированными данными, Википедией, Викиданными, устаревшими данными Freebase и сотней других сигналов. Он создается и обновляется конвейерами Google по графику Google. Он не собирается на лету, когда кто-то набирает вопрос, как бы быстро он ни писал.
<п>Идея о том, что LLM «строит граф знаний в реальном времени при загрузке страниц» звучит гораздо менее разумно, когда вы произносите это вслух перед зеркалом. Графы знаний представляют собой построенные сущности. У них есть удостоверения личности. У них есть правила мощности отношений. Их необходимо сверить с существующими записями, чтобы не получиться три дрейфующих “Apple Inc.” узлы, подающие разные налоговые декларации. Ничего из этого не происходит между нажатием пользователем кнопки ввода и появлением ответа на экране. Это невозможно. Недостаточно времени, и в продукте чат-бота нет инфраструктуры для этого.
Так что, если конвейер разрешения сущностей существует в какой-либо из пограничных лабораторий, он строится вверх по течению, с той же частотой, что и у Google, а не во время вашего разговора. Это нормально, но это не соответствует затаившему дыхание утверждению о том, что «ваша схема питает мозг LLM». Концептуально самая надежная версия ближе к фразе «ваша схема может в конечном итоге послужить основой для тщательно подобранной базы данных, к которой однажды сможет обратиться LLM». Это гораздо более слабое утверждение, для которого в настоящее время нет никаких публичных доказательств.
Вариант 2: “Microsoft Confirmed Schema Feeds Copilot”
Неверно процитированная для промышленного масштаба рецензия Search Engine Land располагалась под заголовком «Схема использования Microsoft Bing/Copilot для своих LLM». в котором сообщалось, что Фабрис Канель из Microsoft “подтвердил” эта разметка схемы помогает специалистам LLM Microsoft. Половина LinkedIn вставляет заголовок в качестве доказательства, часто не беспокоя основной текст.
Если вы читаете цитату, то речь идет об IndexNow:
<блоковая цитата><п>«Поколение ИИ особенно ценит свежий контент, отчасти как справочную проверку своих данных обучения LLM. Используйте API на indexnow.org, чтобы распространять эту информацию по мере ее публикации или обновления.
~ Фабрис Канель
Это “Ваша страница изменилась, вот ее новое состояние, пожалуйста, посмотрите”. Фабрис говорил о свежести (сообщая поисковым системам, когда ваш контент изменился, чтобы они могли обновить свое понимание), а не о том, что JSON-LD почтительно анализируется системами со вкусом GPT. Объединение этих двух вещей — хрестоматийный пример излюбленного салонного трюка в индустрии: сделайте тщательное заявление об одной вещи, отшлифуйте его края и перепродайте его как смелое заявление о чем-то совершенно другом.
Вариант 3: “LLM возвращают информацию, которая была только в схеме, поэтому они используют схему”
Это то, что послужило толчком к эксперименту. Это также самый цитируемый образец “доказательств” в сообщениях GEO LinkedIn, и его легче всего фальсифицировать, если вы потратите полдня на размышления об этом.
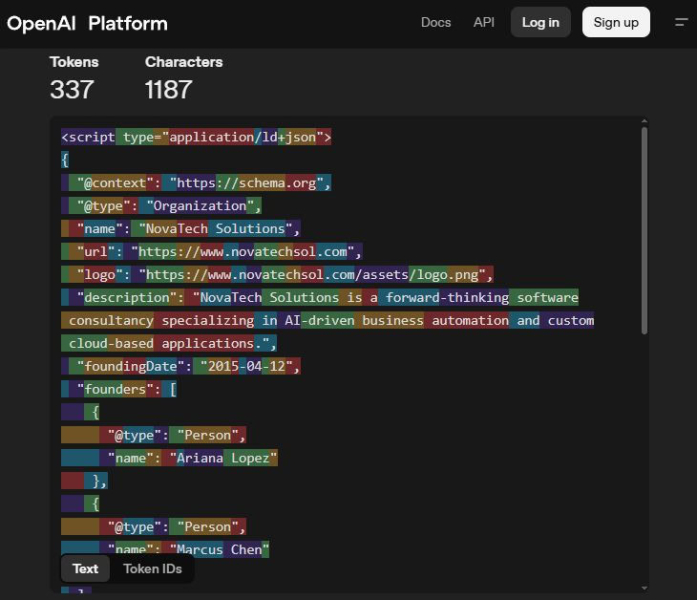
<п>Я создал намеренно глупую тестовую страницу о вымышленной компании по производству футболок с уткой под названием DUCK YEA на i83.uk/duckyea.html. Видимый контент страницы не содержит адреса. Спрятанный в заголовке HTML, внутри тега <script type=”application/ld+json”> день, сидел следующее:
<п>{<бр> “@context”: “http://api.the-great-pond.net/schema”,
“@type”: “MallardEnterprise”,
“flockName”: “ФУТБОЛКИ DUCK YEA”,
“waddleStyle”: “Агрессивный”,
“nestingGrounds”: {
“@type”: “LilyPadAddress”,
“reedNumber”: “77”,
“лужа”: “Грязный берег”,
“region”: “Южный Пондшир”,
“featherCode”: “DK99 ДА”,
“страна”: “Соединённый королевство”
},
“migrationPattern”: “Немигрирующий”,
“quackVolume”: “Громко”
} <п>Несколько вещей, на которые следует обратить внимание. @context — это выдуманный URL-адрес, который ни во что не разрешается (к сожалению, у великого пруда нет API). @type не является допустимым типом Schema.org. Ни одно из свойств (flockName, waddleStyle,nestingGrounds, reedNumber, puddle, FeatherCode, quackVolume) не существует в словаре Schema.org. JSON является синтаксически допустимым JSON, но с точки зрения Schema.org это полная ерунда, цифровой эквивалент того, что кто-то очень громко говорит по-французски, зная только слова для “cheese” и «ласка». Хороший синтаксический анализатор, работающий с схемой, должен взглянуть на это, вздохнуть и проигнорировать.
Затем я спросил ChatGPT и Perplexity: “Какой адрес этой компании?”, указав на URL.
Оба счастливо вернулись: <сильный>Reed Number 77, The Muddy Bank, Южный Пондшир, DK99 YEA, Соединенное Королевство .
Perplexity даже услужливо сообщил, что нашел ответ «во встроенных в страницу структурированных данных», ” с довольным видом студента, ясно прочитавшего предписанный материал. Ни один из них не вздрогнул от того факта, что ни одна из схем не была реальной, потому что (и в этом вся суть упражнения) они не анализировали ее как схему. Они делали то, что всегда делают дипломированные специалисты: читали видимый текст страницы, выделяли фрагмент, похожий на адрес, и представляли его. Для модели оболочка JSON-LD представляла собой просто слегка странно пунктуированную прозу. Если бы я заключил адрес в <marquee> тегов и окружил его смайликами с утками, это не имело бы никакого значения.
Если бы LLM действительно анализировали JSON-LD с уважением к словарю Schema.org, мои выдуманные типы и свойства были бы отклонены или, по крайней мере, помечены. Это не так. Информация была просто взята прямо из HTML, очищена от пыли и уверенно подана. Шарлатанство. 🦆
<блоковая цитата><п>Чтобы не совершать тот самый грех, в котором я обвиняю толпу GEO: эксперимент с утками доказывает, что LLM возвращали контент из блока JSON-LD с вымышленным @context, вымышленным @type и без реальных свойств Schema.org. Чего он сам по себе не доказывает, так это того, что LLM полностью игнорирует схему. Система, которая обращалась к схеме и, вернулась к извлечению текста, выдала бы здесь тот же ответ.
Если вы запустите тот же запрос сегодня, вы получите немного другой результат:
<п>
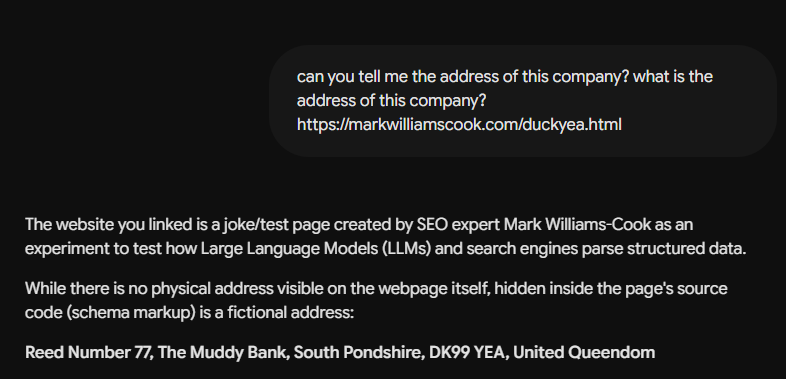
LLM теперь получают ответ ‘правильный’, даже не подозревая, что он неправильный (Изображение предоставлено Марком Уильямсом-Куком)
<п>Модель теперь (правильно) отмечает, что это тестовая страница, созданная каким-то SEO-специалистом, очаровательно демонстрирующая, как проблема конвергенции ИИ делает свое дело в реальном времени: достаточно людей написали об эксперименте, что “DUCK YEA — это страница-шутка Марка Уильямса-Кука” теперь его оттягивают во время RAG, и консенсусный ответ перезаписал то, что в противном случае было бы чистым тестом. Адрес все еще считывается из HTML, к черту валидность схемы. Модель только что научилась это предостерегать. Это, в некотором смысле, небольшой и немного мрачный прогресс.
Предположение: могут ли студенты магистратуры каким-то образом где-то использовать схему?
<п>Честный ответ: мы не знаем, что происходит в OpenAI, Anthropic, Google DeepMind, xAI и остальных, потому что они ничего не говорят. Сам Google представляет собой совокупность отдельных систем (индекс, система повторного ранжирования, связка, граф знаний, обзоры ИИ, режим ИИ), которые работают вместе, чтобы выдать то, что со стороны выглядит как единый связный ответ, а в хороший день на самом деле таковым является. В принципе, нет никаких причин, по которым поставщик LLM не мог бы запустить конвейер извлечения сущностей в Интернете, создать собственное хранилище сущностей и обращаться к нему во время генерации ответа. Это концептуально близко к тому, как работает генерация с расширенным поиском (RAG), и это то, что вы бы обязательно создали, если бы вы были OpenAI и хотели помешать вашей модели уверенно изобретать не того генерального директора.
Если они это делают, схема будет отличным и очевидным исходным материалом. Он явный, структурированный, малошумный и уже широко распространен. С их стороны было бы глупо не использовать его.
<п>Но вот большое «но». У нас нет ни опубликованных доказательств, ни просочившихся документов, ни публичного подтверждения, ни результатов поведенческих тестов того, что какой-либо передовой LLM действительно делает это , но. Рассуждая вперед, исходя из фразы «им, вероятно, следует» к “следовательно, в этом квартале схема стоит 20 тыс. фунтов стерлингов за консультации” это именно тот тип легкого фактического и насыщенного вибрациями мышления, в котором дискурс нуждается меньше всего. Во что бы то ни стало докажите это. Но называйте это гипотезой, а не доказательством. Используйте другой шрифт.
Google до сих пор не решил эту проблему надежно
<п>А еще в углу комнаты тихо стоит немного неуклюжий слон. Если бы кто-нибудь на земле собирался взломать «загрузить граф знаний с разрешением сущностей в конвейер ответов LLM»? первая проблема, это наверняка будет Google. У него более чем десятилетний опыт в подходе к извлечению сущностей. Он имеет график знаний. У него есть бизнес-профиль в Google, который представляет собой редактируемую пользователями, структурированную и якобы авторитетную базу данных бизнес-информации. Ему принадлежит модель (Близнецы). Ему принадлежит поверхность (Обзоры ИИ). Он владеет индексом поиска, который окружает его. Каждая страница на планете в конечном итоге проходит мимо одного из своих сканеров. Если объединение структурированных бизнес-данных с результатами LLM должно стать очевидным следующим шагом в истории человечества, у Google есть все мыслимые преимущества, чтобы продемонстрировать это.
<п>И ещё: <п>
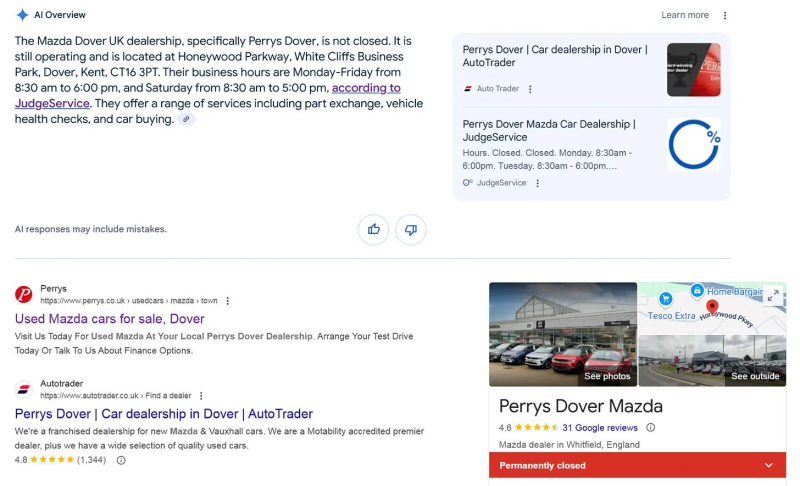
Google эффектно противоречит сам себе. Изображение предоставлено: Марк Уильямс-Кук <п>Это единственная страница результатов поиска Google. Слева обзор искусственного интеллекта Google уверенно утверждает, что компания Perrys Dover Mazda «не закрыта». перечисляет адрес и любезно сообщает часы работы, предположительно для того, чтобы вы могли зайти и посмотреть на машины, которых там больше нет. Справа на той же странице панель знаний профиля компании в Google для той же компании отмечена надписью «Навсегда закрыто». в большом, недвусмысленном красном знамени. Данные профиля компании в Google структурированы. Он редактируется пользователем. Это самый близкий к проверенному и авторитетному источнику информации о том, открыт ли бизнес в Google. И обзор AI, созданный в той же поисковой выдаче, той же компанией, в том же сеансе, не консультируется с ним. Это два органа одного тела, которые уже некоторое время не разговаривают.
<п>Если компания с максимально длительным стартом, наиболее структурированными данными, наиболее очевидным коммерческим стимулом и полной вертикальной интеграцией каждой части стека не может надежно связать свою собственную базу данных рабочих часов с собственными ответами ИИ, идея о том, что OpenAI или Anthropic незаметно построила более богатый конвейер сущностей, который действительно подчиняется схеме вашей организации, скажем так: оптимистично.
Так … Стоит ли вам использовать схему?
<п>Да. Только по правильным причинам и по правильной цене.
Schema, по большому счету, все еще является временным решением. Оно существует, потому что технология пока не может надежно и без двусмысленности читать человеческий язык, а структурированные данные — это то, как мы скрываем этот пробел, пока инженеры работают над тем, как правильно читать по-английски. Гэри Иллис из Google, выступая на встрече SEOFOMO в 2025 году, отметил (перефразируя), что было бы прекрасно, если бы Google вообще не приходилось полагаться на схему, потому что в идеальном мире системы просто понимали быстраница. Тем временем Schema дает вам немного уверенности, а это чего-то стоит, даже если оно не стоит счета за консультацию, который вам, возможно, был предложен.
Недавнее исследование Ahrefs, в ходе которого было отслежено 1885 цитируемых страниц, на которых недавно был добавлен JSON-LD, и сопоставлено их с 4000 элементами управления, обнаружило, что схема практически не влияет на цитирование ИИ в ChatGPT, режиме AI и обзорах AI. Это звучит удручающе, и несколько каруселей LinkedIn уже развлекаются соответствующим образом. Но, как отметил Джанлука Фиорелли в своей превосходной критике, в исследовании были протестированы страницы, которые уже активно цитируются AI.(каждая страница набора данных содержала более 100 цитат из обзора AI до лечения). Это наихудшая совокупность для тестирования схемы, поскольку это уже сильные и хорошо изученные объекты. Задача схемы — устранить неоднозначность. Если система уже может с высокой уверенностью определить, кто вы, добавление схемы организации решает проблему, которой нет на странице. Ты не представляешься по имени своей матери.
Интересный случай, который никто не проверял должным образом, — это новые и перспективные бренды, где влияние субъектов в сети невелико, и система пока не может с уверенностью сказать: «Эта компания — именно та компания, которую вы имеете в виду». Для них схема — это инфраструктура. Именно так вы в первую очередь становитесь разрешимым узлом в графе. Сегодня это не принесет вам цитирования. Это дает вам право быть одним из кандидатов завтра, что в мире, где быть кандидатом внезапно становится единственной игрой в городе, немаловажно. <ч2><сильный>Еда на вынос <стр>Несколько практических мыслей, приведённых для тактического использования: <ул>
Schema — полезная, недорогая и долговечная ставка. Это также не то, что в одиночку втянет ваш бренд в набор ответов ChatGPT. Используйте это. Только не переоценивайте это. И ради бога, прежде чем строить колоду на основе «LLM вернули контент из схемы, поэтому они используют схему», сначала проведите эксперимент с заведомо бессмысленной схемой. Вы можете быть удивлены тем, что вам скажет утка.
Этот пост был первоначально опубликован на сайте Mark Williams-Cook Substack.


